深入理解跳表及其在Redis中的应用
来源:51cto
时间:2023-03-02 09:40:36 406浏览 收藏
本篇文章主要是结合我之前面试的各种经历和实战开发中遇到的问题解决经验整理的,希望这篇《深入理解跳表及其在Redis中的应用》对你有很大帮助!欢迎收藏,分享给更多的需要的朋友学习~
前言
跳表可以达到和红黑树一样的时间复杂度 O(logN),且实现简单,Redis 中的有序集合对象的底层数据结构就使用了跳表。其作者威廉·普评价:跳跃链表是在很多应用中有可能替代平衡树的一种数据结构。本篇文章将对跳表的实现及在Redis中的应用进行学习。
一. 跳表的基础概念
跳表,即跳跃链表(Skip List),是基于并联的链表数据结构,操作效率可以达到O(logN),对并发友好,跳表的示意图如下所示。
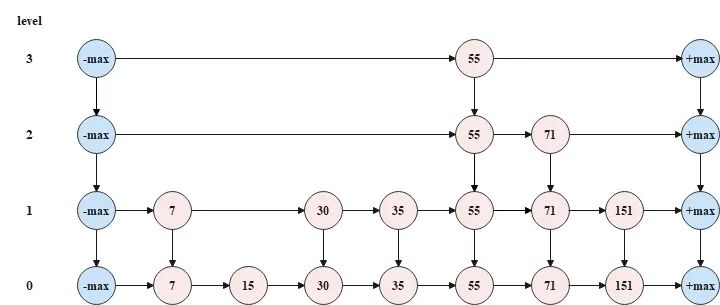
跳表的特点,可以概括如下。
•跳表是多层(level)链表结构;
•跳表中的每一层都是一个有序链表,并且按照元素升序(默认)排列;
•跳表中的元素会在哪一层出现是随机决定的,但是只要元素出现在了第 k 层,那么 k 层以下的链表也会出现这个元素;
•跳表的底层的链表包含所有元素;
•跳表头节点和尾节点不存储元素,且头节点和尾节点的层数就是跳表的最大层数;
•跳表中的节点包含两个指针,一个指针指向同层链表的后一节点,一个指针指向下层链表的同元素节点。
以上图中的跳表为例,如果要查找元素 71,那么查找流程如下图所示。
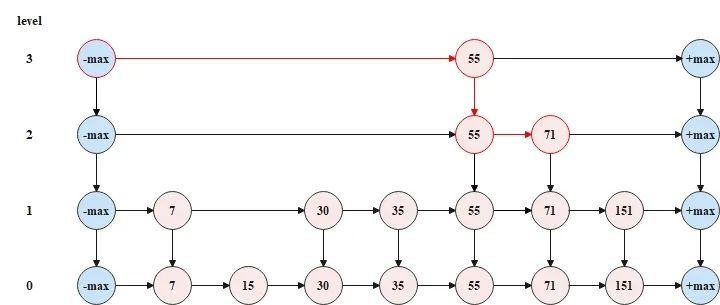
从顶层链表的头节点开始查找,查找到元素71的节点时,一共遍历了4个节点,但是如果按照传统链表的方式(即从跳表的底层链表的头节点开始向后查找),那么就需要遍历7个节点,所以跳表以空间换时间,缩短了操作跳表所需要花费的时间。跳跃列表的算法有同平衡树一样的渐进的预期时间边界,并且更简单、更快速和使用更少的空间。这种数据结构是由William Pugh(音译为威廉·普)发明的,最早出现于他在1990年发表的论文《Skip Lists: A Probabilistic Alternative to Balanced Trees》。 谷歌上找到一篇作者关于跳表的论文,感兴趣强烈建议下载阅读:
https://epaperpress.com/sortsearch/download/skiplist.pdf
跳表在动态查找过程中使用了一种非严格的平衡机制来让插入和删除都更加便利和快捷,这种非严格平衡是基于概率的,而不是平衡树的严格平衡。说到非严格平衡,首先想到的是红黑树RbTree,它同样采用非严格平衡来避免像AVL那样调整树的结构,这里就不展开讲红黑树了,看来跳表也是类似的路子,但是是基于概率实现的。
二. 跳表的节点
已知跳表中的节点,需要有指向当前层链表后一节点的指针,和指向下层链表的同元素节点的指针,所以跳表中的节点,定义如下。
public class SkiplistNode {
public int data;
public SkiplistNode next;
public SkiplistNode down;
public int level;
public SkiplistNode(int data, int level) {
this.data = data;
this.level = level;
}
上述是跳表中的节点的最简单的定义方式,存储的元素 data 为整数,节点之间进行比较时直接比较元素 data 的大小。
三. 跳表的初始化
跳表初始化时,将每一层链表的头尾节点创建出来并使用集合将头尾节点进行存储,头尾节点的层数随机指定,且头尾节点的层数就代表当前跳表的层数。初始化后,跳表结构如下所示。
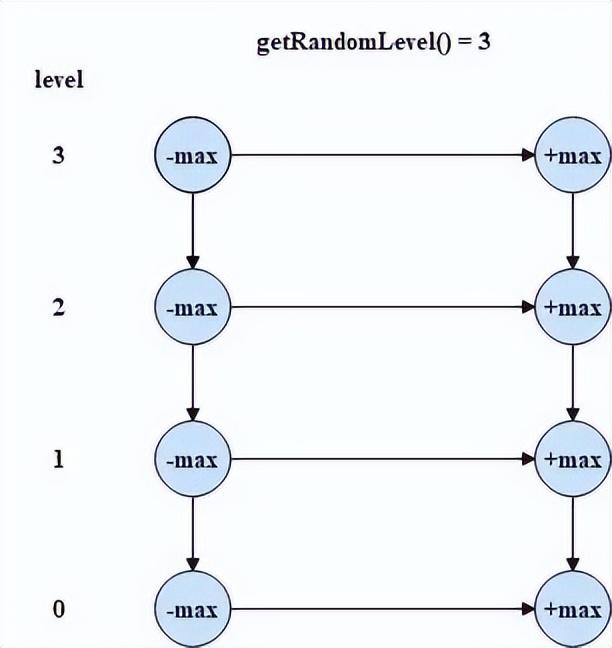
跳表初始化的相关代码如下所示。
public LinkedListSkiplistNode> headNodes; 每一个元素添加到跳表中时,首先需要随机指定这个元素在跳表中的层数,如果随机指定的层数大于了跳表的层数,则在将元素添加到跳表中之前,还需要扩大跳表的层数,而扩大跳表的层数就是将头尾节点的层数扩大。下面给出需要扩大跳表层数的一次添加的过程。 初始状态时,跳表的层数为 2,如下图所示。
public LinkedListSkiplistNode> tailNodes;
public int curLevel;
public Random random;
public Skiplist() {
random = new Random();
//headNodes用于存储每一层的头节点
headNodes = new LinkedList();
//tailNodes用于存储每一层的尾节点
tailNodes = new LinkedList();
//初始化跳表时,跳表的层数随机指定
curLevel = getRandomLevel();
//指定了跳表的初始的随机层数后,就需要将每一层的头节点和尾节点创建出来并构建好关系
SkiplistNode head = new SkiplistNode(Integer.MIN_VALUE, 0);
SkiplistNode tail = new SkiplistNode(Integer.MAX_VALUE, 0);
for (int i = 0; i curLevel; i++) {
head.next = tail;
headNodes.addFirst(head);
tailNodes.addFirst(tail);
SkiplistNode headNew = new SkiplistNode(Integer.MIN_VALUE, head.level + 1);
SkiplistNode tailNew = new SkiplistNode(Integer.MAX_VALUE, tail.level + 1);
headNew.down = head;
tailNew.down = tail;
head = headNew;
tail = tailNew;
}
}四. 跳表的添加方法
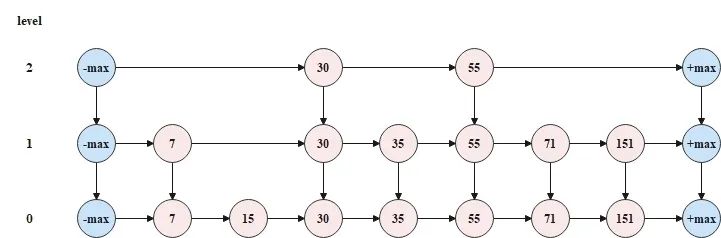
现在要往跳表中添加元素 120,并且随机指定的层数为 3,大于了当前跳表的层数 2,此时需要先扩大跳表的层数,2如 下图所示。
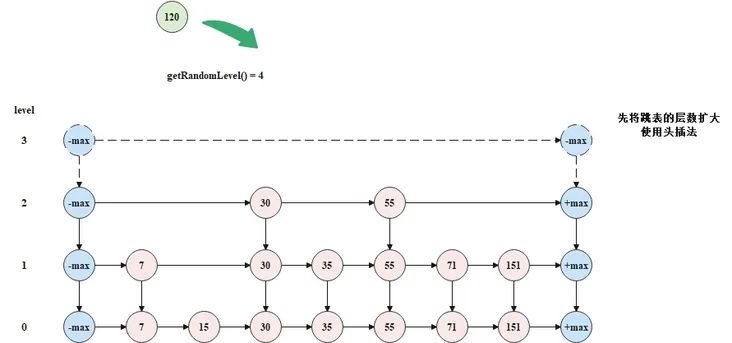
将元素 120 插入到跳表中时,从顶层开始,逐层向下插入,如下图所示。
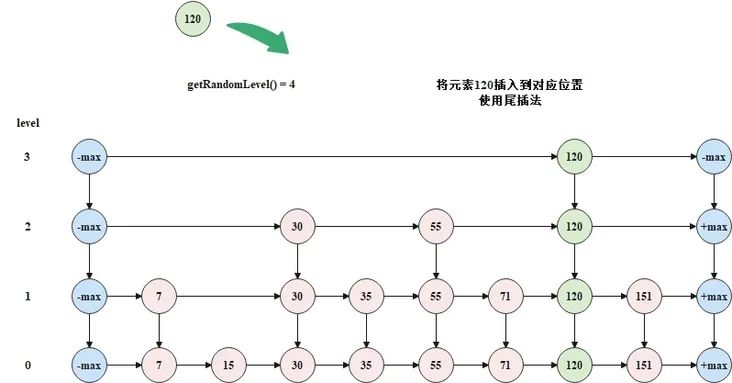
跳表的添加方法的代码如下所示。
public void add(int num) { 在跳表中搜索一个元素时,需要从顶层开始,逐层向下搜索。搜索时遵循如下规则。 •目标值大于当前节点的后一节点值时,继续在本层链表上向后搜索; •目标值大于当前节点值,小于当前节点的后一节点值时,向下移动一层,从下层链表的同节点位置向后搜索; •目标值等于当前节点值,搜索结束。 •下图是一个搜索过程的示意图。
//获取本次添加的值的层数
int level = getRandomLevel();
//如果本次添加的值的层数大于当前跳表的层数
//则需要在添加当前值前先将跳表层数扩充
if (level > curLevel) {
expanLevel(level - curLevel);
}
//curNode表示num值在当前层对应的节点
SkiplistNode curNode = new SkiplistNode(num, level);
//preNode表示curNode在当前层的前一个节点
SkiplistNode preNode = headNodes.get(curLevel - level);
for (int i = 0; i level; i++) {
//从当前层的head节点开始向后遍历,直到找到一个preNode
//使得preNode.data num preNode.next.data
while (preNode.next.data num) {
preNode = preNode.next;
}
//将curNode插入到preNode和preNode.next中间
curNode.next = preNode.next;
preNode.next = curNode;
//如果当前并不是0层,则继续向下层添加节点
if (curNode.level > 0) {
SkiplistNode downNode = new SkiplistNode(num, curNode.level - 1);
//curNode指向下一层的节点
curNode.down = downNode;
//curNode向下移动一层
curNode = downNode;
}
//preNode向下移动一层
preNode = preNode.down;
}
}
private void expanLevel(int expanCount) {
SkiplistNode head = headNodes.getFirst();
SkiplistNode tail = tailNodes.getFirst();
for (int i = 0; i expanCount; i++) {
SkiplistNode headNew = new SkiplistNode(Integer.MIN_VALUE, head.level + 1);
SkiplistNode tailNew = new SkiplistNode(Integer.MAX_VALUE, tail.level + 1);
headNew.down = head;
tailNew.down = tail;
head = headNew;
tail = tailNew;
headNodes.addFirst(head);
tailNodes.addFirst(tail);
}
}五. 跳表的搜索方法
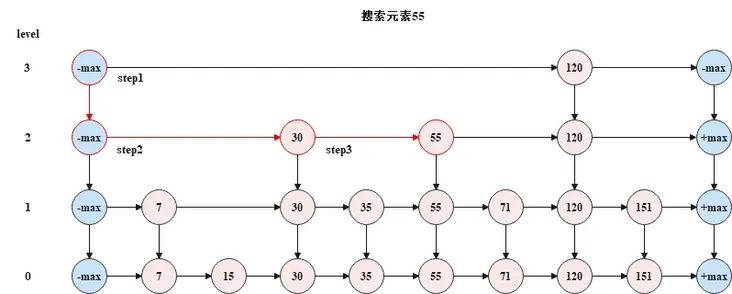
•跳表的搜索的代码如下所示。
public boolean search(int target) {
//从顶层开始寻找,curNode表示当前遍历到的节点
SkiplistNode curNode = headNodes.getFirst();
while (curNode != null) {
if (curNode.next.data == target) {
//找到了目标值对应的节点,此时返回true
return true;
} else if (curNode.next.data > target) {
//curNode的后一节点值大于target
//说明目标节点在curNode和curNode.next之间
//此时需要向下层寻找
curNode = curNode.down;
} else {
//curNode的后一节点值小于target
//说明目标节点在curNode的后一节点的后面
//此时在本层继续向后寻找
curNode = curNode.next;
}
}
return false;
}
六. 跳表的删除方法
当在跳表中需要删除某一个元素时,则需要将这个元素在所有层的节点都删除,具体的删除规则如下所示。
•首先按照跳表的搜索的方式,搜索待删除节点,如果能够搜索到,此时搜索到的待删除节点位于该节点层数的最高层;
•从待删除节点的最高层往下,将每一层的待删除节点都删除掉,删除方式就是让待删除节点的前一节点直接指向待删除节点的后一节点。
•下图是一个删除过程的示意图。
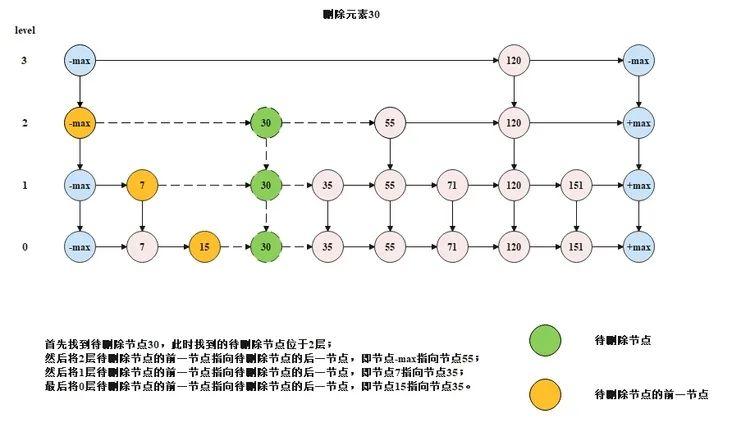
•跳表的删除的代码如下所示。
public boolean erase(int num) {
//删除节点的遍历过程与寻找节点的遍历过程是相同的
//不过在删除节点时如果找到目标节点,则需要执行节点删除的操作
SkiplistNode curNode = headNodes.getFirst();
while (curNode != null) {
if (curNode.next.data == num) {
//preDeleteNode表示待删除节点的前一节点
SkiplistNode preDeleteNode = curNode;
while (true) {
//删除当前层的待删除节点,就是让待删除节点的前一节点指向待删除节点的后一节点
preDeleteNode.next = curNode.next.next;
//当前层删除完后,需要继续删除下一层的待删除节点
//这里让preDeleteNode向下移动一层
//向下移动一层后,preDeleteNode就不一定是待删除节点的前一节点了
preDeleteNode = preDeleteNode.down;
//如果preDeleteNode为null,说明已经将底层的待删除节点删除了
//此时就结束删除流程,并返回true
if (preDeleteNode == null) {
return true;
}
//preDeleteNode向下移动一层后,需要继续从当前位置向后遍历
//直到找到一个preDeleteNode,使得preDeleteNode.next的值等于目标值
//此时preDeleteNode就又变成了待删除节点的前一节点
while (preDeleteNode.next.data != num) {
preDeleteNode = preDeleteNode.next;
}
}
} else if (curNode.next.data > num) {
curNode = curNode.down;
} else {
curNode = curNode.next;
}
}
return false;
}
七. 跳表完整代码
跳表完整代码如下所示。
public class Skiplist { ZSet结构同时包含一个字典和一个跳跃表,跳跃表按score从小到大保存所有集合元素。字典保存着从member到score的映射。这两种结构通过指针共享相同元素的member和score,不会浪费额外内存。 typedef struct zset { ZSet中的字典和跳表布局:
public LinkedListSkiplistNode> headNodes;
public LinkedListSkiplistNode> tailNodes;
public int curLevel;
public Random random;
public Skiplist() {
random = new Random();
//headNodes用于存储每一层的头节点
headNodes = new LinkedList();
//tailNodes用于存储每一层的尾节点
tailNodes = new LinkedList();
//初始化跳表时,跳表的层数随机指定
curLevel = getRandomLevel();
//指定了跳表的初始的随机层数后,就需要将每一层的头节点和尾节点创建出来并构建好关系
SkiplistNode head = new SkiplistNode(Integer.MIN_VALUE, 0);
SkiplistNode tail = new SkiplistNode(Integer.MAX_VALUE, 0);
for (int i = 0; i curLevel; i++) {
head.next = tail;
headNodes.addFirst(head);
tailNodes.addFirst(tail);
SkiplistNode headNew = new SkiplistNode(Integer.MIN_VALUE, head.level + 1);
SkiplistNode tailNew = new SkiplistNode(Integer.MAX_VALUE, tail.level + 1);
headNew.down = head;
tailNew.down = tail;
head = headNew;
tail = tailNew;
}
}
public boolean search(int target) {
//从顶层开始寻找,curNode表示当前遍历到的节点
SkiplistNode curNode = headNodes.getFirst();
while (curNode != null) {
if (curNode.next.data == target) {
//找到了目标值对应的节点,此时返回true
return true;
} else if (curNode.next.data > target) {
//curNode的后一节点值大于target
//说明目标节点在curNode和curNode.next之间
//此时需要向下层寻找
curNode = curNode.down;
} else {
//curNode的后一节点值小于target
//说明目标节点在curNode的后一节点的后面
//此时在本层继续向后寻找
curNode = curNode.next;
}
}
return false;
}
public void add(int num) {
//获取本次添加的值的层数
int level = getRandomLevel();
//如果本次添加的值的层数大于当前跳表的层数
//则需要在添加当前值前先将跳表层数扩充
if (level > curLevel) {
expanLevel(level - curLevel);
}
//curNode表示num值在当前层对应的节点
SkiplistNode curNode = new SkiplistNode(num, level);
//preNode表示curNode在当前层的前一个节点
SkiplistNode preNode = headNodes.get(curLevel - level);
for (int i = 0; i level; i++) {
//从当前层的head节点开始向后遍历,直到找到一个preNode
//使得preNode.data num preNode.next.data
while (preNode.next.data num) {
preNode = preNode.next;
}
//将curNode插入到preNode和preNode.next中间
curNode.next = preNode.next;
preNode.next = curNode;
//如果当前并不是0层,则继续向下层添加节点
if (curNode.level > 0) {
SkiplistNode downNode = new SkiplistNode(num, curNode.level - 1);
//curNode指向下一层的节点
curNode.down = downNode;
//curNode向下移动一层
curNode = downNode;
}
//preNode向下移动一层
preNode = preNode.down;
}
}
public boolean erase(int num) {
//删除节点的遍历过程与寻找节点的遍历过程是相同的
//不过在删除节点时如果找到目标节点,则需要执行节点删除的操作
SkiplistNode curNode = headNodes.getFirst();
while (curNode != null) {
if (curNode.next.data == num) {
//preDeleteNode表示待删除节点的前一节点
SkiplistNode preDeleteNode = curNode;
while (true) {
//删除当前层的待删除节点,就是让待删除节点的前一节点指向待删除节点的后一节点
preDeleteNode.next = curNode.next.next;
//当前层删除完后,需要继续删除下一层的待删除节点
//这里让preDeleteNode向下移动一层
//向下移动一层后,preDeleteNode就不一定是待删除节点的前一节点了
preDeleteNode = preDeleteNode.down;
//如果preDeleteNode为null,说明已经将底层的待删除节点删除了
//此时就结束删除流程,并返回true
if (preDeleteNode == null) {
return true;
}
//preDeleteNode向下移动一层后,需要继续从当前位置向后遍历
//直到找到一个preDeleteNode,使得preDeleteNode.next的值等于目标值
//此时preDeleteNode就又变成了待删除节点的前一节点
while (preDeleteNode.next.data != num) {
preDeleteNode = preDeleteNode.next;
}
}
} else if (curNode.next.data > num) {
curNode = curNode.down;
} else {
curNode = curNode.next;
}
}
return false;
}
private void expanLevel(int expanCount) {
SkiplistNode head = headNodes.getFirst();
SkiplistNode tail = tailNodes.getFirst();
for (int i = 0; i expanCount; i++) {
SkiplistNode headNew = new SkiplistNode(Integer.MIN_VALUE, head.level + 1);
SkiplistNode tailNew = new SkiplistNode(Integer.MAX_VALUE, tail.level + 1);
headNew.down = head;
tailNew.down = tail;
head = headNew;
tail = tailNew;
headNodes.addFirst(head);
tailNodes.addFirst(tail);
}
}
private int getRandomLevel() {
int level = 0;
while (random.nextInt(2) > 1) {
level++;
}
return level;
}
}八. 跳表在Redis中的应用
dict *dict;
zskiplist *zsl;
} zset;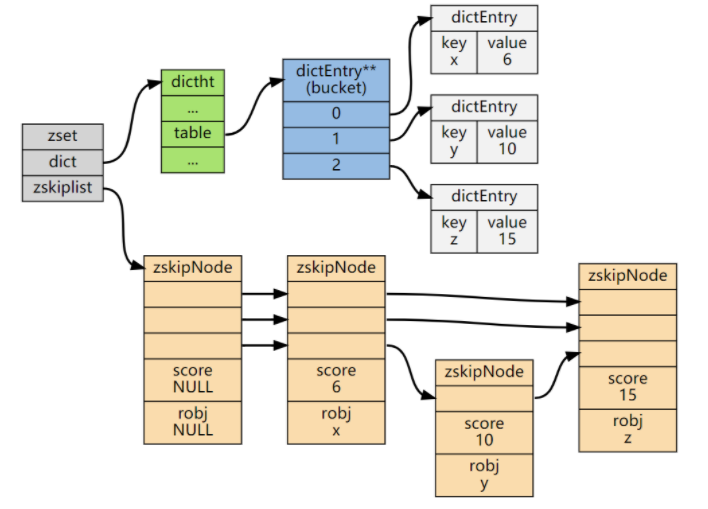
1.ZSet中跳表的实现细节
随机层数的实现原理:
跳表是一个概率型的数据结构,元素的插入层数是随机指定的。Willam Pugh在论文中描述了它的计算过程如下:指定节点最大层数 MaxLevel,指定概率 p, 默认层数 lvl 为1;
生成一个0~1的随机数r,若r
重复第 2 步,直至生成的r >p 为止,此时的 lvl 就是要插入的层数。
论文中生成随机层数的伪码:
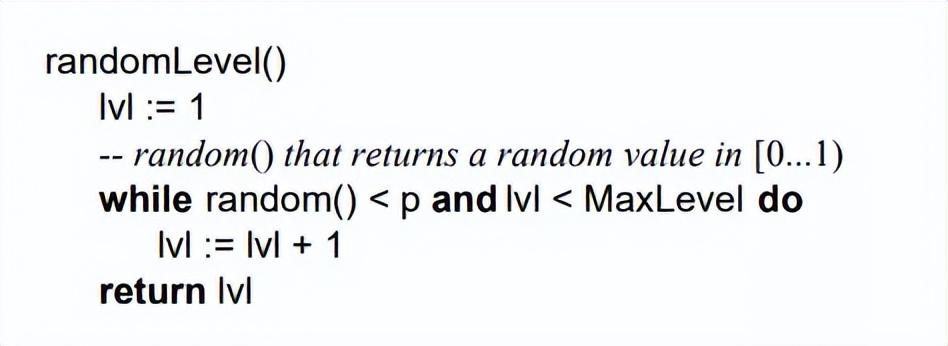
在Redis中对跳表的实现基本上也是遵循这个思想的,只不过有微小差异,看下Redis关于跳表层数的随机源码src/z_set.c:
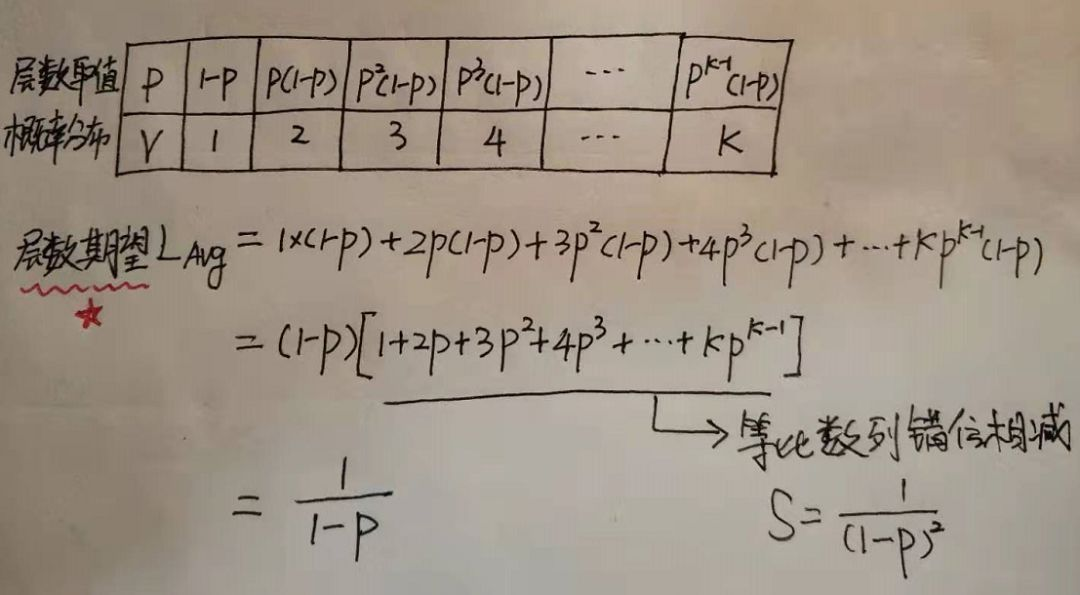
/* Returns a random level for the new skiplist node we are going to create. 其中两个宏的定义在redis.h中: #define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^32 elements */ 可以看到while中的: (random()&0xFFFF) (ZSKIPLIST_P*0xFFFF) 第一眼看到这个公式,因为涉及位运算有些诧异,需要研究一下Antirez为什么使用位运算来这么写? 最开始的猜测是random()返回的是浮点数[0-1],于是乎在线找了个浮点数转二进制的工具,输入0.5看了下结果: 可以看到0.5的32bit转换16进制结果为0x3f000000,如果与0xFFFF做与运算结果还是0,不符合预期。 实际应用时对于随机层数的实现并不统一,重要的是随机数的生成,在LevelDB中对跳表层数的生成代码是这样的: template typename Key, typename Value> 可以看到leveldb使用随机数与kBranching取模,如果值为0就增加一层,这样虽然没有使用浮点数,但是也实现了概率平衡。 我们很容易看出,产生越高的节点层数出现概率越低,无论如何层数总是满足幂次定律越大的数出现的概率越小。 如果某件事的发生频率和它的某个属性成幂关系,那么这个频率就可以称之为符合幂次定律。 幂次定律的表现是少数几个事件的发生频率占了整个发生频率的大部分, 而其余的大多数事件只占整个发生频率的一个小部分。 幂次定律应用到跳表的随机层数来说就是大部分的节点层数都是黄色部分,只有少数是绿色部分,并且概率很低。 定量的分析如下: •节点层数至少为1,大于1的节点层数满足一个概率分布。 •节点层数恰好等于1的概率为p^0(1-p) •节点层数恰好等于2的概率为p^1(1-p) •节点层数恰好等于3的概率为p^2(1-p) •节点层数恰好等于4的概率为p^3(1-p) 依次递推节点层数恰好等于K的概率为p^(k-1)(1-p) 因此如果我们要求节点的平均层数,那么也就转换成了求概率分布的期望问题了: 表中P为概率,V为对应取值,给出了所有取值和概率的可能,因此就可以求这个概率分布的期望了。方括号里面的式子其实就是高一年级学的等比数列,常用技巧错位相减求和,从中可以看到结点层数的期望值与1-p成反比。对于Redis而言,当p=0.25时结点层数的期望是1.33。 跳表的时间复杂度与AVL树和红黑树相同,可以达到O(logN),但是AVL树要维持高度的平衡,红黑树要维持高度的近似平衡,这都会导致插入或者删除节点时的一些时间开销,所以跳表相较于AVL树和红黑树来说,省去了维持高度的平衡的时间开销,但是相应的也付出了更多的空间来存储多个层的节点,所以跳表是用空间换时间的数据结构。以Redis中底层的数据结构zset作为典型应用来展开,进一步看到跳跃链表的实际应用。 好了,本文到此结束,带大家了解了《深入理解跳表及其在Redis中的应用》,希望本文对你有所帮助!关注golang学习网公众号,给大家分享更多数据库知识!
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned. */
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (levelZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
int SkipListKey, Value>::randomLevel() {
static const unsigned int kBranching = 4;
int height = 1;
while (height kMaxLevel && ((::Next(rnd_) % kBranching) == 0)) {
height++;
}
assert(height > 0);
assert(height kMaxLevel);
return height;
}
uint32_t Next( uint32_t& seed) {
seed = seed & 0x7fffffffu;
if (seed == 0 || seed == 2147483647L) {
seed = 1;
}
static const uint32_t M = 2147483647L;
static const uint64_t A = 16807;
uint64_t product = seed * A;
seed = static_castuint32_t>((product >> 31) + (product & M));
if (seed > M) {
seed -= M;
}
return seed;
}2.跳表结点的平均层数
总结
-
117 收藏
-
426 收藏
-
171 收藏
-
113 收藏
-
195 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 落寞的大象
- 这篇技术贴出现的刚刚好,细节满满,很有用,收藏了,关注博主了!希望博主能多写数据库相关的文章。
- 2023-04-17 05:20:26