AI早报 | 文本、图像、音视频、3D互相生成是什么体验?
来源:搜狐
时间:2023-05-26 16:58:59 168浏览 收藏
编程并不是一个机械性的工作,而是需要有思考,有创新的工作,语法是固定的,但解决问题的思路则是依靠人的思维,这就需要我们坚持学习和更新自己的知识。今天golang学习网就整理分享《AI早报 | 文本、图像、音视频、3D互相生成是什么体验?》,文章讲解的知识点主要包括,如果你对科技周边方面的知识点感兴趣,就不要错过golang学习网,在这可以对大家的知识积累有所帮助,助力开发能力的提升。

当地时间5月9日,Meta宣布开源了一种可以将可以横跨6种不同模态的全新AI模型ImageBind,包括视觉(图像和视频形式)、温度(红外图像)、文本、音频、深度信息、运动读数(由惯性测量单元或IMU产生)。目前,相关源代码已托管至GitHub。
何为横跨6种模态?
ImageBind以视觉为中心,能够在六种不同的模式之间自由转换和理解。Meta展示了一些案例,如听到狗叫画出一只狗,同时给出对应的深度图和文字描述;如输入鸟的图像+海浪的声音,得到鸟在海边的图像。
相比 Midjourney、Stable Diffusion 和 DALL-E 2 这样将文字与图像配对的图像生成器,ImageBind 更像是广撒网,可以连接文本、图像/视频、音频、3D 测量(深度)、温度数据(热)和运动数据(来自 IMU),而且它无需先针对每一种可能性进行训练,直接预测数据之间的联系,类似于人类感知或者想象环境的方式。

研究者表示 ImageBind 可以使用大规模视觉语言模型(如 CLIP)进行初始化,从而利用这些模型的丰富图像和文本表示。由此可知,ImageBind 可以适用于多种模态和任务,且只需要进行少量的训练。
ImageBind 是 Meta 致力于创建多模态 AI 系统的一部分,从而实现从所有相关类型数据中学习。随着模态数量的增加,ImageBind 为研究人员打开了尝试开发全新整体性系统的闸门,例如结合 3D 和 IMU 传感器来设计或体验身临其境的虚拟世界。此外它还可以提供一种探索记忆的丰富方式,即组合使用文本、视频和图像来搜索图像、视频、音频文件或文本信息。
该模型目前只是一个研究项目,没有直接的消费者和实际应用,但是它展现了生成式 AI 在未来能够生成沉浸式、多感官内容的方式,也表明了 Meta 正在以与 OpenAI、Google 等竞争对手不同的方式,趟出一条属于开源大模型的路。
最终,Meta 认为 ImageBind 这项技术最终会超越目前的六种“感官”,其在博客上说道,“虽然我们在当前的研究中探索了六种模式,但我们相信引入连接尽可能多的感官的新模式——如触觉、语音、嗅觉和大脑 fMRI 信号——将使更丰富的以人为中心的人工智能模型成为可能。”
ImageBind的用途
如果说 ChatGPT 可以充当搜索引擎、问答社区,Midjourney 可以被用来当画画工具,那么用 ImageBind 可以做什么?
根据官方发布的 Demo 显示,它可以直接用图片生成音频:
也可以音频生成图片:
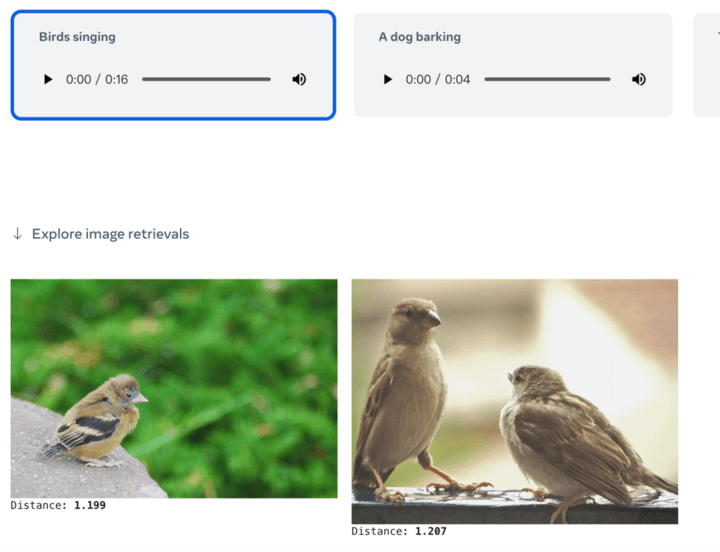
亦或者直接给一个文本,就可以检索相关的图片或者音频内容:
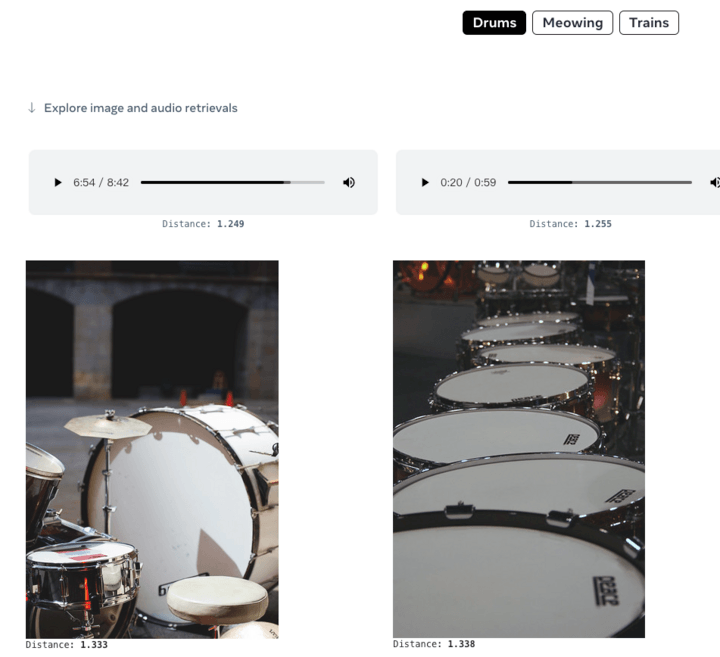
也可以给出音频,生成相应的图像:
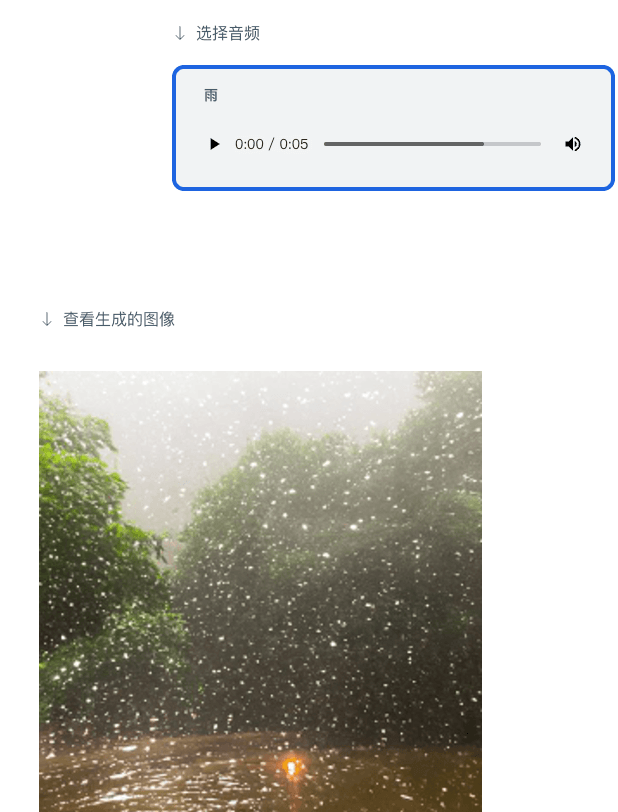
正如上文所述, ImageBind 给出了未来生成式 AI 系统可以以多模态呈现的方式,同时,结合 Meta 内部的虚拟现实、混合现实和元宇宙等技术和场景结合。用 ImageBind 这样的工具会在无障碍空间打开新的大门,譬如,生成实时多媒体描述来帮助有视力或听力障碍的人更好地感知他们的直接环境。
关于多模态学习还有很多待发掘的内容。目前,人工智能研究领域还没有成功地量化较大模型中的扩展行为并理解其应用。ImageBind是向图像生成和检索领域的严格评估和展示迈出的一步。
作者:Ballad
来源:第一电动网(www.d1ev.com)
今天关于《AI早报 | 文本、图像、音视频、3D互相生成是什么体验?》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
191 收藏
-
299 收藏
-
科技周边 · 人工智能 | 5天前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-
453 收藏
-
202 收藏
-
419 收藏
-
170 收藏
-
475 收藏
-
科技周边 · 人工智能 | 1星期前 | 人工智能 · tracing · ai agent · 可观测性 · 工具调用 · 可观测性 AI Agent Tracing 工具调用 OpenAI Agents SDK292 收藏
-
379 收藏
-
394 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习