Meta 开源语音 AI 模型支持 1,100 多种语言
来源:51CTO.COM
时间:2023-05-27 13:42:17 106浏览 收藏
学习科技周边要努力,但是不要急!今天的这篇文章《Meta 开源语音 AI 模型支持 1,100 多种语言》将会介绍到等等知识点,如果你想深入学习科技周边,可以关注我!我会持续更新相关文章的,希望对大家都能有所帮助!
自从ChatGPT火爆以来,各种通用的大型模型层出不穷,GPT4、SAM等等,本周一Meta 又开源了新的语音模型MMS,这个模型号称支持4000多种语言,并且发布了支持1100种语言的预训练模型权重,最主要的是这个模型不仅支持ASR,还支持TTS,也就是说不仅可以语音转文字,还可以文字转语音。
因为以前对语音方面没有研究,所以我就查阅了一下资料,世界上一共有 7,000 多种语言(我一直以为只有几百),目前的语音识别技术目前仅能覆盖100多种,其实我觉得100多种已经够用了,当然如果有特殊的研究需要那要另说。
Facebook (Meta) AI 的最新大型多语言语音 (MMS) 项目可以为 1,100 多种语言提供语音转文本、文本转语音等功能。官网的blog中特别提到了Tatuyo语,该语言仅有数百人使用,这座新模型的规模是现有模型的10倍。这其实对于日常来说没什么用,但是对于研究来说这是一个很好的例子,因为只有几百人如何找到并有效的提炼数据集呢?
Meta 与 OpenAI 的 Whisper 做了详细的对比,在数据上训练的模型实现了一半的单词错误率,并且训练数据更少:
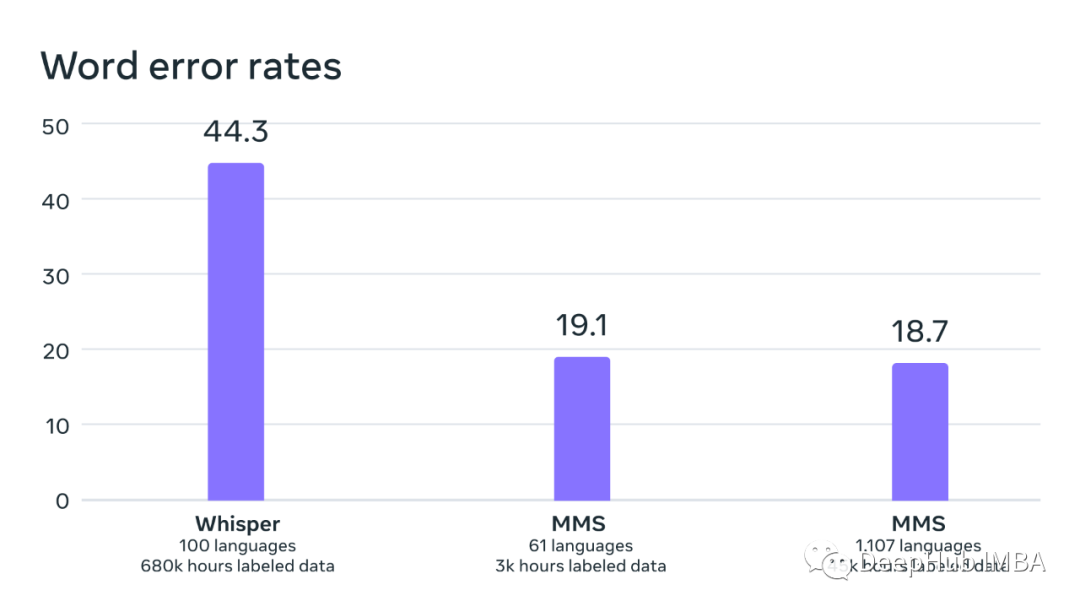
可以看到它的训练数据只有45k 小时的标注数据,要比Whisper少10倍,而语言支持也多了10倍,这是一个大的提高。在blog中还特意提到了使用了 《圣经》这种流传广泛,翻译语种多的内容作为数据集,我觉得这是一个很好方向。
Wav2vec 2.0's self-supervised speech representation learning technology was also leveraged by the MMS project.。在 1,400 种语言的大约 500,000 小时的语音数据上进行自监督的训练,明显减少了对标记数据的依赖。针对不同的语音任务,可以微调生成的模型,例如跨语言语音识别和语音语言识别。
Whisper 的效果对于我来说就已经非常好了,我也一直在使用他做为语言转文字的工具,如果MMS的效果更好,那对于我们来说简直太棒了,并且MMS还支持 language identification (LID) 也就说可以自动识别所说的语言,但是经过我的测试,这个对于支持这么多种语言的模型来说有一个致命的错误,就是转录或错误解释可能会导致冒犯性或不准确的语言。
还记得大张伟吗,越是准确的模型越会出问题:

The emergence of such a multilingual speech model will break down language barriers, enabling people from every corner of the world to communicate normally through voice.。还记得META烂尾的VR和AR应用吗,我觉得MMS应该是它们VR的一个子项目,VR烂尾很正常,但是这个MMS会为我们带来更多的进步。
最后地址,里面有预训练模型下载和安装方法:
https://github.com/facebookresearch/fairseq/tree/main/examples/mms
今天带大家了解了的相关知识,希望对你有所帮助;关于科技周边的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习