本地部署大模型测试,DeepSeek-R1性能依然出色
时间:2025-08-17 13:54:41 142浏览 收藏
欢迎各位小伙伴来到golang学习网,相聚于此都是缘哈哈哈!今天我给大家带来《本地部署大模型测试,DeepSeek-R1-0528-Qwen-8B 性能依旧强劲》,这篇文章主要讲到等等知识,如果你对文章相关的知识非常感兴趣或者正在自学,都可以关注我,我会持续更新相关文章!当然,有什么建议也欢迎在评论留言提出!一起学习!
 图片大家好,我是 ai 学习的老章
图片大家好,我是 ai 学习的老章
今天分享一个我最近频繁使用的大模型并发压力测试工具,并实测一下我在双 4090 显卡上本地部署的 DeepSeek-R1-0528-Qwen-8B 模型的实际表现。
这是我目前最钟爱的三个 DeepSeek 蒸馏版本之一
DeepSeek-R1-0528 基于 Qwen3:8B 进行知识蒸馏优化,配合双 4090 实现本地高效推理,性能与效果兼备,深得我心
LLM-Benchmark 工具介绍
项目地址:https://github.com/lework/llm-benchmark
LLM-Benchmark 是一款专为大语言模型设计的自动化并发性能压测工具,适用于开发者和运维人员对本地或远程 LLM 服务进行系统性性能评估。它支持从低负载到高并发的多阶段测试,帮助定位瓶颈、优化部署策略。
核心功能亮点:
- 多阶段压力测试:支持从 1 到 300 并发逐步加压,观察模型在不同负载下的表现。
- 自动化数据采集:自动记录每轮测试的响应时间、吞吐量、错误率等关键指标。
- 可视化性能报告:生成结构化报告,直观展示 RPS、延迟、TPS 等趋势变化。
- 长短文本双模式测试:覆盖短问答与长上下文生成场景,贴近真实应用。
- 高度可配置:通过命令行灵活设置模型名、URL、并发数、请求数等参数。
- JSON 输出支持:便于后续分析或集成至 CI/CD 流程。
主要文件说明:
run_benchmarks.py:主测试脚本,执行全量多轮测试,自动生成汇总报告。
llm_benchmark.py:核心压测逻辑,处理并发请求、连接池管理及流式响应测试。
assets/:存放测试用资源文件。
README.md:详细使用文档与参数说明。
使用方式
1. 执行完整性能测试(推荐)
运行以下命令进行全量多并发测试,适合全面评估模型服务能力:
python run_benchmarks.py \ --llm_url "http://your-llm-server" \ --api_key "your-api-key" \ --model "your-model-name" \ --use_long_context
参数说明:
- --llm_url:目标 LLM 服务地址(必填)
- --api_key:认证密钥(可选)
- --model:模型名称(默认为 deepseek-r1)
- --use_long_context:启用长文本测试模式(默认关闭)
2. 单次并发测试(按需定制)
若只想测试特定并发级别,可使用单测脚本:
python llm_benchmark.py \ --llm_url "http://your-llm-server" \ --api_key "your-api-key" \ --model "your-model-name" \ --num_requests \ --concurrency
参数说明:
- --num_requests:总请求数(必填)
- --concurrency:并发数量(必填)
还可自定义输出 token 数、超时时间、输出格式等。
实测结果展示
我使用如下命令对本地部署的模型进行全量长上下文测试:
python run_benchmarks.py \ --llm_url "http://localhost:8001/v1" \ --api_key "123" \ --model "R1-0528-Qwen3-8B" \ --use_long_context
测试结果如下图所示:
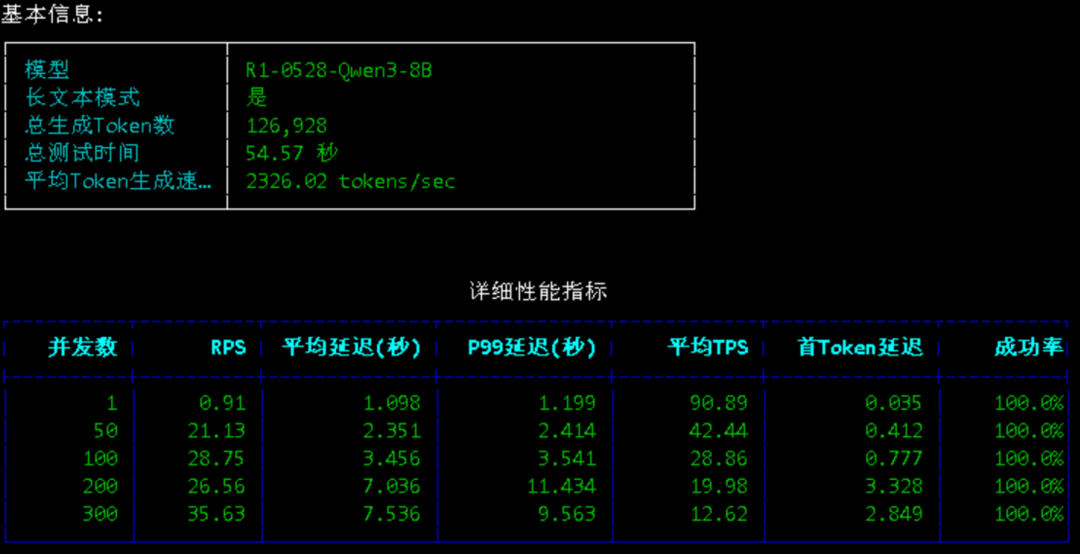 图片
图片
性能指标解读
RPS(每秒请求数)
衡量系统吞吐能力,RPS 越高,并发处理能力越强。测试中从单并发 0.91 提升至 300 并发下的 43.53,表现出色。平均延迟(秒)
用户体验的关键指标。低并发时仅 1.098 秒,300 并发上升至 12.62 秒,符合预期增长趋势。P99 延迟(秒)
反映极端情况下的响应稳定性。随着并发增加略有上升,但整体可控。平均 TPS(每秒生成 token 数)
衡量模型生成效率。峰值达 90.89 tokens/s,在 50 并发下仍保持 42.44,表现优异。首 Token 延迟(秒)
影响交互即时感。低并发下低至 0.035 秒,但在 200/300 并发时升至约 2.85 秒,说明高负载下启动响应略有延迟。成功率
所有测试场景下均为 100%,无请求失败,稳定性极佳。
对比主流平台 DeepSeek API 实际生成速度
| 平台 | 生成速度(tokens/s) | 备注 |
|---|---|---|
| DeepSeek-V3 官方宣称 | 60 | 官方数据 |
| DeepSeek-R1 实测(Content部分) | 37.76 | 118 tokens / 3.12s |
| DeepSeek-R1 总体实测 | 33.01 | 436 tokens / 13.21s |
| 深圳本地测试 DeepSeek 官方服务 | 37.117(生成),25.378(推理) | —— |
| 火山引擎(深圳) | 65.673 | 成都节点高达 72.276 |
| 火山引擎(六平台评测均值) | 32(生成),29(推理) | 稳定性突出 |
| 硅基流动(深圳) | 16.966 | —— |
| 阿里云百炼(深圳) | 11.813 | 存在明显时段波动 |
| 讯飞开放平台 | 1.2(推理均值) | 表现较弱 |
| Meta Llama API(Cerebras) | 高达 2600 | Llama 4 Cerebras |
| Groq(Llama 4 Scout) | 460 | 极速推理硬件支持 |
总结
在本地资源有限的前提下,DeepSeek-R1-0528-Qwen-8B 配合双 4090 显卡部署方案,依然是我心中最均衡、最实用的选择。
无论是吞吐能力、响应速度还是稳定性,实测表现都令人满意,尤其在中等并发下兼顾了效率与体验。相比部分公有云 API 的波动性,本地部署更可控、更安全、成本更低。
如果你也在寻找一款适合本地运行的高性能蒸馏模型,强烈推荐尝试这个组合!
今天关于《本地部署大模型测试,DeepSeek-R1性能依然出色》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
284 收藏
-
文章 · 软件教程 | 11小时前 | 开发工具 · vs code · profiles · 软件教程 · 配置同步 · 软件教程 Visual Studio Code VS Code Profiles 配置档 导出配置 导入配置185 收藏
-
文章 · 软件教程 | 12小时前 | 开发环境 · windows terminal · 软件教程 · 终端工具 · Ubuntu PowerShell 软件教程 Windows Terminal 默认配置文件 起始路径495 收藏
-
文章 · 软件教程 | 14小时前 | Windows · 软件教程 · PowerToys · PowerRename · 批量重命名 · PowerToys 批量重命名 软件教程 PowerRename Windows重命名 文件改名413 收藏
-
217 收藏
-
486 收藏
-
文章 · 软件教程 | 6天前 | 环境变量 · postman · 软件教程 · 接口测试 · 导入导出 · 环境变量 Collection JSON文件 导入导出 Postman Environment 接口集合308 收藏
-
文章 · 软件教程 | 1星期前 | PNG · diagrams.net · 软件教程 · draw.io · 流程图 · 透明背景 流程图 软件教程 Diagrams.net PNG导出 draw.io 图片归档130 收藏
-
文章 · 软件教程 | 1星期前 | 版本控制 · source control · 软件教程 · VS Code教程 · Git冲突 · VS Code 软件教程 Git冲突 Source Control Merge Editor 提交核对395 收藏
-
文章 · 软件教程 | 1星期前 | network · Har · 软件教程 · Chrome DevTools · 前端调试 · 软件教程 Chrome DevTools HAR文件 Network面板 前端排查410 收藏
-
文章 · 软件教程 | 1星期前 | 开发工具 · vs code · 软件教程 · 设置排错 · VS Code 搜索排除 search.exclude files.exclude Use Exclude Settings256 收藏
-
文章 · 软件教程 | 1星期前 | 接口文档 · postman · openapi · 接口测试 · Collection导出 · OpenAPI 软件教程 Collection Postman 接口调试363 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习