DeepSeek-OCR2技术解析与视觉因果流揭秘
时间:2026-02-15 20:45:44 474浏览 收藏
DeepSeek-OCR 2 革命性地突破传统OCR局限,首次引入仿生“视觉因果流”技术——其自研DeepEncoder V2不再僵化扫描图像,而是像人类一样依语义逻辑动态重排视觉Token,通过双分支注意力机制(全局感知+因果推理)精准解析表格、公式、双栏等复杂版式;这一兼具结构理解力与阅读逻辑性的创新架构,不仅大幅提升OCR精度与鲁棒性,更指向一个统一全模态智能的未来:让图像、音频、文本在同一体系下被真正“读懂”,而非仅被“看到”。
深度求索(DeepSeek)最新推出开源 OCR 模型:DeepSeek-OCR 2,并首次集成全新视觉编码器——DeepEncoder V2。该编码器摒弃了传统模型固化的“左上→右下”光栅式图像扫描范式,转而借鉴人类视觉认知机制,构建出更具语义感知能力的「因果流(Causal Flow)」处理逻辑。

项目主页:https://github.com/deepseek-ai/DeepSeek-OCR-2
模型权重:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
技术论文:https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek\_OCR2\_paper.pdf
据官方介绍,DeepEncoder V2 能够依据图像内容语义动态调整视觉 Token 的排列顺序,而非拘泥于物理空间位置的线性遍历。这一设计更贴近人类在观察复杂场景时“依逻辑线索跳跃式聚焦”的真实视觉行为。
传统多模态大模型(VLMs)普遍采用固定方向的光栅扫描策略解析图像,这种机械式的处理方式与人类灵活、内容驱动的视觉注意机制存在本质差异;尤其在面对表格结构、数学公式、双栏排版等非线性布局时,易导致上下文错位与语义误读。
而 DeepSeek-OCR 2 正是依托 DeepEncoder V2,赋予模型一种新型的「视觉因果流(Visual Causal Flow)」能力——即根据图像内在结构与任务需求,智能重组织视觉 Token 序列。
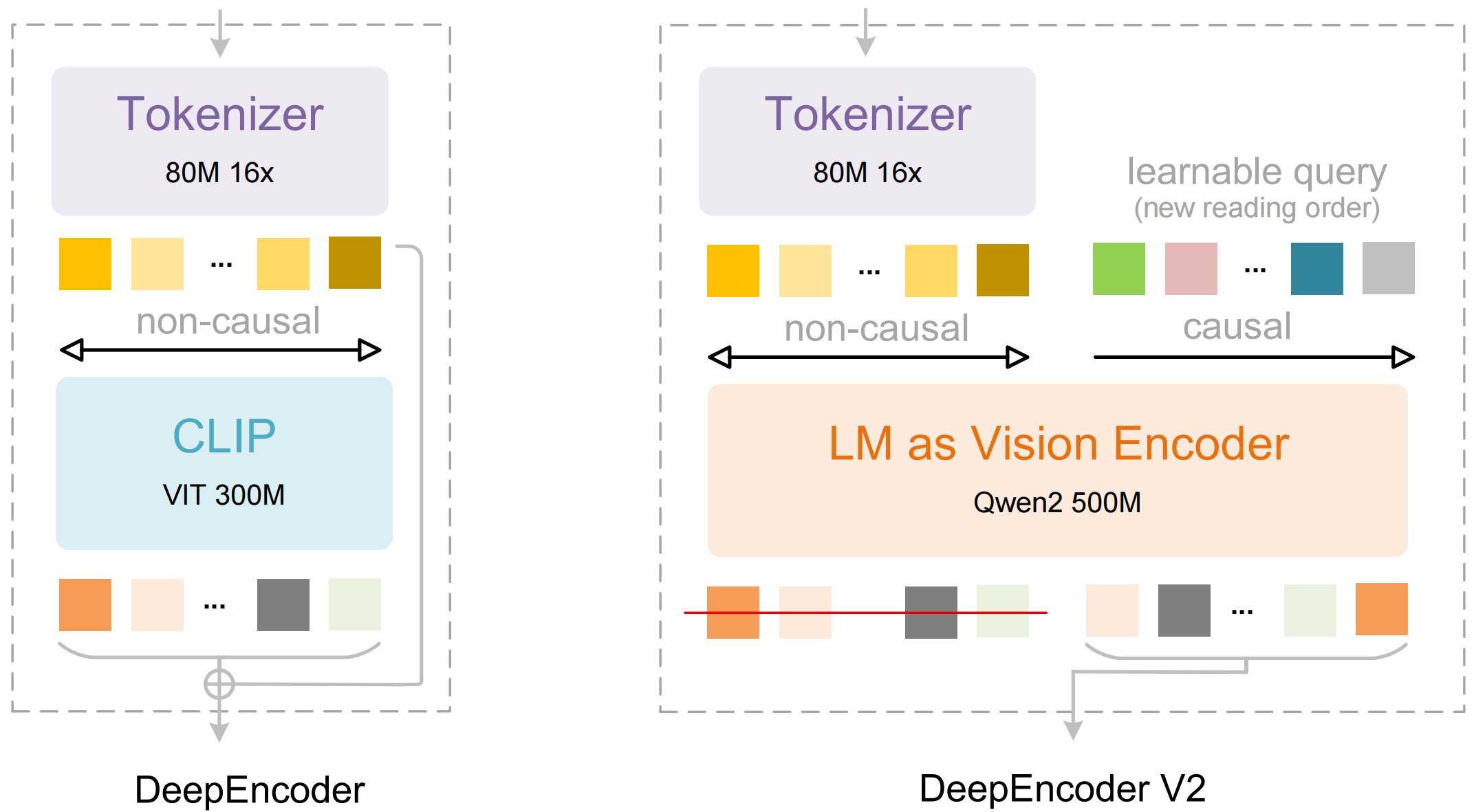
该架构创新性地引入定制化注意力掩码(Attention Mask)机制:
- 视觉 Token 分支:维持双向注意力,保障模型具备类 CLIP 的全局感受野,充分建模图像整体语义;
- 因果流 Token 分支:启用因果注意力(类似纯 Decoder 架构的 LLM),确保每个 Token 仅能关注其前置序列,从而支撑有序推理与动态重排序。
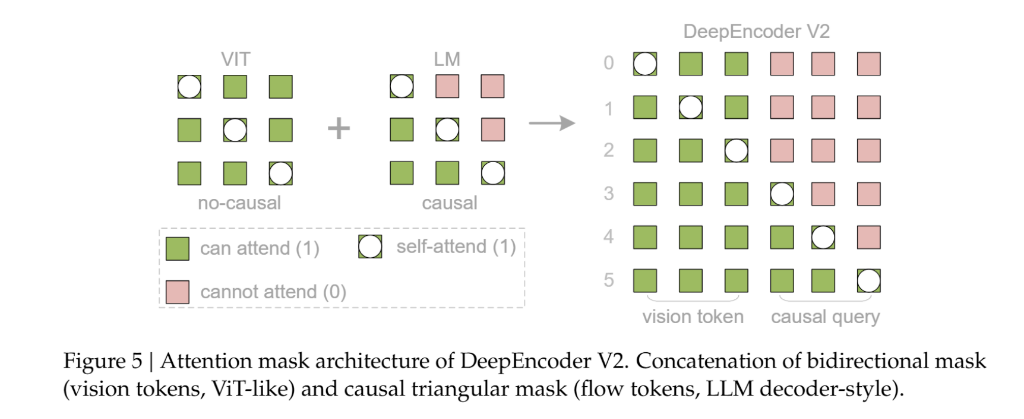
由此,视觉 Token 保留跨区域信息聚合能力,因果流 Token 则专注构建符合阅读逻辑的结构化表示。模型采用多尺度裁剪策略(Multi-crop strategy),适配不同分辨率输入,最终送入语言模型的重排序视觉 Token 数量介于 256 至 1120 之间。
DeepSeek 团队指出,这一设计为构建统一全模态编码器提供了关键思路:未来有望通过可学习的模态特定查询(modality-specific learnable queries),在同一套参数体系下高效完成图像、音频与文本的联合表征与压缩。DeepSeek-OCR 2 所提出的“双级联一维因果推理器”架构,将二维理解解耦为“阅读逻辑推理”与“视觉任务推理”两个协同子过程,或将成为通向真正二维语义推理的重要技术路径。
延伸阅读
DeepSeek 发布全新开源 OCR 模型 DeepSeek-OCR
受 DeepSeek-OCR 启发的新范式:所有输入 LLM 的信息,本质上都应以图像形式呈现
今天带大家了解了的相关知识,希望对你有所帮助;关于科技周边的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~

-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
285 收藏
-
270 收藏
-
370 收藏
-
488 收藏
-
155 收藏
-
134 收藏
-
158 收藏
-
218 收藏
-
105 收藏
-
365 收藏
-
226 收藏
-
377 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习