电脑怎么查CPU温度?一文讲清
时间:2025-07-24 20:54:32 403浏览 收藏
本篇文章给大家分享《电脑如何查看CPU温度?一文讲清》,覆盖了文章的常见基础知识,其实一个语言的全部知识点一篇文章是不可能说完的,但希望通过这些问题,让读者对自己的掌握程度有一定的认识(B 数),从而弥补自己的不足,更好的掌握它。
在日常使用计算机的过程中,CPU温度是一项关键的性能指标,尤其对游戏玩家、视频编辑人员以及超频用户而言,实时掌握CPU温度有助于避免因过热引发的性能下降或硬件故障。那么,我们该如何查看CPU温度呢?本文将为你详细介绍几种实用的查看方法,并提供有效的降温建议。

一、通过BIOS查看CPU温度
BIOS(基本输入输出系统)是电脑启动时运行的底层程序,通常能显示包括CPU温度在内的硬件状态信息。
操作步骤如下:
- 重启电脑,在开机自检阶段持续按下F2、F10或Delete键(具体按键因品牌而异);
- 成功进入BIOS界面后,查找“Hardware Monitor”、“PC Health Status”或类似选项;
- 在该页面中,即可查看当前CPU温度、风扇转速等实时数据。
局限性:每次查看都需要重启系统,无法实现持续监控,适合偶尔检查使用。
二、利用Windows任务管理器查看CPU温度
虽然Windows系统本身不直接提供温度显示功能,但部分较新版本的系统可通过任务管理器间接获取CPU温度信息(依赖硬件支持)。
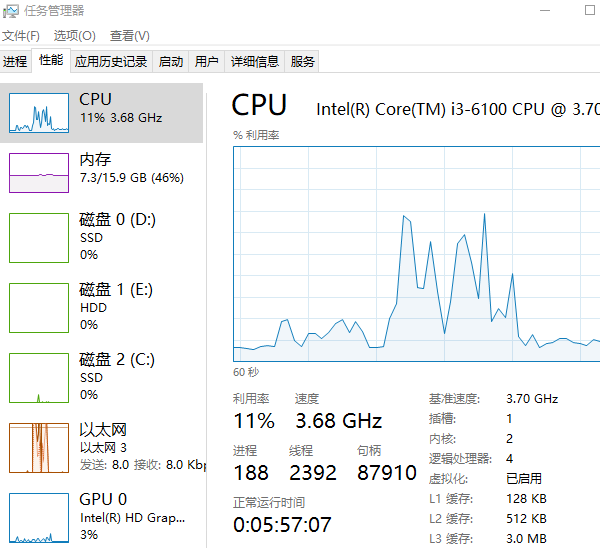
- 按下组合键 Ctrl + Shift + Esc 打开任务管理器;
- 切换至“性能”选项卡,点击“CPU”,部分设备会在此显示温度数值。
三、借助第三方软件监测CPU温度
相比系统自带工具,第三方软件功能更全面,支持实时监控和历史数据记录。例如,使用“驱动人生”这类硬件管理工具,即可轻松查看CPU及其他核心部件的运行状态。
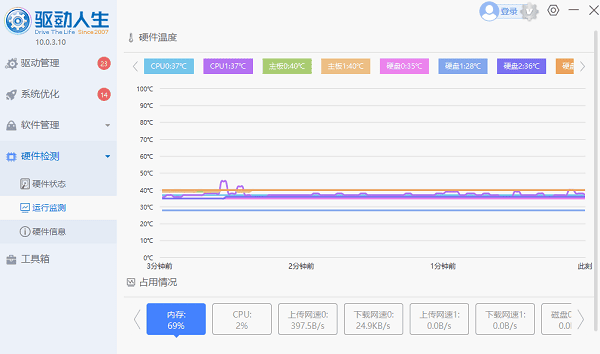
- 启动驱动人生软件,进入“运行监测”功能模块;
- 在主界面中可实时查看CPU温度、主板温度、硬盘温度等关键参数。
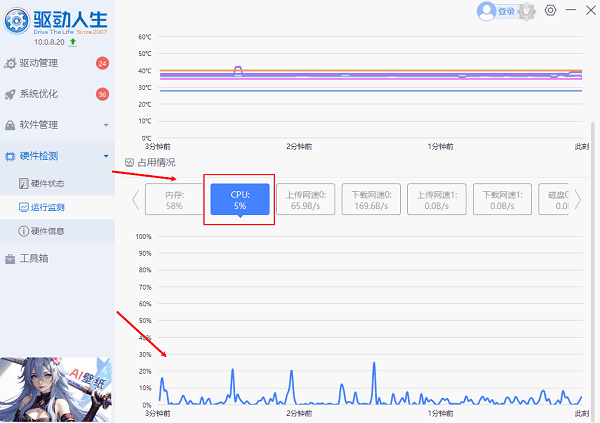
- 向下滚动页面,还能查看CPU占用率的动态曲线图,并同步了解内存、显卡等硬件的使用情况。
四、CPU温度的正常范围
不同使用场景下,CPU温度会有所波动,以下是常见的参考标准:
- 空闲状态:30°C – 50°C
- 中等使用(如浏览网页、文档处理):50°C – 70°C
- 高负载运行(如游戏、视频渲染):70°C – 85°C
- 危险区间:超过90°C,可能触发自动降频或关机保护
若CPU长期运行在80°C以上,建议及时排查散热问题。
五、有效降低CPU温度的方法
定期清灰:机箱内部、散热器及风扇积聚的灰尘会影响散热效率,建议每3到6个月进行一次清洁。
更换导热硅脂:CPU与散热器之间的导热介质会随时间老化,更换优质硅脂(如液态金属)可显著提升导热效果。
增强散热系统:加装机箱风扇、升级风冷散热器或改用水冷方案,有助于提升整体散热能力。

调节风扇转速:通过BIOS或专用软件设置风扇曲线,提高转速以加强散热。
减少CPU负载:关闭不必要的后台程序,避免CPU长时间满载运行。
- 优化电源模式:在Windows电源选项中选择“平衡”模式,合理控制CPU功耗与发热。
好了,本文到此结束,带大家了解了《电脑怎么查CPU温度?一文讲清》,希望本文对你有所帮助!关注golang学习网公众号,给大家分享更多文章知识!

-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
391 收藏
-
378 收藏
-
117 收藏
-
122 收藏
-
195 收藏
-
348 收藏
-
191 收藏
-
468 收藏
-
217 收藏
-
126 收藏
-
374 收藏
-
357 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习