DeepSeek原理与实战要点解析
时间:2025-08-17 17:51:31 214浏览 收藏
想深入了解DeepSeek大模型的底层技术与工程实践?《DeepSeek原理与项目实战》这本书或许能帮到你。本书有别于市面上侧重应用技巧的书籍,它聚焦于DeepSeek的技术创新与优化,适合开发者、算法工程师等希望从代码层面理解大模型运作机制的读者。本书深入剖析了DeepSeek的核心技术,例如通过多头潜在注意力(MLA)实现KV缓存的高效压缩,利用动态路由机制优化MOE架构,以及在千亿参数级别验证FP8混合精度训练,显著降低训练成本。此外,本书还介绍了多Token预测(MTP)加速推理的新范式,以及如何通过技术优化将上下文长度扩展至128K Token。通过阅读本书,你将不仅了解DeepSeek的“用法”,更能理解其背后的设计原理与实现方式,是深入大模型内核的难得实战指南。
Hello,大家好,我是人月聊IT。
今天想为大家推荐并解读一本新书——《DeepSeek原理与项目实战》。为什么选择这本书来做导读?因为在目前关于DeepSeek的出版物中,大多数仍聚焦于应用技巧、提示词编写等内容。这类书籍我一直认为阅读价值有限,毕竟相关知识通过查阅官方文档或观看在线教程就能快速掌握。
而这本书的不同之处在于,它深入到了DeepSeek的技术底层与工程实践,更适合开发者、算法工程师以及希望从代码层面理解大模型运作机制的读者。全书结构清晰,主要分为两大模块:一是DeepSeek的核心原理剖析,二是真实场景下的项目实战。
接下来,我就按照这个逻辑脉络,带大家梳理几个关键的技术亮点。
1. DeepSeek的核心技术解析
作为一款先进的大语言模型,尤其是DeepSeek-V3,已经达到了通用大模型的水准,其底层架构与GPT-4、Claude等主流模型并无本质差异。因此本书并未停留在Transformer基础原理的讲解上,而是聚焦于DeepSeek在已有技术上的创新与优化,这才是我们真正需要关注的重点。
自注意力机制 → 多头潜在注意力(MLA)
众所周知,多头注意力机制(Multi-Head Attention, MHA)最早由Vaswani等人在2017年提出,并非DeepSeek原创。但DeepSeek在此基础上提出了多头潜在注意力(Multi-Head Latent Attention, MLA),实现了对KV缓存的高效压缩。
传统MHA在推理过程中需要存储每个注意力头的历史Key和Value,导致显存占用高。而MLA通过低秩联合压缩的方式,将多个头的KV投影到一个共享的低维潜在空间中。这意味着在推理时只需更新这个潜在向量,而非维护全部KV缓存,大幅降低了内存消耗和计算开销。
这种设计尤其适合长文本生成和高并发服务场景,是DeepSeek实现高性能推理的关键之一。
MOE架构升级 → 动态路由机制
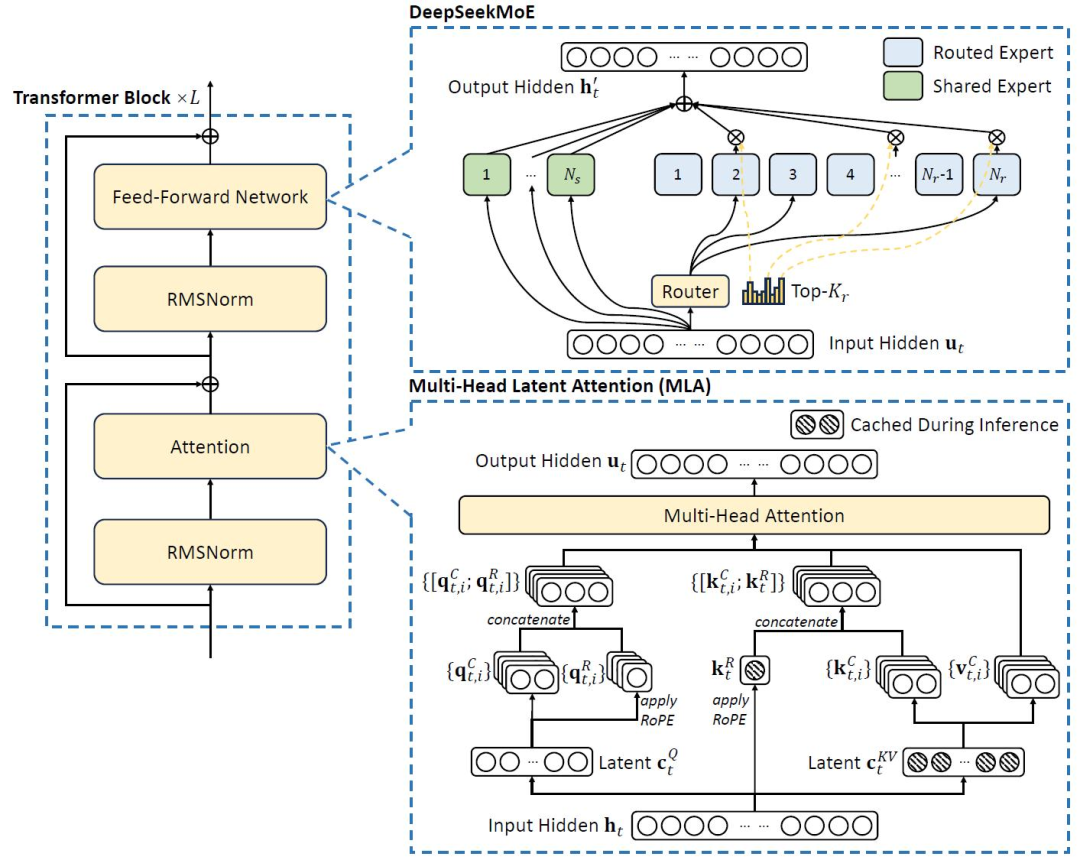
MOE(Mixture of Experts)即“混合专家模型”,本质上是一种“分而治之”的策略:将庞大的模型拆分为多个功能专精的子网络(专家),根据输入任务动态激活相应模块,从而提升效率。
虽然MOE概念并非DeepSeek首创,但它在MoE架构中引入了动态路由算法,显著优化了专家选择机制和负载均衡问题。传统MoE依赖辅助损失函数来平衡专家使用率,容易干扰主训练目标。而DeepSeek通过动态偏置调整,让冷门专家也能被合理调用,避免资源闲置或热点过载。
换句话说,关键不在于有多少个专家,而在于如何精准调度这些专家——这正是动态路由的核心价值所在。
FP8混合精度训练:千亿级模型的效率突破
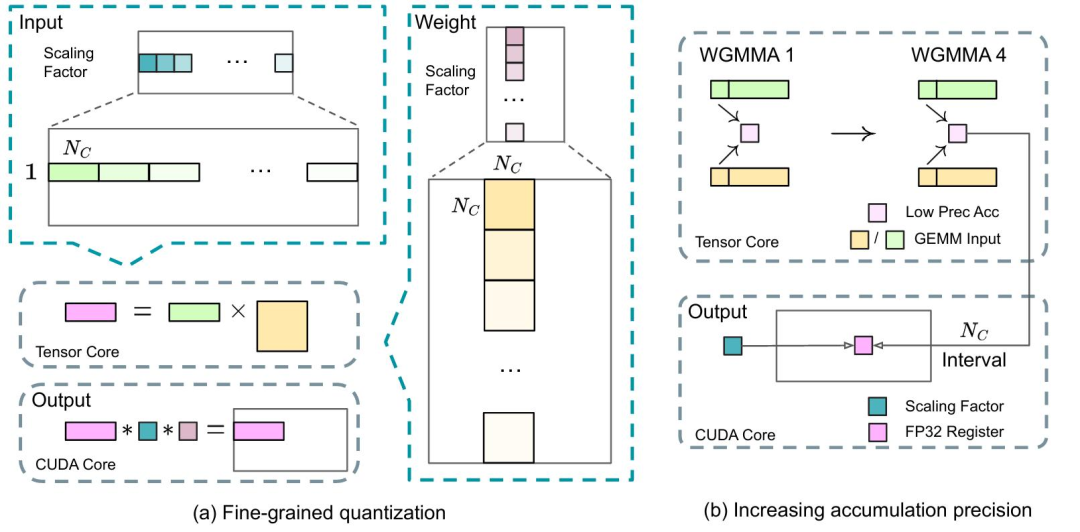
DeepSeek-V3是首个在千亿参数级别成功验证FP8混合精度训练的大模型。这一技术突破极大降低了训练成本和GPU显存需求。
具体来说,FP8混合精度训练采用细粒度量化+动态缩放+混合存储策略:
- 在前向传播和部分反向传播中使用FP8低精度格式,减少计算量;
- 在梯度累积、权重更新等关键环节切换回FP16或FP32,保障数值稳定性。
类比一个数学运算场景:加法对精度敏感度较低,可容忍低精度处理;而乘法容易因舍入误差累积导致偏差,需更高精度计算。因此,混合精度的本质就是“因地制宜”地分配计算资源。
多Token预测(MTP):加速推理的新范式
为何要单独强调MTP?因为它直接改变了大模型“逐字生成”的传统模式,实现了一次输出多个Token,显著提升推理速度。
以代码补全为例,传统模型逐词生成“function”、“name”、“{”,而启用MTP后,模型可一次性预测出“function name {}”这样的完整结构,响应速度成倍提升。
这一技术在IDE插件、自动编程等实时交互场景中意义重大,是提升用户体验的关键手段。
长上下文支持:128K Token的极限拓展

DeepSeek通过一系列技术优化,将上下文长度扩展至128K Token,相当于一本中篇小说的信息容量。这使得模型能够完整处理长文档、跨文件代码库、复杂技术手册等任务。
无论是法律合同分析、科研论文解读,还是大型软件项目的理解,128K上下文都让模型具备了“全局视角”,避免了因截断导致的信息丢失。
蒸馏技术:浓缩即精华
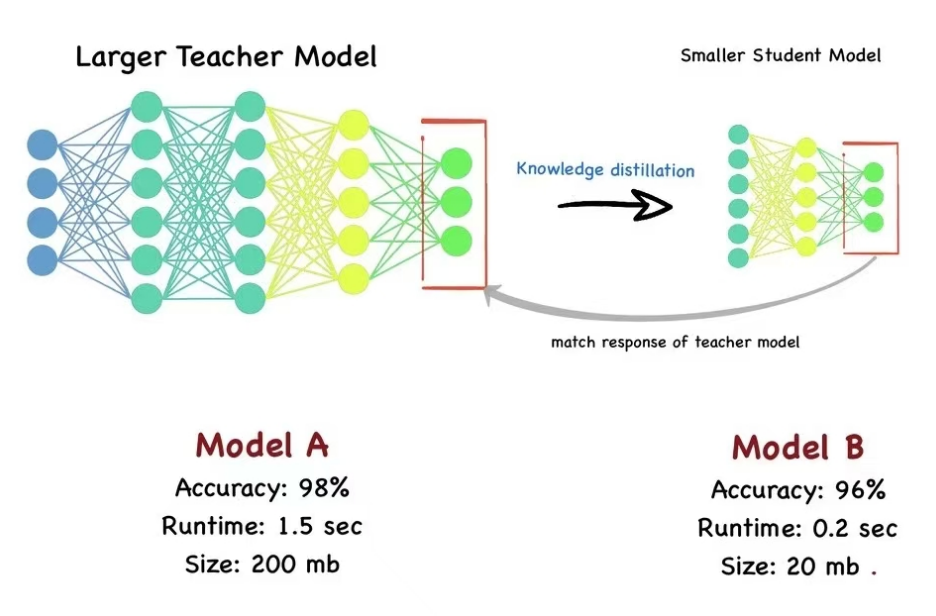
虽然书中未重点展开蒸馏技术,但在学习DeepSeek生态时,这是不可忽视的一环。正如《三体》中三体人“脱水”求生的情节,模型蒸馏也是一种“去冗存精”的过程。
蒸馏技术通过让一个小模型(学生)模仿一个大模型(教师)的行为,将大模型的知识“提炼”进小模型中,使其在保持轻量的同时接近大模型的表现。
DeepSeek采用监督微调方式进行知识迁移,并在特定任务蒸馏方面做了创新。例如,DeepSeek-R1-Distill-Qwen-7B在AIME 2024基准测试中取得了55.5%的通过率,甚至超越了QwQ-32B-Preview版本,充分证明了蒸馏技术的有效性。
总结来看,《DeepSeek原理与项目实战》这本书的价值在于:它不满足于“怎么用”,而是深入解答了“为什么这么设计”和“如何自己实现”。对于想深入大模型内核的开发者而言,是一本难得的实战指南。
今天带大家了解了的相关知识,希望对你有所帮助;关于文章的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
-
文章 · 软件教程 | 4天前 | go · vs code · 软件教程 · 测试任务 · tasks.json · VS Code 测试任务 终端输出 Go插件 Go测试 tasks.json 问题面板501 收藏
-
284 收藏
-
文章 · 软件教程 | 4天前 | 开发工具 · vs code · profiles · 软件教程 · 配置同步 · 软件教程 Visual Studio Code VS Code Profiles 配置档 导出配置 导入配置185 收藏
-
文章 · 软件教程 | 5天前 | 开发环境 · windows terminal · 软件教程 · 终端工具 · Ubuntu PowerShell 软件教程 Windows Terminal 默认配置文件 起始路径495 收藏
-
文章 · 软件教程 | 5天前 | Windows · 软件教程 · PowerToys · PowerRename · 批量重命名 · PowerToys 批量重命名 软件教程 PowerRename Windows重命名 文件改名413 收藏
-
217 收藏
-
486 收藏
-
文章 · 软件教程 | 1星期前 | 环境变量 · postman · 软件教程 · 接口测试 · 导入导出 · 环境变量 Collection JSON文件 导入导出 Postman Environment 接口集合308 收藏
-
文章 · 软件教程 | 1星期前 | PNG · diagrams.net · 软件教程 · draw.io · 流程图 · 透明背景 流程图 软件教程 Diagrams.net PNG导出 draw.io 图片归档130 收藏
-
文章 · 软件教程 | 2星期前 | 版本控制 · source control · 软件教程 · VS Code教程 · Git冲突 · VS Code 软件教程 Git冲突 Source Control Merge Editor 提交核对395 收藏
-
文章 · 软件教程 | 2星期前 | network · Har · 软件教程 · Chrome DevTools · 前端调试 · 软件教程 Chrome DevTools HAR文件 Network面板 前端排查410 收藏
-
文章 · 软件教程 | 2星期前 | 开发工具 · vs code · 软件教程 · 设置排错 · VS Code 搜索排除 search.exclude files.exclude Use Exclude Settings256 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习