大模型谁最靠谱?SuperCLUE文心X1.1登顶
时间:2025-11-16 16:36:35 306浏览 收藏
想知道哪个大模型最可靠?最新SuperCLUE测评结果出炉!文心X1.1以75.51分的优异成绩荣登国产大模型榜首,力压DeepSeek和Hunyuan,在中文精确指令遵循能力上展现出卓越实力。本次测评涵盖GPT-5、Gemini-2.5 Pro等国内外10款主流大模型,SuperCLUE-CPIF基准专注于考察模型在复杂中文语境下的指令执行精准度。文心X1.1基于文心4.5版本训练,采用迭代式混合强化学习架构,在通用任务、智能体任务表现和整体性能上都得到显著提升。尤其在高难度写作和长流程任务处理中,文心X1.1表现出强大的理解能力、逻辑推理能力和自主性,充分体现了百度在“芯片-框架-模型-应用”全栈自研技术体系上的领先优势。想了解更多细节?点击下载源码,一探究竟!
10月21日,中文精确指令遵循测评基准SuperCLUE-CPIF正式上线,文心X1.1以75.51分位列国产大模型榜首,在任务类型与指令数量两大维度的评估中均居国内首位,展现出其在真实生产场景中的突出应用潜力。
此次测评共纳入包括GPT-5(high)、DeepSeek-V3.2-Exp-Thinking、Claude-Sonnet-4.5-Reasoning、Gemini-2.5-Pro在内的10款国内外主流大模型。SuperCLUE-CPIF聚焦于大型语言模型(LLM)在中文语境下对复杂、多约束指令的精准执行能力,核心考察模型能否将自然语言指令准确转化为完全符合各项要求的具体输出。
测评结果表明,在国产大模型阵营中,文心X1.1以75.51分领先,紧随其后的是得分为73.98分的DeepSeek-V3.2-Exp-Thinking和65.82分的Hunyuan-T1-20250822,分别位列第二和第三。
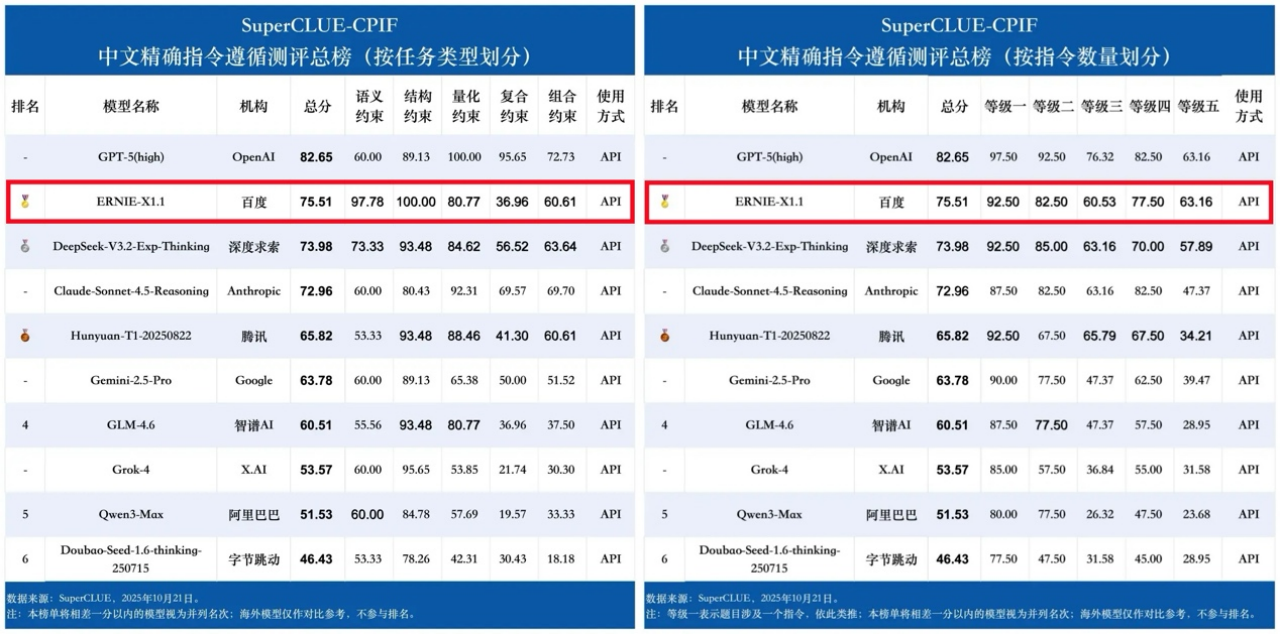
SuperCLUE-CPIF中文精确指令遵循测评总榜,文心X1.1位居国内第一
文心大模型X1基于文心4.5版本训练而成,是一款具备深度推理能力的思考型模型。升级至X1.1后,采用了迭代式混合强化学习训练架构:一方面通过混合强化学习同步提升通用任务与智能体任务表现;另一方面借助自蒸馏数据的循环生成与再训练,持续优化整体性能。
据悉,文心X1.1在应对高难度写作任务时,不仅能调用内在知识库或联网搜索获取准确信息,还能深入理解用户创意意图与具体需求,最终生成事实无误、结构清晰、逻辑严密且语言优美的内容。
在更复杂的长流程任务中,例如处理共享单车平台中不同等级用户提出的多样化问题,并叠加用户情绪状态等多重因素时,文心X1.1能够严格遵循业务逻辑进行规划,主动调用相关工具,并结合情感识别快速响应,实现全流程闭环服务,表现出高度自主性与完整性。
作为国内最早布局大模型研发与落地的企业之一,百度依托“芯片-框架-模型-应用”全栈自研技术体系,持续推进文心大模型的能力升级。得益于飞桨与文心的深度协同优化,文心大模型在能力扩展与运行效率方面持续提升。根据此前公开数据,相较于X1版本,文心X1.1在事实准确性上提升了34.8%,指令遵循能力提升12.5%,智能体行为能力提升9.6%。
源码地址:点击下载
到这里,我们也就讲完了《大模型谁最靠谱?SuperCLUE文心X1.1登顶》的内容了。个人认为,基础知识的学习和巩固,是为了更好的将其运用到项目中,欢迎关注golang学习网公众号,带你了解更多关于的知识点!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
414 收藏
-
375 收藏
-
134 收藏
-
430 收藏
-
科技周边 · 业界新闻 | 4天前 | 业界新闻 · Cloudflare · AI Gateway · Spend Limits · AI成本 · Cloudflare AI Gateway Spend Limits AI成本治理 AI预算 模型降级495 收藏
-
科技周边 · 业界新闻 | 4天前 | Node.js · javascript · 安全版本 · 运行时 · 升级排查 · 业界新闻 Node.js安全版本 Node.js 26.3.0 运行时升级 JavaScript安全308 收藏
-
科技周边 · 业界新闻 | 6天前 | devops · CI/CD · gitHub actions · 业界新闻 · 自托管Runner · DevOps CI/CD GitHub Actions self-hosted runner Runner升级431 收藏
-
科技周边 · 业界新闻 | 6天前 | github · gitHub actions · 业界新闻 · AI代理 · GitHub AI代理 GitHub Actions Agentic Workflows CI分析 Issue分流 工程自动化354 收藏
-
科技周边 · 业界新闻 | 1星期前 | 安全 · CI/CD · gitHub actions · 业界新闻 · 开发者工具 · 代码审查 供应链安全 业界新闻 GitHub Actions 机器人PR CI安全473 收藏
-
214 收藏
-
345 收藏
-
356 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习