电脑卡顿怎么清理?3个技巧快速提速!
时间:2025-07-30 15:33:31 263浏览 收藏
电脑卡顿是许多用户都头疼的问题,别急着重装系统!本文为你提供3个实用技巧,帮你快速提升电脑速度。首先,定期清理磁盘垃圾,释放宝贵的磁盘空间。其次,卸载不常用的软件,关闭不必要的开机启动项,减少系统资源占用。最后,如果你觉得手动清理太麻烦,不妨试试“百贝C盘助手”,这款专业的C盘清理工具,集垃圾清理、重复文件扫描、文件搬家等功能于一体,智能识别并清理微信、QQ等常用应用的缓存文件,一键操作,省时省力,让你的电脑焕然一新,告别卡顿烦恼!
电脑使用时间久了,难免会出现卡顿、运行缓慢等问题,影响工作和娱乐体验。很多人第一反应是重装系统,但实际上,通过合理的系统优化和清理,同样可以让电脑恢复流畅。下面分享几种彻底清理电脑的有效方法,帮助你显著提升系统性能。

1. 清理磁盘垃圾
Windows系统在日常运行中会产生大量临时文件、缓存和日志,长期积累会占用大量磁盘空间,拖慢系统速度。建议定期进行磁盘清理:
使用系统自带的磁盘清理工具(以Windows 11为例):
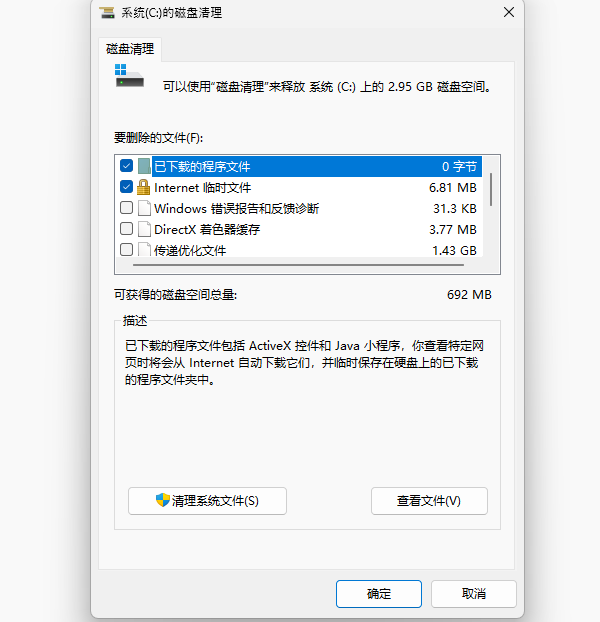
在任务栏搜索框中输入“磁盘清理”,点击进入程序。
选择需要清理的项目(如临时文件、回收站、系统日志等),确认后点击“确定”即可完成清理。
手动清理临时文件:
按下 Win + R 键,输入 %temp% 并回车,打开临时文件目录。
选中所有可删除的文件并清除(部分正在使用的文件无法删除,可跳过)。
2. 卸载无用软件
很多软件不仅占用硬盘空间,还会在后台运行或设置开机自启,消耗系统资源。建议:
进入 控制面板 → 程序和功能,卸载长期未使用的应用程序。
打开 任务管理器(Ctrl+Shift+Esc),切换到“启动”选项卡,禁用不必要的开机启动项,加快系统启动速度。
3. 使用「百贝C盘助手」智能清理
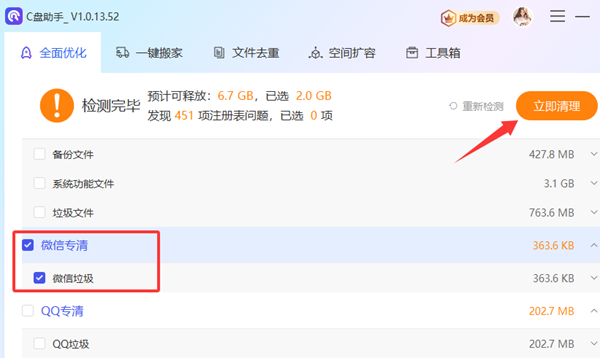
百贝C盘助手是一款专业且高效的C盘清理工具,操作简单、安全可靠,集 垃圾清理、重复文件扫描、文件搬家、磁盘扩容、微信专清、QQ专清 等功能于一体,帮助用户轻松释放磁盘空间。
启动软件后,它会自动识别系统中的微信缓存、临时文件等冗余数据。
默认勾选的清理项均为安全项目,不会影响系统正常运行,有效避免误删风险。
此外,软件还提供针对微信、QQ、视频平台等常用应用的专项清理功能,分类清晰,一键操作,省心又高效。
电脑变卡往往是因为系统垃圾堆积所致。通过定期清理和合理优化,完全可以恢复流畅体验。建议养成良好的维护习惯,避免问题积累。如果觉得手动清理繁琐,推荐使用百贝C盘助手,一键扫描、智能清理,更省时省力。
今天关于《电脑卡顿怎么清理?3个技巧快速提速!》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于的内容请关注golang学习网公众号!
-
文章 · 软件教程 | 1天前 | go · vs code · 软件教程 · 测试任务 · tasks.json · VS Code 测试任务 终端输出 Go插件 Go测试 tasks.json 问题面板501 收藏
-
284 收藏
-
文章 · 软件教程 | 2天前 | 开发工具 · vs code · profiles · 软件教程 · 配置同步 · 软件教程 Visual Studio Code VS Code Profiles 配置档 导出配置 导入配置185 收藏
-
文章 · 软件教程 | 2天前 | 开发环境 · windows terminal · 软件教程 · 终端工具 · Ubuntu PowerShell 软件教程 Windows Terminal 默认配置文件 起始路径495 收藏
-
文章 · 软件教程 | 2天前 | Windows · 软件教程 · PowerToys · PowerRename · 批量重命名 · PowerToys 批量重命名 软件教程 PowerRename Windows重命名 文件改名413 收藏
-
217 收藏
-
486 收藏
-
文章 · 软件教程 | 1星期前 | 环境变量 · postman · 软件教程 · 接口测试 · 导入导出 · 环境变量 Collection JSON文件 导入导出 Postman Environment 接口集合308 收藏
-
文章 · 软件教程 | 1星期前 | PNG · diagrams.net · 软件教程 · draw.io · 流程图 · 透明背景 流程图 软件教程 Diagrams.net PNG导出 draw.io 图片归档130 收藏
-
文章 · 软件教程 | 1星期前 | 版本控制 · source control · 软件教程 · VS Code教程 · Git冲突 · VS Code 软件教程 Git冲突 Source Control Merge Editor 提交核对395 收藏
-
文章 · 软件教程 | 1星期前 | network · Har · 软件教程 · Chrome DevTools · 前端调试 · 软件教程 Chrome DevTools HAR文件 Network面板 前端排查410 收藏
-
文章 · 软件教程 | 1星期前 | 开发工具 · vs code · 软件教程 · 设置排错 · VS Code 搜索排除 search.exclude files.exclude Use Exclude Settings256 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习