腾讯无训练优化:120元抵7万微调效果
时间:2025-10-25 16:09:34 437浏览 收藏
**腾讯无训练优化技术:120元成本媲美7万元微调效果** 还在为大模型微调的高昂成本发愁?腾讯AI实验室创新推出“无训练组相对策略优化”(Training-Free GRPO)技术,无需参数微调,仅通过构建外部知识库即可显著提升模型性能,效果堪比传统微调,而成本却大幅降低。这项技术通过将经验转化为token层级的先验指导信息,在不改动模型内部参数的前提下实现优化,尤其在数学推理和网络搜索等复杂任务中表现出色。实验证明,GRPO优化后的模型在数学竞赛和网络搜索任务中准确率显著提升,且仅需少量样本,成本仅为传统微调的零头,单模型优化成本仅需约120元人民币,而传统微调则高达约7万元。这一突破性技术为AI模型优化开辟了新路径,降低了大模型应用门槛,为算力有限的中小企业和科研单位带来了福音。
腾讯AI实验室近日推出了一项名为“无训练组相对策略优化”(Training-Free GRPO)的创新模型优化技术。该方法摒弃了传统的参数微调路径,转而通过构建外部知识库来实现模型能力的增强,在显著降低训练开销的同时,性能表现可媲美高成本的微调方案。
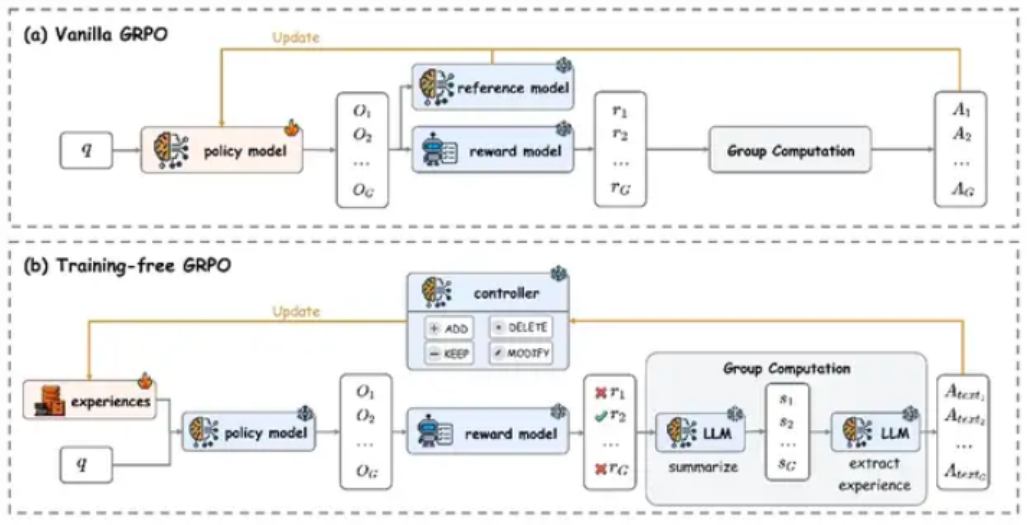
其核心技术理念在于将积累的经验转化为token层级的先验指导信息,从而在不改动大模型内部参数的前提下完成有效优化。研究团队在DeepSeek-V3.1-Terminus模型上的实验证明,该方法在数学推理与网络搜索等复杂任务中均展现出卓越成效。
从实现机制来看,传统大语言模型在涉及外部工具调用的任务中往往存在局限。而Training-Free GRPO通过冻结模型主干参数,仅维护一个动态更新的外部经验库,实现了能力跃升。这一架构不仅极大减少了计算资源消耗,还提升了模型在不同任务间的迁移适应能力。
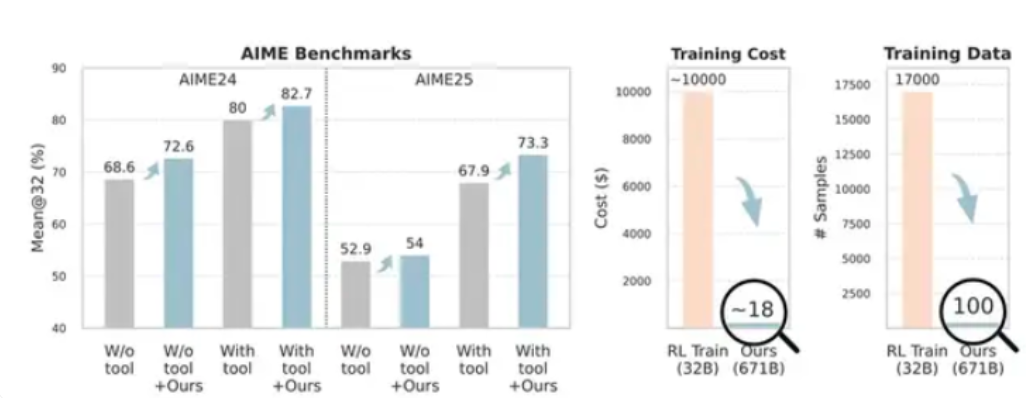
具体实验结果充分验证了该方法的优势。在AIME24和AIME25两项数学竞赛级评测中,采用Training-Free GRPO优化后的模型准确率分别由80%和67.9%提升至82.7%和73.3%。尤为突出的是,这一进步仅依赖于100个跨领域样本,相比之下,常规强化学习方法通常需数千样本才能达到相近水平,且训练成本常超过数万美元。
在网络搜索任务中,该技术同样表现亮眼,Pass@1指标从63.2%上升至67.8%。多项测试一致表明,Training-Free GRPO能够在极低资源投入下,持续稳定地提升模型性能。
在成本方面,官方披露的数据更具冲击力:使用Training-Free GRPO优化单个模型的成本约为120元人民币,而传统参数微调则平均需要约7万元的算力支出。这种巨大差异主要源于新方法无需执行梯度反向传播和权重更新等高耗能操作。
此次发布为AI模型优化开辟了全新路径。尤其对算力有限的中小企业及科研单位而言,这种高效低成本的技术显著降低了大模型落地应用的门槛。然而也需注意到,当前成果主要集中于数学解题与信息检索等特定场景,其广泛适用性仍有待在更多任务中进一步检验。
理论要掌握,实操不能落!以上关于《腾讯无训练优化:120元抵7万微调效果》的详细介绍,大家都掌握了吧!如果想要继续提升自己的能力,那么就来关注golang学习网公众号吧!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
科技周边 · 业界新闻 | 3小时前 | postgresql · 数据库升级 · Beta测试 · pg_upgrade · 数据库升级 兼容性测试 PostgreSQL 19 Beta 2 pg_upgrade pg_dump423 收藏
-
314 收藏
-
科技周边 · 业界新闻 | 1天前 | 云原生 · Etcd · kubernetes · 分布式系统 · 业界新闻 · Kubernetes etcd 3.7.0 RangeStream etcd升级 v2store etcdctl230 收藏
-
科技周边 · 业界新闻 | 1天前 | 依赖 · Node.js · javascript · 业界新闻 · 版本升级 · 升级 ReadFile 回归测试 Node.js 26.4.0 package maps139 收藏
-
科技周边 · 业界新闻 | 1天前 | 运维 · 业界新闻 · 安全更新 · Go 1.26.5 · crypto/tls · crypto/tls 安全更新 业界新闻 Go 1.26.5 Go 1.25.12 Go升级237 收藏
-
300 收藏
-
科技周边 · 业界新闻 | 1星期前 | 开发工具 · github copilot · vs code · AI编程 · 业界新闻 · VS Code AI编程 Autopilot GitHub Copilot 模型选择 并行会话 成本可见187 收藏
-
科技周边 · 业界新闻 | 1星期前 | WEB开发 · chrome · 业界新闻 · 前端工程 · 浏览器特性 · 滚动事件 Web平台 Chrome 151 Beta WheelEvent momentum425 收藏
-
198 收藏
-
424 收藏
-
科技周边 · 业界新闻 | 2星期前 | github · 业界新闻 · 供应链安全 · 许可证合规 · GitHub 供应链安全 开源许可证合规 Dependency Review Ruleset 企业研发治理116 收藏
-
科技周边 · 业界新闻 | 2星期前 | Google Cloud · 业界新闻 · 网络事件 · 云服务排查 · 云服务 Google Cloud 网络延迟 业界新闻 VPC Media CDN Hybrid Connectivity468 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习