GLM-4.5V:智谱最新视觉模型发布
时间:2025-08-29 13:03:28 321浏览 收藏
对于一个科技周边开发者来说,牢固扎实的基础是十分重要的,golang学习网就来带大家一点点的掌握基础知识点。今天本篇文章带大家了解《GLM-4.5V:智谱最新视觉推理模型发布》,主要介绍了,希望对大家的知识积累有所帮助,快点收藏起来吧,否则需要时就找不到了!
GLM-4.5V是什么
GLM-4.5V 是由智谱AI最新发布的视觉推理大模型。该模型构建于106B参数规模之上,具备12B激活参数能力,是当前领先的视觉语言模型(VLM)之一。作为GLM-4.1V-Thinking的升级版本,它继承了前代优秀的架构设计,并融合新一代文本基座模型GLM-4.5-Air进行联合训练。在视觉理解与复杂推理方面表现突出,广泛适用于网页前端还原、视觉定位、图像搜索游戏、视频内容分析等多类场景,有望加速多模态技术的落地应用。为方便开发者直观体验其强大能力并构建个性化多模态应用,官方同步开源了一款桌面助手工具,支持实时截屏与录屏功能,结合GLM-4.5V模型可完成代码辅助生成、视频内容解析、游戏策略建议、文档内容解读等多种视觉任务。
 GLM-4.5V的主要功能
GLM-4.5V的主要功能
- 视觉理解与深度推理:能够解析图像和视频内容,执行复杂的视觉推理,如识别物体、判断场景、分析人物关系等。
- 多模态交互能力:支持文本与视觉信息的双向融合处理,例如根据文字生成图像描述,或依据图像生成对应文本。
- 网页前端还原:通过输入网页设计图,自动输出可运行的前端代码,显著提升网页开发效率。
- 图像搜索游戏支持:可在复杂图像环境中完成目标查找与匹配任务,适用于“找不同”或“寻物”类游戏场景。
- 视频内容理解:具备对视频流的分析能力,能提取关键帧信息、生成摘要、检测事件发生时间点等。
- 跨模态内容生成:实现从图像到文本、或从文本到图像的无缝转换,推动多模态内容创作的发展。
GLM-4.5V的技术原理
- 大规模预训练架构:基于106B参数量的模型底座,利用海量图文对数据进行预训练,学习语言与视觉的统一表征。
- 视觉语言融合机制:采用Transformer结构,通过交叉注意力模块实现文本与图像特征的深度融合与交互。
- 高效激活策略:引入12B激活参数机制,在推理过程中动态激活关键参数子集,兼顾性能与计算效率。
- 架构延续与增强:继承自GLM-4.1V-Thinking的成熟结构,结合更先进的GLM-4.5-Air文本模型进行端到端优化训练。
- 多任务适配能力:通过任务微调与结构优化,使模型能高效应对视觉问答、图像描述、视频理解等多种下游任务。
GLM-4.5V的性能表现
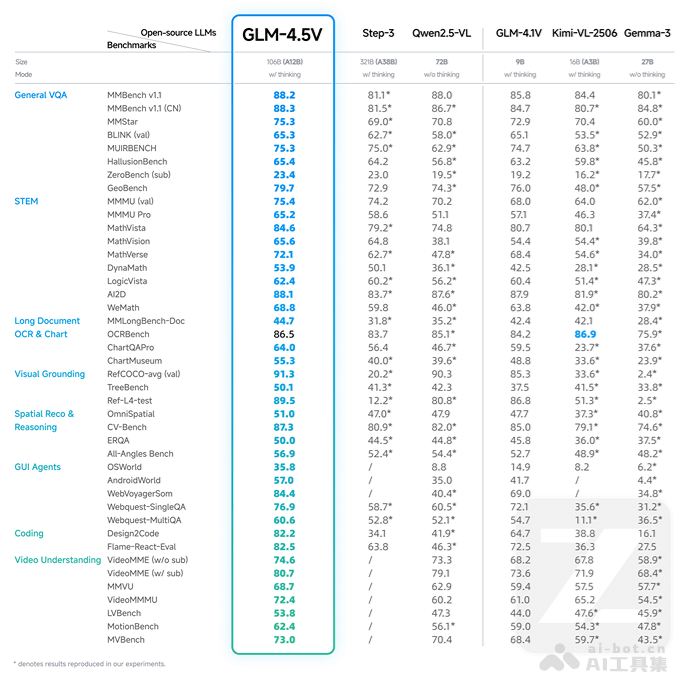
- 通用视觉问答(General VQA):在MMBench v1.1基准测试中取得88.2的高分,处于行业领先水平。
- STEM领域任务:在MathVista测试中得分达84.6,展现出强大的科学与数学图像理解能力。
- 长文档与图表识别(OCR & Chart):于OCRBench测试中获得86.5分,体现其在复杂文档处理中的卓越性能。
- 视觉定位能力(Visual Grounding):在RefCOCO+loc (val)任务中达到91.3的准确率,精准定位图像中的指定对象。
- 空间推理能力:CV-Bench测试得分为87.3,表明其在空间关系理解方面具有优异表现。
- 编程与代码生成:在Design2Code基准上得分82.2,验证其在UI转代码任务中的实用价值。
- 视频理解能力:在VideoMME(无字幕)测试中得分74.6,显示其强大的视频语义解析能力。
 GLM-4.5V的项目地址
GLM-4.5V的项目地址
- GitHub仓库:http://github.com/zai-org/GLM-V/
- HuggingFace模型库:http://huggingface.co/collections/zai-org/glm-45v-68999032ddf8ecf7dcdbc102
- 技术论文:http://github.com/zai-org/GLM-V/tree/main/resources/GLM-4.5V\_technical\_report.pdf
- 桌面助手应用:http://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App
如何使用GLM-4.5V
- 注册与登录:前往 Z.ai 官方网站,使用邮箱完成注册并登录账户。
- 选择模型版本:登录后,在模型选择下拉菜单中选定GLM-4.5V。
- 体验核心功能:
- 网页前端还原:上传网页设计截图,模型将自动生成HTML/CSS/JS代码。
- 视觉推理任务:上传图片或视频,模型将进行内容解析、对象识别与场景理解。
- 图寻游戏辅助:上传目标图像,模型可在复杂背景中定位相似区域或目标。
- 视频内容分析:上传视频文件,模型将提取关键信息并生成摘要或事件报告。
GLM-4.5V的API调用价格
- 输入价格:2 元 / 百万tokens
- 输出价格:6 元 / 百万tokens
- 响应速度:可达 60–80 tokens/秒,满足实时交互需求
GLM-4.5V的应用场景
- 网页前端快速开发:上传UI设计图即可获得前端代码,大幅提升开发效率。
- 智能视觉问答系统:用户上传图片并提问,模型返回基于图像内容的精确回答,适用于教育辅导、客服机器人等场景。
- 图像搜索与定位应用:在监控画面或零售场景中快速识别目标图像,助力安防与智能零售。
- 视频内容智能分析:用于视频平台的内容摘要生成、事件检测、推荐优化及自动剪辑。
- 图像描述生成服务:为图像生成详细文字描述,帮助视障人士获取视觉信息,也适用于社交媒体内容增强。
本篇关于《GLM-4.5V:智谱最新视觉模型发布》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于科技周边的相关知识,请关注golang学习网公众号!

相关阅读
更多>
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
最新阅读
更多>
-
222 收藏
-
197 收藏
-
331 收藏
-
259 收藏
-
433 收藏
-
215 收藏
-
296 收藏
-
334 收藏
-
233 收藏
-
295 收藏
-
118 收藏
-
363 收藏
课程推荐
更多>
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习