面向长代码序列的 Transformer 模型优化方法,提升长代码场景性能
来源:51CTO.COM
时间:2023-04-28 08:26:03 212浏览 收藏
亲爱的编程学习爱好者,如果你点开了这篇文章,说明你对《面向长代码序列的 Transformer 模型优化方法,提升长代码场景性能》很感兴趣。本篇文章就来给大家详细解析一下,主要介绍一下,希望所有认真读完的童鞋们,都有实质性的提高。
阿里云机器学习平台PAI与华东师范大学高明教授团队合作在SIGIR2022上发表了结构感知的稀疏注意力Transformer模型SASA,这是面向长代码序列的Transformer模型优化方法,致力于提升长代码场景下的效果和性能。由于self-attention模块的复杂度随序列长度呈次方增长,多数编程预训练语言模型(Programming-based Pretrained Language Models, PPLM)采用序列截断的方式处理代码序列。SASA方法将self-attention的计算稀疏化,同时结合了代码的结构特性,从而提升了长序列任务的性能,也降低了内存和计算复杂度。
论文:Tingting Liu, Chengyu Wang, Cen Chen, Ming Gao, and Aoying Zhou. Understanding Long Programming Languages with Structure-Aware Sparse Attention. SIGIR 2022
模型框架
下图展示了SASA的整体框架:
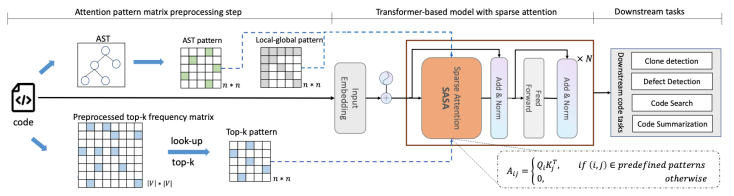
其中,SASA主要包含两个阶段:预处理阶段和Sparse Transformer训练阶段。在预处理阶段得到两个token之间的交互矩阵,一个是top-k frequency矩阵,一个是AST pattern矩阵。Top-k frequency矩阵是利用代码预训练语言模型在CodeSearchNet语料上学习token之间的attention交互频率,AST pattern矩阵是解析代码的抽象语法树(Abstract Syntax Tree,AST ),根据语法树的连接关系得到token之间的交互信息。Sparse Transformer训练阶段以Transformer Encoder作为基础框架,将full self-attention替换为structure-aware sparse self-attention,在符合特定模式的token pair之间进行attention计算,从而降低计算复杂度。
SASA稀疏注意力一共包括如下四个模块:
- Sliding window attention:仅在滑动窗口内的token之间计算self-attention,保留局部上下文的特征,计算复杂度为,为序列长度,是滑动窗口大小。
- Global attention:设置一定的global token,这些token将与序列中所有token进行attention计算,从而获取序列的全局信息,计算复杂度为,为global token个数。
- Top-k sparse attention:Transformer模型中的attention交互是稀疏且长尾的,对于每个token,仅与其attention交互最高的top-k个token计算attention,复杂度为。
- AST-aware structure attention:代码不同于自然语言序列,有更强的结构特性,通过将代码解析成抽象语法树(AST),然后根据语法树中的连接关系确定attention计算的范围。
为了适应现代硬件的并行计算特性,我们将序列划分为若干block,而非以token为单位进行计算,每个query block与
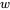
个滑动窗口blocks和
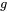
个global blocks以及
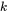
个top-k和AST blocks计算attention,总体的计算复杂度为
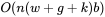
b为block size。
每个sparse attention pattern 对应一个attention矩阵,以sliding window attention为例,其attention矩阵的计算为:
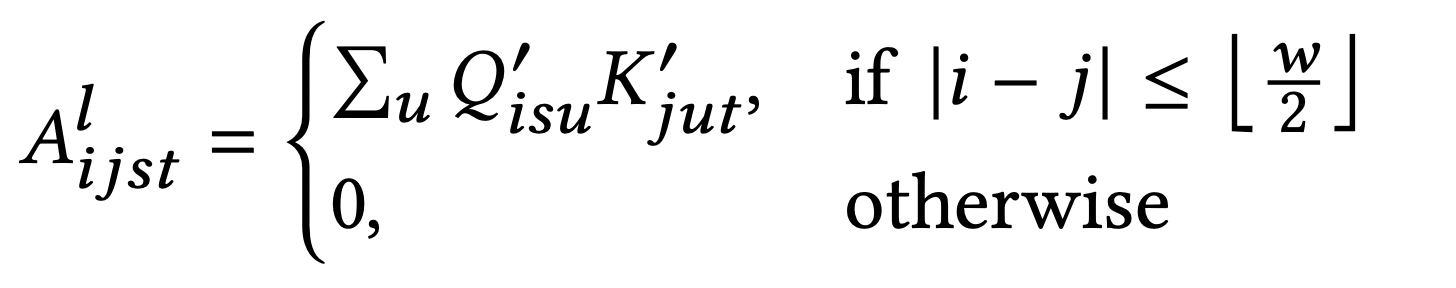
ASA伪代码:

实验结果
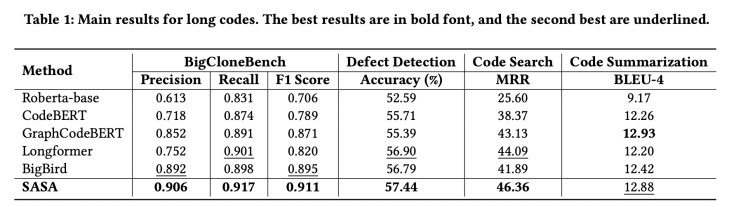
我们采用CodeXGLUE[1]提供的四个任务数据集进行评测,分别为code clone detection,defect detection,code search,code summarization。我们提取其中的序列长度大于512的数据组成长序列数据集,实验结果如下:
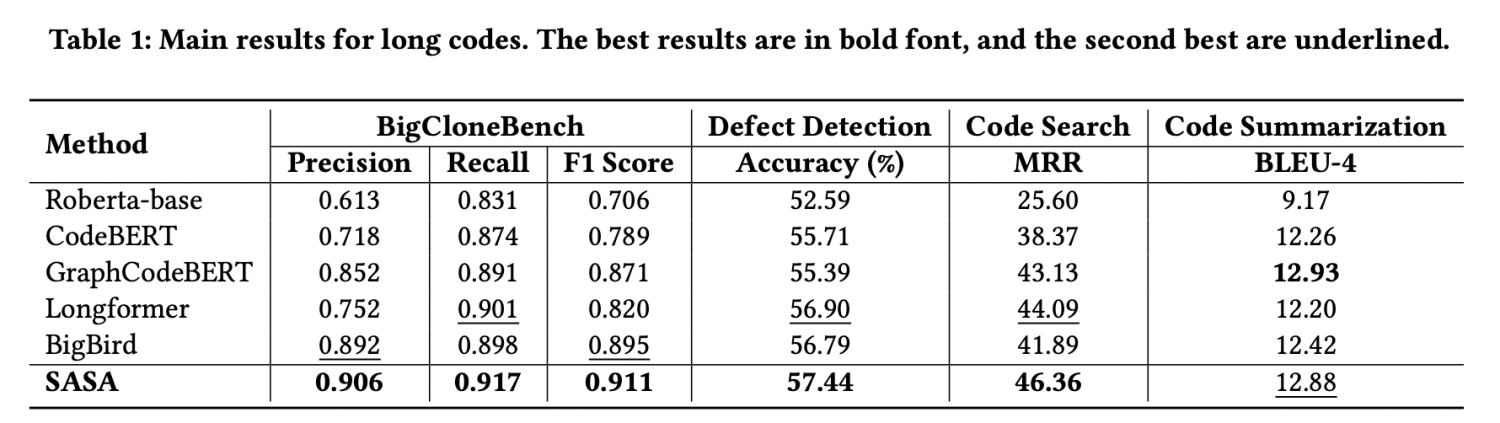
从实验结果可以看出,SASA在三个数据集上的性能明显超过所有Baseline。其中Roberta-base[2],CodeBERT[3],GraphCodeBERT[4]是采用截断的方式处理长序列,这将损失一部分的上下文信息。Longformer[5]和BigBird[6]是在自然语言处理中用于处理长序列的方法,但未考虑代码的结构特性,直接迁移到代码任务上效果不佳。
为了验证top-k sparse attention和AST-aware sparse attention模块的效果,我们在BigCloneBench和Defect Detection数据集上做了消融实验,结果如下:
sparse attention模块不仅对于长代码的任务性能有提升,还可以大幅减少显存使用,在同样的设备下,SASA可以设置更大的batch size,而full self-attention的模型则面临out of memory的问题,具体显存使用情况如下图:

SASA作为一个sparse attention的模块,可以迁移到基于Transformer的其他预训练模型上,用于处理长序列的自然语言处理任务,后续将集成到开源框架EasyNLP(https://github.com/alibaba/EasyNLP)中,贡献给开源社区。
论文链接:
https://arxiv.org/abs/2205.13730
文中关于模型,计算的知识介绍,希望对你的学习有所帮助!若是受益匪浅,那就动动鼠标收藏这篇《面向长代码序列的 Transformer 模型优化方法,提升长代码场景性能》文章吧,也可关注golang学习网公众号了解相关技术文章。
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
154 收藏
-
309 收藏
-
234 收藏
-
科技周边 · 人工智能 | 3天前 | 人工智能 · 前端流式输出 · AI聊天 · Fetch Stream · 前端 AI聊天 流式输出 ReadableStream TextDecoder Fetch Stream448 收藏
-
427 收藏
-
191 收藏
-
299 收藏
-
科技周边 · 人工智能 | 1星期前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-
453 收藏
-
202 收藏
-
419 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习