AI内容易识别,情感表达待加强
时间:2025-12-07 08:06:33 333浏览 收藏
一分耕耘,一分收获!既然打开了这篇文章《AI生成内容易识别,情感表达仍需提升》,就坚持看下去吧!文中内容包含等等知识点...希望你能在阅读本文后,能真真实实学到知识或者帮你解决心中的疑惑,也欢迎大佬或者新人朋友们多留言评论,多给建议!谢谢!
苏黎世大学、阿姆斯特丹大学、杜克大学以及纽约大学的联合研究团队近期公布了一项关于大语言模型在社交媒体内容生成方面表现的研究成果。研究发现,当前AI生成的社交平台帖子普遍存在可识别性问题,人类用户能够以高达70%至80%的准确率将其与真人发布的内容区分开来,显著高于随机判断的概率。
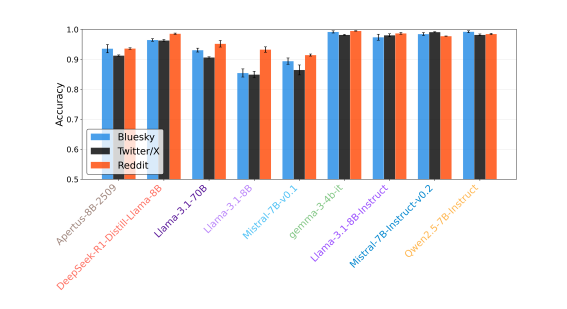
该研究涵盖了九个主流大语言模型,包括Apertus、DeepSeek、Gemma、Llama、Mistral和Qwen等,评估它们在Bluesky、Reddit和X三大社交平台上的文本生成能力。
分析结果显示,AI生成内容在“毒性评分”上呈现出明显特征,成为人类辨别其来源的关键线索之一。例如,当一条帖子引发极具讽刺意味或情绪强烈的评论时,这类互动更可能来自真实用户而非AI。这反映出AI在模拟真实社交语境中的局限性。
尽管大模型已能较好地复制网络对话的基本结构,但在表达自然情感和即兴反应方面仍存在明显短板。研究指出,真挚、自发的情感流露是人类交流的核心特质,而这一点恰恰是当前AI难以企及的。特别是在表达积极情绪(如在马斯克旗下的X平台上)或涉及敏感话题(如Reddit上的政治讨论)时,AI的表现尤为生硬和不自然。
整体而言,各模型在模仿X平台的内容风格时相对成功,而在Bluesky上的表现一般,面对Reddit则最为吃力——后者因其社区文化多样、对话规则复杂,对AI构成了更高挑战。值得注意的是,部分未经人类反馈微调(non-instruct fine-tuned)的原始模型反而展现出更强的隐蔽性,暗示过度优化可能导致输出风格趋于同质化,进而暴露其非人类身份。
终于介绍完啦!小伙伴们,这篇关于《AI内容易识别,情感表达待加强》的介绍应该让你收获多多了吧!欢迎大家收藏或分享给更多需要学习的朋友吧~golang学习网公众号也会发布科技周边相关知识,快来关注吧!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
科技周边 · 业界新闻 | 4天前 | 开发工具 · github copilot · vs code · AI编程 · 业界新闻 · VS Code AI编程 Autopilot GitHub Copilot 模型选择 并行会话 成本可见187 收藏
-
科技周边 · 业界新闻 | 5天前 | WEB开发 · chrome · 业界新闻 · 前端工程 · 浏览器特性 · 滚动事件 Web平台 Chrome 151 Beta WheelEvent momentum425 收藏
-
198 收藏
-
424 收藏
-
科技周边 · 业界新闻 | 1星期前 | github · 业界新闻 · 供应链安全 · 许可证合规 · GitHub 供应链安全 开源许可证合规 Dependency Review Ruleset 企业研发治理116 收藏
-
科技周边 · 业界新闻 | 1星期前 | Google Cloud · 业界新闻 · 网络事件 · 云服务排查 · 云服务 Google Cloud 网络延迟 业界新闻 VPC Media CDN Hybrid Connectivity468 收藏
-
415 收藏
-
科技周边 · 业界新闻 | 1星期前 | css · 业界新闻 · Web平台 · Safari · 表单控件 · CSS select 前端表单 Safari 27 beta Customizable Select Web平台239 收藏
-
科技周边 · 业界新闻 | 2星期前 | gitHub actions · 业界新闻 · CI治理 · 供应链安全 GitHub Actions CI安全 工作流触发 pull_request_target419 收藏
-
107 收藏
-
414 收藏
-
375 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习