DeepSeek使用技巧与实战指南
时间:2025-08-27 12:55:06 293浏览 收藏
怎么入门文章编程?需要学习哪些知识点?这是新手们刚接触编程时常见的问题;下面golang学习网就来给大家整理分享一些知识点,希望能够给初学者一些帮助。本篇文章就来介绍《DeepSeek应用指南:如何高效实践与利用》,涉及到,有需要的可以收藏一下
DeepSeek为何突然爆火?低成本+开源+私有化是关键
最近,国内大模型赛道杀出一匹黑马——DeepSeek。其热度不亚于年初的ChatGPT,甚至在开发者圈内掀起“平替GPT-4”的讨论。其核心吸引力可总结为三点:
1. 成本低到离谱:调用成本仅为GPT-4的1%,企业级API价格甚至低至0.001元/千Token,中小团队也能轻松上车。
2. 开源可私有部署:模型权重、训练代码全部开源,支持本地离线部署,彻底摆脱数据泄露风险。
3. MOE架构+蒸馏技术:基于混合专家模型(MOE)和知识蒸馏,兼顾性能与效率,7B小模型也能跑出70B的效果。
对于DeepSeek的持续火热,大家都在考虑如何能够接住DeepSeek这波流量。还有很多自媒体将原来GPT火热时候涉及到的内容简单修改后又套到了DeepSeek上面。类似如何写文案,如何写提示语等。而这些内容实际原来使用GPT,豆包,百度文心一言,Kimi的时候已经相当成熟。
而DeepSeek对于企业数字化转型真正的意义实际体现在开源和私有化部署上面,如何通过极低的成本来训练企业细分专业领域的私有大模型。我原来谈AIGC为何在企业内部难以大面积落地和商用,中间就谈到了算力成本投入和隐私安全两个关键问题,而这两点DeepSeek的私有化部署都可以很好解决。
MOE混合专家模型-分而治之
对于DeepSeek,网上也有文章专门谈到了采用阉割版本的H800,花了500多万美元就能够训练出和Claude 3.5,GPT4-o1能力相当的大语言模型。而达成低成本的关键就是MOE混合专家模型和蒸馏技术。
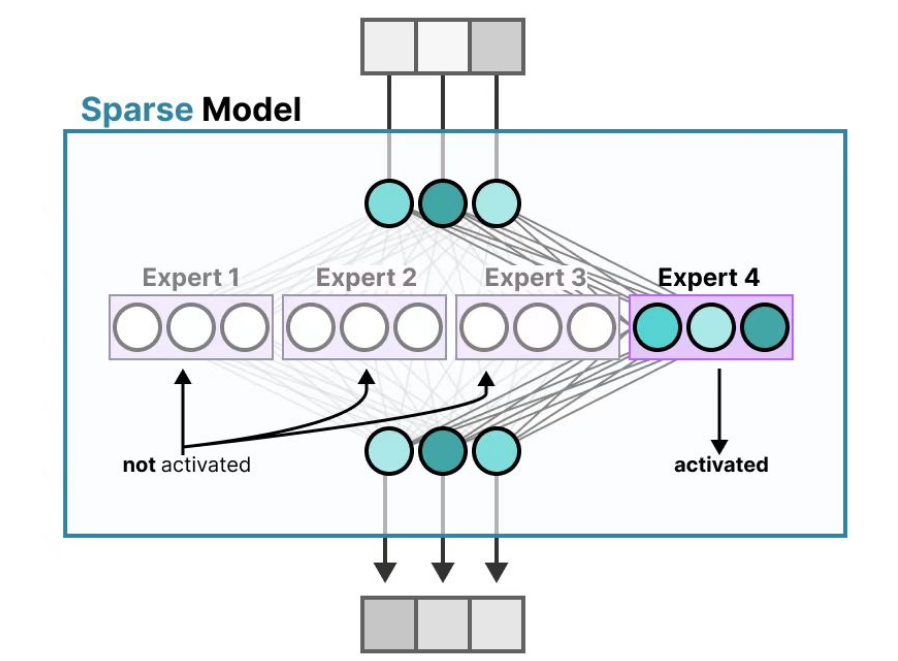
MOE(Mixture of Experts)混合专家模型的的本质是就是分而治之的思路。简单来说就是将原有的大专家模型拆分为多个“专家子网络”,不同任务激活不同专家(如文本生成、代码解析各由专属模块处理)。然后再通过通过门控网络(Gating Network)分配任务权重,避免资源浪费。
我们可以举个简单例子来对比GPT4和DeepSeek。
通俗点说,就像开了一家医院。GPT-4是老专家:啥病都自己看,能力超强但挂号费很贵。而DeepSeek是专科团队:内科、外科、儿科各司其职,效率翻倍还省钱。
采用MOE模型的核心优势就是同等参数量下,MOE模型推理速度提升2-3倍,显存占用降低50%。因此该模型也更加适合垂直场景定制(如医疗问答、代码生成),专家模块可针对性优化。
当然模型也存在一定的缺点,类似训练复杂度高,数据分布不均易导致“专家偏科”(部分模块未被充分训练)。还有就是模型膨胀问题,MOE需额外存储专家参数,开源版DeepSeek-7B实际等效参数量约20B。
蒸馏技术:以小搏大的双刃剑
 图片
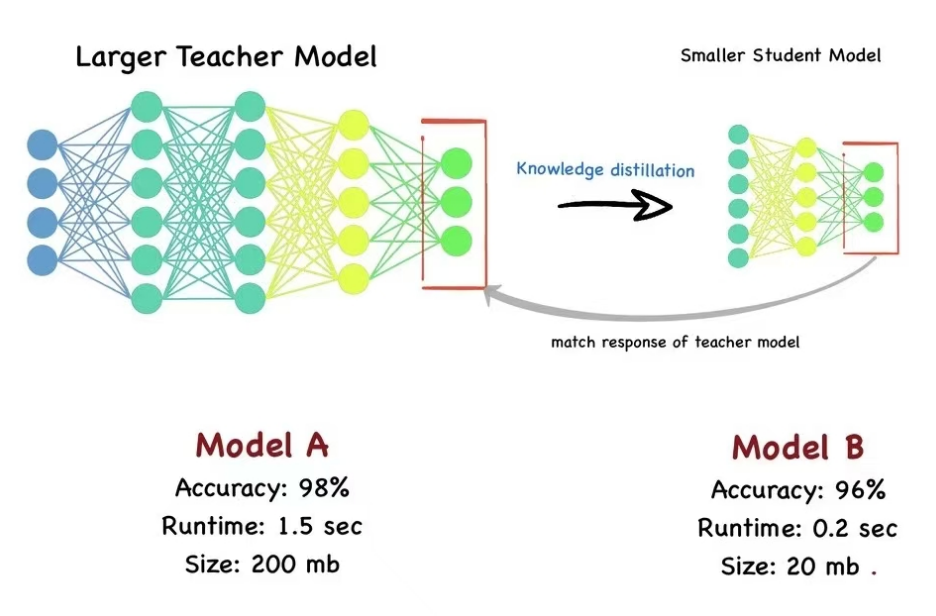
图片一谈到蒸馏这个词,很容易联想到三体里面乱纪元谈到的三体人脱水的情节。简单来说蒸馏技术就是浓缩后的都是精华。蒸馏技术将类似老师的大模型抽取精华并压缩,形成小模型后再投喂给学生,从而达到接近大模型的训练或推理效果。
我们可以举个简单的例子来说明下。
比如一个从业20年的老教师,知识相当渊博,有足够的知识深度和广度。但是这些知识里面很多存在重复,还有很多和考试无关。而学生的目标可能更加单纯,就是考试希望能够考到90分以上。
那么老师的做法是将自己的知识经验形成浓缩后的各个知识点,每个知识点可能还包括3到4种常见的考试题型。那么对于学生来说把这些精华知识都掌握后就能够顺利的考试考高分。哪怕是对于语文教学,老师也可以根据作文的不同风格形成类似八股文的作文写作模版,学生考试的时候按模版套内容就可以了。这种模型压缩最大优点仍然是算力成本的节约,而且响应速度更快。在企业AI应用中,特别是类似物联网边缘AI网关就是一个典型时候场景。
当然大模型蒸馏后也存在问题,类似常识推理、长文本理解等能力弱于原模型,且微调适配性差(二次训练易丢失核心能力)。
还是举刚才老师教学生的例子,类似今年深圳小学生四年级的数学考试试卷,很多学生直接考懵了,因为题目不是简单的数学计算,而是涉及到语文的阅读理解,历史知识的积累,你需要先具备语言历史知识,将问题转换为数学问题,然后才去求解。那么对于这种知识管理和复杂推理,往往就是被压缩后的蒸馏小模型的弱点。
DeepSeek的蒸馏技术采用了监督微调的方式,将教师模型的知识迁移到学生模型中,这一方法在行业内已有广泛应用。DeepSeek在知识迁移策略上进行了多项创新,例如特定任务蒸馏针对不同任务进行优化,提升了学生模型在特定领域的性能。例如DeepSeek-R1-Distill-Qwen-7B在AIME 2024基准测试中实现了55.5%的通过率,超越了QwQ-32B-Preview。
简单总结就是MOE模型和蒸馏技术在提高模型效率和降低成本方面具有显著优势,但在训练稳定性、实现复杂性、专家利用率和推理效率等方面存在一些不足。与GPT-4或GPT-o1相比,DeepSeek在多模态处理、响应速度和复杂推理能力上仍有提升空间。不过DeepSeek通过创新的架构和技术,已经在特定领域表现出色,并且在不断优化和改进中。
Prompt提示词究竟还重要不重要?
前面看到一些自媒体文章,谈DeepSeek使用中,提示词不重要了,这个观点本身是有问题的。对于Prompt提示词仍然很重要,但是具体的场景和用法会出现明显变化。
 图片
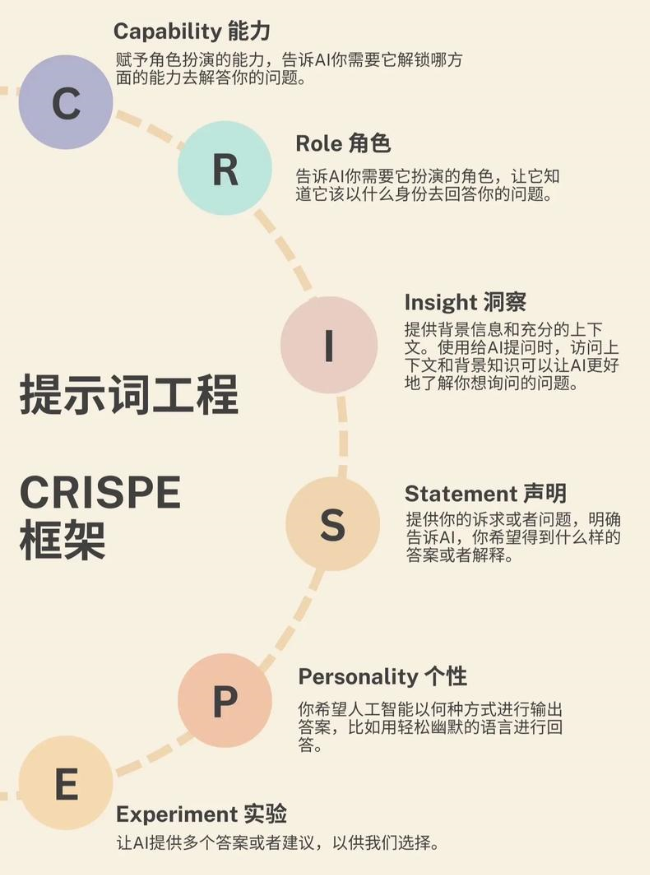
图片在我们使用GPT的时候的,当时有一个标准的提示词模版,即:
角色:让GPT扮演什么角色技能:GPT需要具备哪些关键的技能目标:输出的目标是什么约束:有哪些工具约束,过程约束等在原有的这个提示词模版中,最难的往往是技能描述。类似我希望GPT帮我出一个战略咨询方案思路,我可以让GPT扮演战略咨询专家,但是技能描述里面需要描述具备BLM,DSTE,全面预算管理,组织行为管理,战略执行和解码,CSF关键成功要素等各种技能。这些专业的技能当我们不熟悉战略管理业务领域的时候,实际我们是无法写出来的。
而在使用DeepSeek的时候,提示词重心应该放在我是谁?我遇到什么问题?我遇到问题的环境和场景是如何的?我希望达到什么目标上面。即:
问题-场景-目标。
我并不需要告诉DeepSeek需要具备什么技能,应该是DeepSeek R1深度思考后自己分析应该采用哪些技能才能够帮我解决问题。
我们举个简单的软件开发中的例子如下:
我需要为电商系统设计一个秒杀功能,当前架构是单体应用,MySQL经常崩溃。 而我的目标是要求整个系统支持每秒10万并发,且成本不能超过5万元/月。 请帮我进行整个系统设计,包括需要引入哪些新技术来达到这个目标。
简单来说就是DeepSeek擅长从零构建解决方案,但需明确业务边界与技术约束。同时在提示语中要避免抽象指令(如“优化性能”),改为具体指标(如“API响应
企业自建私有模型:可行,但别踩坑!
DeepSeek开源版大幅降低企业私有化门槛,本地部署方案(以ollama+DeepSeek+anythingLLM为例):
首先分析先可行性,如果仅仅采用7B模型,那么仅需16GB显存,消费级显卡(如RTX 4090)即可部署。同时由于数据完全离线,比RAG(需上传知识库至云端)更安全。
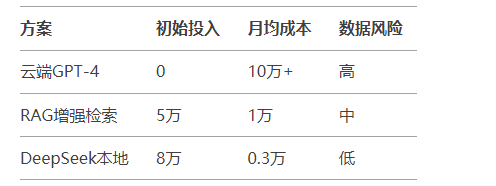
我们可以做一个简单的方案成本对比如下:
 图片
图片可以看到DeepSeek的私有化部署方案成本足够低。对于企业场景的私有知识库构建,AI智能客户来说7B模型也足够使用。
对于私有知识库模型大家,常用方法是ollama+anythingLLM,网上有很多的参考资料大家可以搜索参考。在这里不再展开描述。
解锁DeepSeek的隐藏技能—让AI处理复杂任务
对于DeepSeek的使用不仅仅是聊天和问答。由于DeepSeek本身多模态的能力相当较弱,我们完全可以结合工具链来完成复杂任务的处理。
类似一些本地复杂的自动化任务,我们完全可以让DS生成python代码后在本地进行自动化执行。包括绘制流程图,Office文档处理,图片PS等,都可以采用通过脚本或代码中转的方式来完成。类似下图:
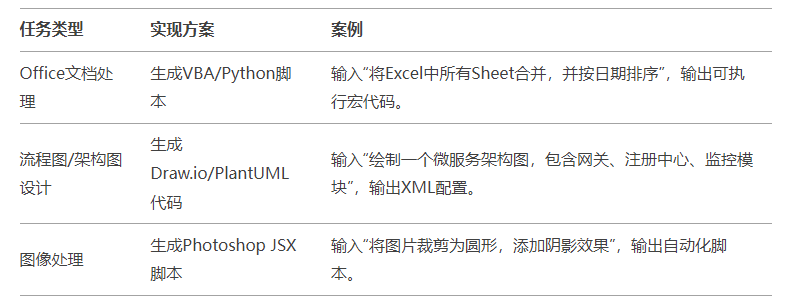
DeepSeek的出现,无疑给AI领域带来了一股清新的风。它的开源、低成本、私有部署等特点,让它在企业中有了广泛的应用前景。通过理解MOE混合专家模型和蒸馏技术,我们可以更好地利用DeepSeek的强大能力。同时,合理设计Prompt,能让DeepSeek更好地理解我们的需求。企业搭建私有大模型,不仅能保护数据隐私,还能根据自己的需求进行定制。最后,通过一些巧妙的方法,DeepSeek还能处理各种复杂的任务。
总之,DeepSeek不仅仅是一个模型,它更是一个强大的工具,可以帮助我们在AI时代更好地解决问题。希望这篇文章能帮助大家更好地理解和应用DeepSeek,让它在实际工作中发挥更大的价值。
以上就是《DeepSeek使用技巧与实战指南》的详细内容,更多关于开源,MoE,DeepSeek,蒸馏技术,私有化部署的资料请关注golang学习网公众号!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
366 收藏
-
422 收藏
-
203 收藏
-
438 收藏
-
文章 · 软件教程 | 3天前 | vs code · 软件教程 · Auto Save · 编辑器设置 · 代码格式化 · VS Code 自动保存 settings.json Auto Save 保存后格式化356 收藏
-
383 收藏
-
269 收藏
-
文章 · 软件教程 | 5天前 | Redis · 数据库工具 · ttl · 软件教程 · RedisInsight · Key管理 · redis 软件教程 TTL WorkBench RedisInsight Key筛选119 收藏
-
270 收藏
-
文章 · 软件教程 | 6天前 | MySQL · SQL · dbeaver · 软件教程 · 数据库客户端 · mysql 数据库工具 SQL Editor DBeaver Database Navigator465 收藏
-
278 收藏
-
343 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习