全球首个LLM竞技场上线,23模型对决揭秘
时间:2025-08-20 08:40:13 105浏览 收藏
各位小伙伴们,大家好呀!看看今天我又给各位带来了什么文章?本文标题是《全球首个LLM竞技场上线,23模型激烈比拼》,很明显是关于文章的文章哈哈哈,其中内容主要会涉及到等等,如果能帮到你,觉得很不错的话,欢迎各位多多点评和分享!
【新智元导读】近日,由Ai2、耶鲁大学与纽约大学联手打造的科研版「Chatbot Arena」——SciArena正式亮相。全球23款顶尖大模型同台竞技真实科研任务,OpenAI o3强势登顶,DeepSeek紧随其后,超越Gemini跻身前四!然而评估结果显示,当前自动评分系统在预测科研人员偏好方面仍力不从心。
如今,利用AI大模型辅助撰写论文已成为科研人员的日常操作。
根据ZIPDO 2025年教育报告,AI已深度融入70%的研究实验室,五年间相关科研论文数量激增150%。
 图片尽管AI在科研辅助领域飞速发展,但一个核心问题始终未解:
图片尽管AI在科研辅助领域飞速发展,但一个核心问题始终未解:
「大模型到底能不能胜任复杂的科研任务?」
传统评测基准往往静态且局限,难以反映科研所需的深度理解与逻辑推理能力。
为此,Ai2联合耶鲁和NYU推出SciArena,标志着科学智能正式进入「擂台对决」时代!
 图片论文地址:https://arxiv.org/pdf/2507.01001
图片论文地址:https://arxiv.org/pdf/2507.01001
目前已有23个最先进大语言模型加入SciArena的比拼,涵盖OpenAI、Anthropic、DeepSeek、Google等主流产品。
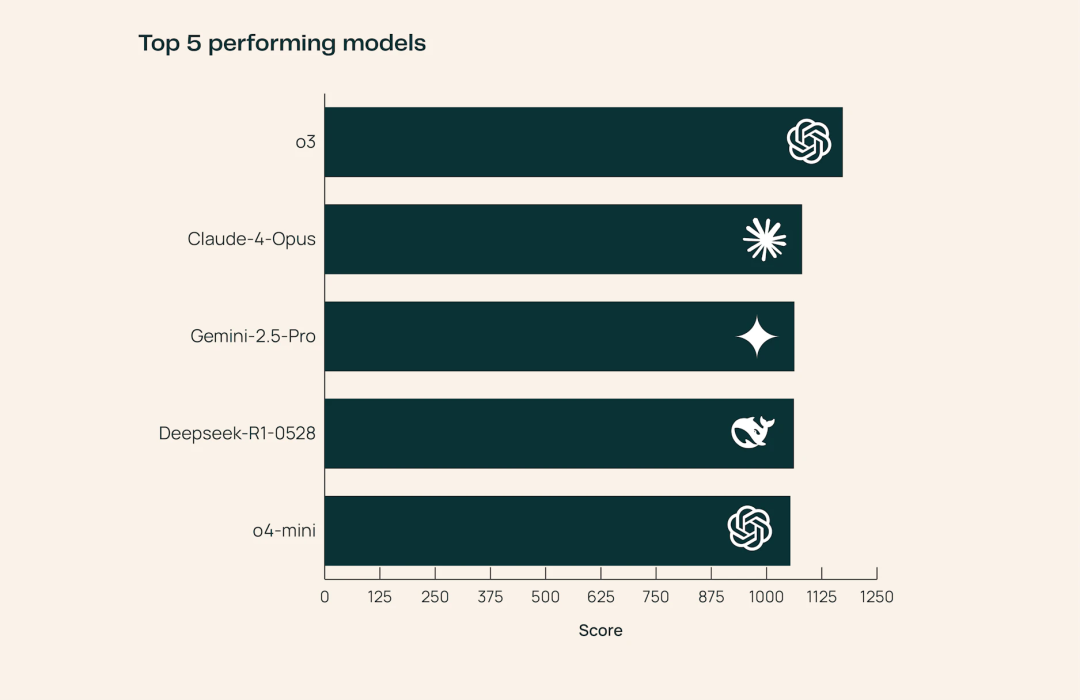
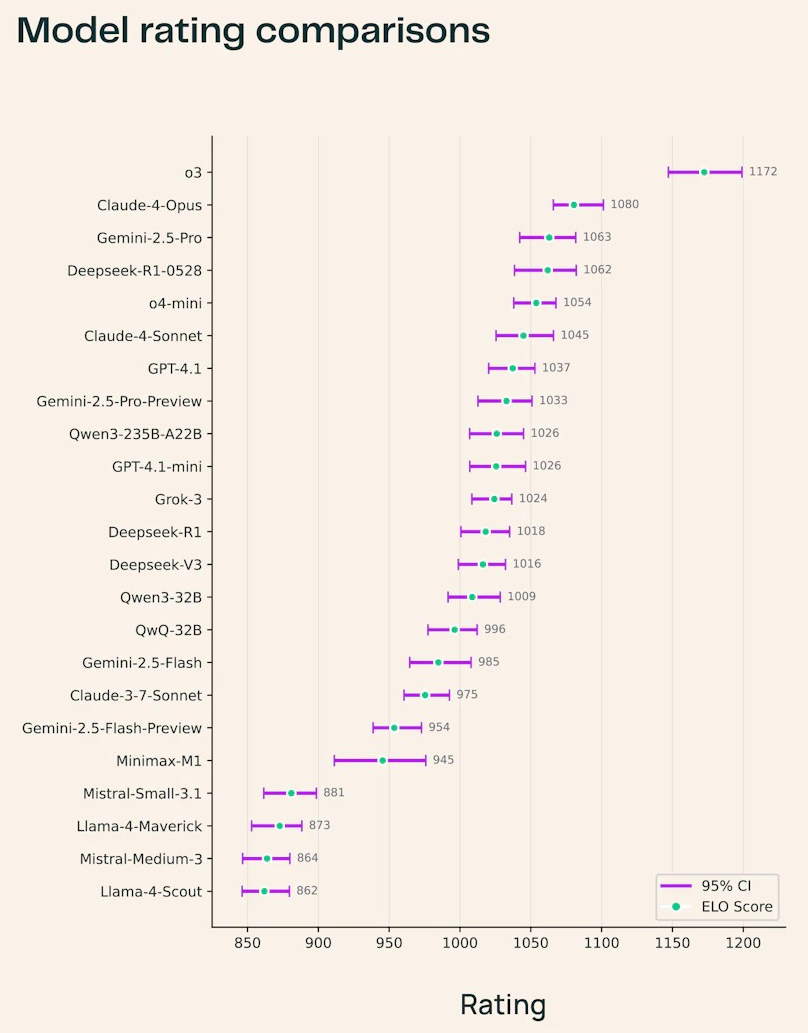 图片其中,OpenAI o3以绝对优势领跑全场,在所有科学领域均表现最佳,其生成的论文解读更具专业深度。
图片其中,OpenAI o3以绝对优势领跑全场,在所有科学领域均表现最佳,其生成的论文解读更具专业深度。
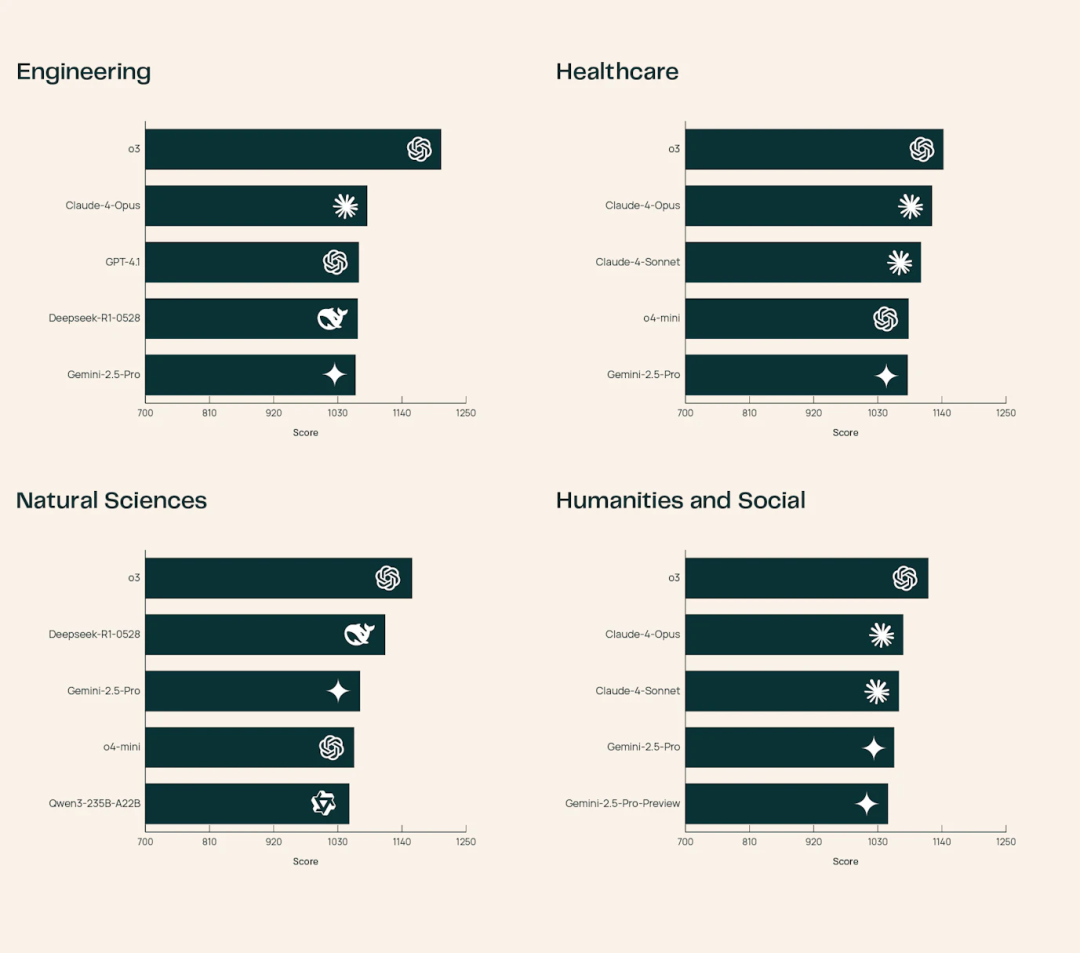
 图片其他模型则在细分领域各展所长:
图片其他模型则在细分领域各展所长:
例如Claude-4-Opus在医疗健康领域知识扎实,而DeepSeek-R1-0528在自然科学方向表现突出。
 图片值得一提的是,SciArena一经发布便获得Nature专题报道,被誉为「窥探大模型知识架构的新窗口」。
图片值得一提的是,SciArena一经发布便获得Nature专题报道,被誉为「窥探大模型知识架构的新窗口」。
 图片那么,SciArena凭什么成为衡量科研AI能力的可靠标准?
图片那么,SciArena凭什么成为衡量科研AI能力的可靠标准?
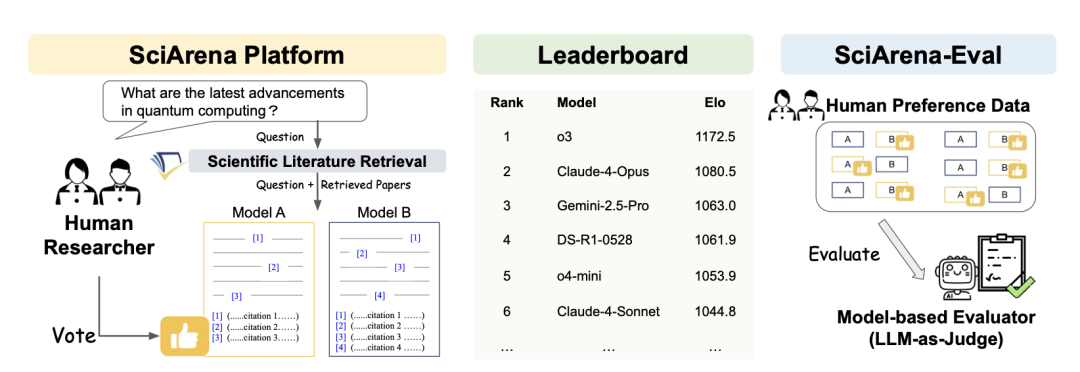
SciArena:专为科研打造的AI「试金石」
SciArena是首个专为科学文献任务设计的大模型开放式评估平台。
 图片科研人员可在该平台提交问题,并匿名对比不同模型的回答,通过投票决定更优输出。
图片科研人员可在该平台提交问题,并匿名对比不同模型的回答,通过投票决定更优输出。
团队采用Chatbot Arena风格的众包、双盲对决机制,用真实科研场景检验模型实力。
针对科研任务特有的复杂性与开放性,SciArena优化了评估流程,弥补了通用基准在科研应用中的不足。
平台由三大核心模块构成:
SciArena平台:用户在此提问并对比模型回复,进行偏好选择。排行榜:基于Elo评分系统动态更新各模型排名,提供实时性能参考。SciArena-Eval:基于人类偏好数据构建的元评估基准,旨在测试AI能否准确预测人类判断。对决背后的机制揭秘
从提问到投票:完整评估流程解析
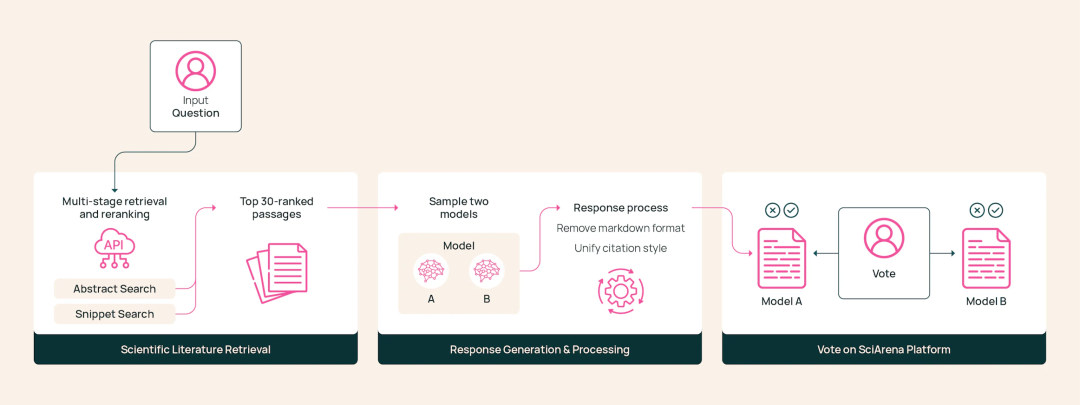
SciArena的评估流程包括论文检索、模型响应生成和用户评判三个阶段。
相比普通问答,科研类问题更强调以权威文献为依据。
为保障检索质量,团队改进了AI2的Scholar QA系统,构建了一套多阶段检索流水线。
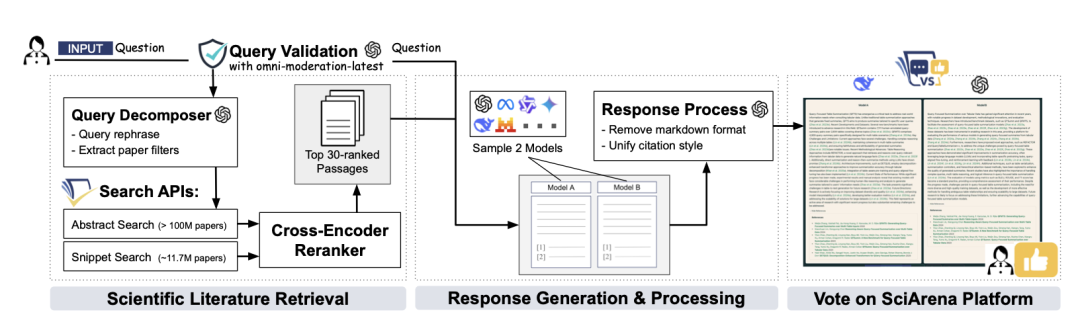 图片该流程包含查询拆解、段落提取与结果重排序等环节。
图片该流程包含查询拆解、段落提取与结果重排序等环节。
当用户提出问题后,系统启动检索流程,获取相关科研论文作为上下文。
随后,将问题与上下文同时发送给两个随机选取的基础模型。
两模型分别生成内容详实、附带规范引用的长篇回答。
平台对两份回答进行标准化处理,转换为统一格式的纯文本,避免用户识别出模型来源。
最后,用户在匿名条件下对两份答案进行比较,并选出更满意的一方。
 图片需要指出的是,SciArena主要聚焦于可横向比较的「通用基础模型」。
图片需要指出的是,SciArena主要聚焦于可横向比较的「通用基础模型」。
像OpenAI Deep Research这类定制化智能体或闭源系统,并不在评估范围内。
102位专家,13000张选票
高质量评估,离不开高质量数据。
SciArena团队对数据质量把控极为严格。
在平台上线初期四个月内,共收集了来自102位科研专家的超过13000次投票。
 图片这些专家并非普通用户,而是活跃在科研一线的研究生,平均发表论文超过两篇。
图片这些专家并非普通用户,而是活跃在科研一线的研究生,平均发表论文超过两篇。
所有标注人员均接受过一小时的专业培训,确保评判标准统一。
结合双盲机制,每一条评估结果都具备高度可信度。
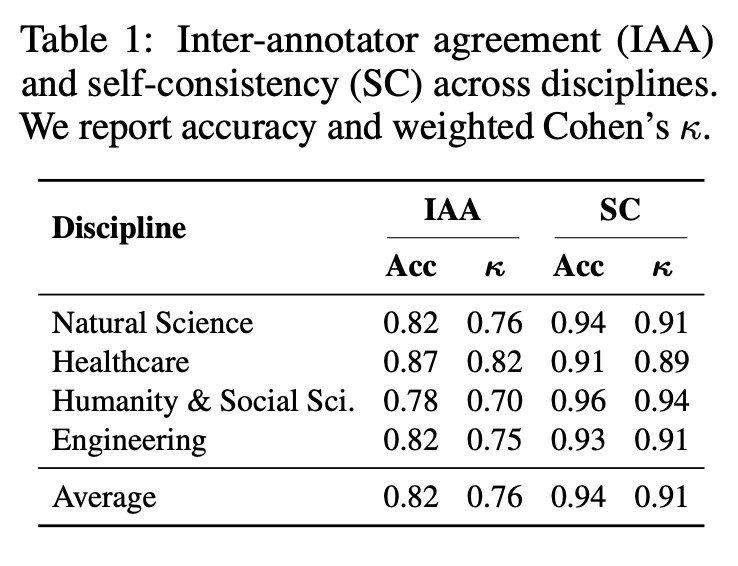
在如此严苛的标准下,平台数据展现出极高的内部一致性(加权科恩系数κ=0.91),评审间一致性也达到良好水平(κ=0.76)。
 图片这13000余次有效投票,为SciArena建立了坚实可靠的评估基础。
图片这13000余次有效投票,为SciArena建立了坚实可靠的评估基础。
最强AI,也难猜科研人心
基于SciArena-Eval基准,研究团队测试了「模型评估模型」的自动评分能力:
给定一个问题和两个模型的回答,让评估模型预测哪个更可能被人类选中。
结果令人深思。
即便是最强的o3模型,准确率也仅为65.1%,而Gemini-2.5-Flash和LLaMA-4系列的表现几乎等同于随机猜测。
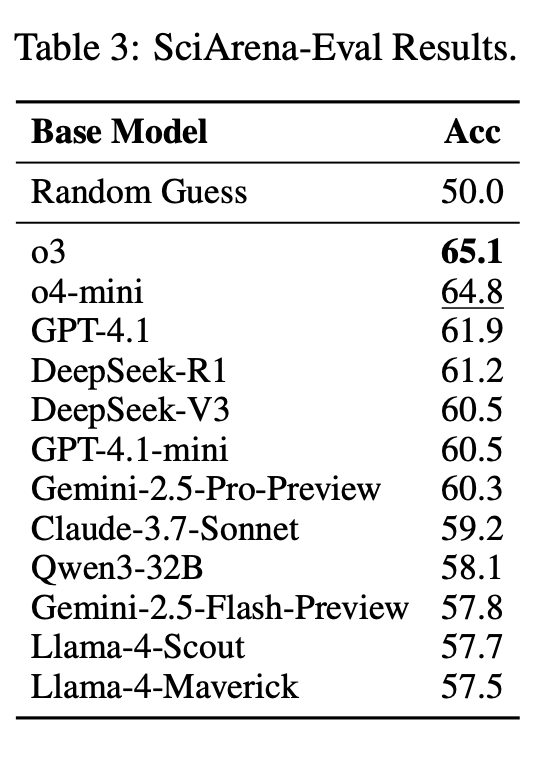 图片相比之下,通用领域的AlpacaEval、WildChat等基准中,评估模型准确率普遍超过70%,可见科研任务的判断难度显著更高。
图片相比之下,通用领域的AlpacaEval、WildChat等基准中,评估模型准确率普遍超过70%,可见科研任务的判断难度显著更高。
尽管整体表现不尽如人意,但仍见亮点。
具备推理能力的模型在判断优劣时更具优势。
例如,o4-mini比GPT-4.1高出2.9%,DeepSeek-R1也略胜于自家的DeepSeek-V3。
这表明,具备推理能力的AI更能把握科研问题的核心。
研究团队认为,SciArena-Eval有望成为未来科研AI评估的新标杆,帮助我们判断AI是否真正理解了科研人员的思维逻辑。
参考资料:
https://allenai.org/blog/sciarena
https://arxiv.org/pdf/2507.01001
https://the-decoder.com/sciarena-lets-scientists-compare-llms-on-real-research-questions/
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于文章的相关知识,也可关注golang学习网公众号。

-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
239 收藏
-
173 收藏
-
144 收藏
-
312 收藏
-
369 收藏
-
269 收藏
-
134 收藏
-
147 收藏
-
379 收藏
-
311 收藏
-
195 收藏
-
146 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习