TiSpark (Beta) 用户指南
来源:SegmentFault
时间:2023-01-11 15:08:59 426浏览 收藏
大家好,今天本人给大家带来文章《TiSpark (Beta) 用户指南》,文中内容主要涉及到MySQL、github,如果你对数据库方面的知识点感兴趣,那就请各位朋友继续看下去吧~希望能真正帮到你们,谢谢!
TiSpark 是 PingCAP 推出的为了解决用户复杂 OLAP 需求的产品。借助 Spark 平台本身的优势,同时融合 TiKV 分布式集群的优势,和 TiDB 一起为用户一站式解决 HTAP (Hybrid Transactional/Analytical Processing)需求。 TiSpark 依赖 TiKV 集群和 PD 的存在。当然,TiSpark 也需要你搭建一个 Spark 集群。本文简单介绍如何部署和使用 TiSpark。本文假设你对 Spark 有基本认知。你可以参阅 Apache Spark 官网 了解 Spark 相关信息。
一、概述
TiSpark 是将 Spark SQL 直接运行在 TiDB 存储引擎 TiKV 上的 OLAP 解决方案。TiSpark 架构图如下:
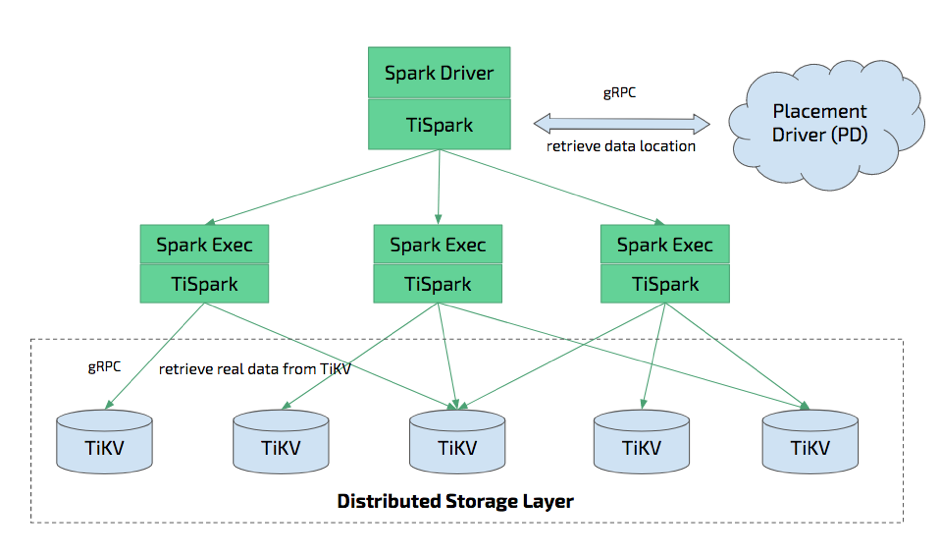
TiSpark 深度整合了 Spark Catalyst 引擎, 可以对计算提供精确的控制,使 Spark 能够高效的读取 TiKV 中的数据,提供索引支持以实现高速的点查;
通过多种计算下推减少 Spark SQL 需要处理的数据大小,以加速查询;利用 TiDB 的内建的统计信息选择更优的查询计划。
从数据集群的角度看,TiSpark + TiDB 可以让用户无需进行脆弱和难以维护的 ETL,直接在同一个平台进行事务和分析两种工作,简化了系统架构和运维。
除此之外,用户借助 TiSpark 项目可以在 TiDB 上使用 Spark 生态圈提供的多种工具进行数据处理。例如使用 TiSpark 进行数据分析和 ETL;使用 TiKV 作为机器学习的数据源;借助调度系统产生定时报表等等。
二、环境准备
现有 TiSpark 版本支持 Spark 2.1,对于 Spark 2.0 及 Spark 2.2 还没有经过良好的测试验证。对于更低版本暂时无法支持。
TiSpark 需要 JDK 1.8+ 以及 Scala 2.11(Spark2.0+ 默认 Scala 版本)。
TiSpark 可以在 YARN,Mesos,Standalone 等任意 Spark 模式下运行。
三 、推荐配置
3.1 部署 TiKV 和 TiSpark 集群
3.1.1 TiKV 集群部署配置
对于 TiKV 和 TiSpark 分开部署的场景,建议参考如下建议
硬件配置建议
普通场景可以参考 TiDB 和 TiKV 硬件配置建议,但是如果是偏重分析的场景,可以将 TiKV 节点增加到至少 64G 内存,如果是机械硬盘,则推荐 8 块。
TiKV 参数建议
[server] end-point-concurrency = 8 # 如果使用场景偏向分析,则可以考虑扩大这个参数 [raftstore] sync-log = false [rocksdb] max-background-compactions = 6 max-background-flushes = 2 [rocksdb.defaultcf] block-cache-size = "10GB" [rocksdb.writecf] block-cache-size = "4GB" [rocksdb.raftcf] block-cache-size = "1GB" [rocksdb.lockcf] block-cache-size = "1GB" [storage] scheduler-worker-pool-size = 4
3.1.2 Spark / TiSpark 集群独立部署配置
关于 Spark 的详细硬件推荐配置请参考官网,如下是根据 TiSpark 场景的简单阐述。
Spark 推荐 32G 内存以上配额。请在配置中预留 25% 的内存给操作系统。
Spark 推荐每台计算节点配备 CPU 累计 8 到 16 核以上。你可以初始设定分配所有 CPU 核给 Spark。
Spark 的具体配置方式也请参考官方说明。下面给出的是根据 spark-env.sh 配置的范例:
SPARK_EXECUTOR_MEMORY=32g
SPARK_WORKER_MEMORY=32g
SPARK_WORKER_CORES=8
3.1.3 TiSpark 与 TiKV 集群混合部署配置
对于 TiKV、TiSpark 混合部署场景,请在原有 TiKV 预留资源之外累加 Spark 所需部分并分配 25% 的内存作为系统本身占用。
四、部署 TiSpark
TiSpark 的 jar 包可以在这里下载。
4.1 已有 Spark 集群的部署方式
在已有 Spark 集群上运行 TiSpark 无需重启集群。可以使用 Spark 的 --jars 参数将 TiSpark 作为依赖引入:
spark-shell --jars $PATH/tispark-0.1.0.jar
如果想将 TiSpark 作为默认组件部署,只需要将 TiSpark 的 jar 包放进 Spark 集群每个节点的 jars 路径并重启 Spark 集群:
${SPARK_INSTALL_PATH}/jars
这样无论你是使用 Spark-Submit 还是 Spark-Shell 都可以直接使用 TiSpark。
4.2 没有 Spark 集群的部署方式
如果你没有使用中的 Spark 集群,我们推荐 Saprk Standalone 方式部署。我们在这里简单介绍下 Standalone 部署方式。如果遇到问题,你可以去官网寻找帮助;也欢迎在我们的 GitHub 上提 issue。
4.2.1 下载安装包并安装
你可以在这里下载 Apache Spark。
对于 Standalone 模式且无需 Hadoop 支持,请选择 Spark 2.1.x 且带有 Hadoop 依赖的 Pre-build with Apache Hadoop 2.x 任意版本。如你有需要配合使用的 Hadoop 集群,请选择对应的 Hadoop 版本号。你也可以选择从源代码自行构建以配合官方 Hadoop 2.6 之前的版本。请注意目前 TiSpark 仅支持 Spark 2.1.x 版本。
假设你已经有了 Spark 二进制文件,并且当前 PATH 为 SPARKPATH。
请将 TiSpark jar 包拷贝到
${SPARKPATH}/jars 目录下。
4.2.2 启动 Master
在选中的 Spark Master 节点执行如下命令:
cd $SPARKPATH ./sbin/start-master.sh
在这步完成以后,屏幕上会打印出一个 log 文件。检查 log 文件确认 Spark-Master 是否启动成功。 你可以打开 http://spark-master-hostname:8080 查看集群信息(如果你没有改动 Spark-Master 默认 Port Numebr)。在启动 Spark-Slave 的时候,你也可以通过这个面板来确认 Slave 是否已经加入集群。
4.2.3 启动 Slave
类似地,可以用如下命令启动 Spark-Slave节点:
./sbin/start-slave.sh spark://spark-master-hostname:7077
命令返回以后,你就可以通过刚才的面板查看这个 Slave 是否已经正确的加入了 Spark 集群。 在所有 Slave 节点重复刚才的命令。在确认所有的 Slave 都可以正确连接 Master,这样之后你就拥有了一个 Standalone 模式的 Spark 集群。
五、一个使用范例
假设你已经按照上述步骤成功启动了 TiSpark 集群, 下面简单介绍如何使用 Spark SQL 来做 OLAP 分析。这里我们用名为 tpch 数据库中的 lineitem 表作为范例。
在 Spark-Shell 里输入下面的命令, 假设你的 PD 节点位于 192.168.1.100,端口 2379:
import org.apache.spark.sql.TiContext
val ti = new TiContext(spark, List("192.168.1.100:2379")
ti.tidbMapDatabase("tpch")
之后你可以直接调用 Spark SQL
spark.sql("select count(*) from lineitem").show
结果为:
+-------------+ | count(1) | +-------------+ | 600000000 | +-------------+
六、FAQ
Q. 是独立部署还是和现有 Spark/Hadoop 集群共用资源?
A. 你可以利用现有 Spark 集群无需单独部署,但是如果现有集群繁忙,TiSpark 将无法达到理想速度。
Q. 是否可以和 TiKV 混合部署?
A. 如果 TiDB 以及 TiKV 负载较高且运行关键的线上任务,请考虑单独部署 TiSpark;并且考虑使用不同的网卡保证 OLTP 的网络资源不被侵占而影响线上业务。如果线上业务要求不高或者机器负载不大,可以考虑与 TiKV 混合部署。
文中关于mysql的知识介绍,希望对你的学习有所帮助!若是受益匪浅,那就动动鼠标收藏这篇《TiSpark (Beta) 用户指南》文章吧,也可关注golang学习网公众号了解相关技术文章。
-
499 收藏
-
244 收藏
-
235 收藏
-
157 收藏
-
101 收藏
-
数据库 · MySQL | 1天前 | 性能优化 · 执行计划 · MySQL教程 · 慢查询治理 · 数据库运维 · mysql GROUP BY优化 TempTable 内部临时表 Created_tmp_disk_tables267 收藏
-
数据库 · MySQL | 1天前 | 性能优化 · InnoDB · MySQL教程 · 数据库运维 · 高并发写入 · mysql innodb 批量写入 Change Buffer innodb_change_buffering270 收藏
-
数据库 · MySQL | 4天前 | 性能优化 · 高并发 · InnoDB · MySQL教程 · 数据库运维 · mysql innodb AUTO_INCREMENT 高并发写入 innodb_autoinc_lock_mode254 收藏
-
数据库 · MySQL | 4天前 | 连接池 · 高并发 · 故障排查 · MySQL教程 · 数据库运维 · mysql 高并发 连接池 max_connections Too many connections491 收藏
-
381 收藏
-
数据库 · MySQL | 5天前 | 性能优化 · InnoDB · 故障排查 · MySQL教程 · DBA实战 · mysql innodb 性能优化 预热 冷启动 MySQL 8.4 Buffer Pool158 收藏
-
数据库 · MySQL | 5天前 | binlog · 故障恢复 · 备份恢复 · MySQL教程 · DBA实战 · mysql DBA binlog 备份恢复 mysqlbinlog MySQL 8.4 PITR432 收藏
-
数据库 · MySQL | 5天前 | 字符集 · 故障排查 · MySQL教程 · 索引优化 · 排序规则 · mysql 排序规则 索引优化 utf8mb4 collation MySQL 8.4294 收藏
-
数据库 · MySQL | 5天前 | binlog · 主从复制 · 故障排查 · MySQL教程 · DBA实战 · mysql DBA binlog 主从复制 MySQL 8.4 复制延迟 relay log119 收藏
-
数据库 · MySQL | 5天前 | MySQL教程 · 慢查询治理 · 索引优化 · 分区表 · DBA实战 · mysql 分区表 慢查询 索引优化 MySQL 8.4 partition pruning133 收藏
-
数据库 · MySQL | 5天前 | 高并发 · 故障排查 · MySQL教程 · 事务隔离 · InnoDB锁 · mysql innodb 高并发 锁等待 MySQL 8.4 NOWAIT SKIP LOCKED439 收藏
-
291 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 积极的水蜜桃
- 很棒,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢up主分享技术贴!
- 2023-01-23 04:29:06
-
- 悦耳的蜜粉
- 这篇文章内容真及时,太全面了,赞 ??,已加入收藏夹了,关注作者大大了!希望作者大大能多写数据库相关的文章。
- 2023-01-16 20:19:44