Meta开源唇语翻译系统,支持6种语言的模型识别和本地部署,适用于所有人
来源:51CTO.COM
时间:2023-08-28 21:53:43 102浏览 收藏
今日不肯埋头,明日何以抬头!每日一句努力自己的话哈哈~哈喽,今天我将给大家带来一篇《Meta开源唇语翻译系统,支持6种语言的模型识别和本地部署,适用于所有人》,主要内容是讲解等等,感兴趣的朋友可以收藏或者有更好的建议在评论提出,我都会认真看的!大家一起进步,一起学习!
大家是否还记得年初在全网引起轰动的反黑大剧《狂飙》?最后几集因为导演对剧情进行了删改,导致演员的嘴型和台词完全不匹配的情况
有一些懂唇语的铁杆剧迷,为了能够欣赏到原汁原味的剧情,他们直接开始进行翻译工作

重写后的内容:来源:娱乐资讯
Meta最近发布了一个名为MuAViC的AI语音-视频识别系统,它让我们只需动动手指,就能理解无声人物说了什么,并且能够准确识别嘈杂背景中特定人物的语音
Meta使用TED/TEDx的视频和音频素材,创建了MuAViC数据集。该数据集包含了1200小时的文本、语音和视频素材,涵盖了9种语言,并且支持英语与其他6种语言之间的双向翻译
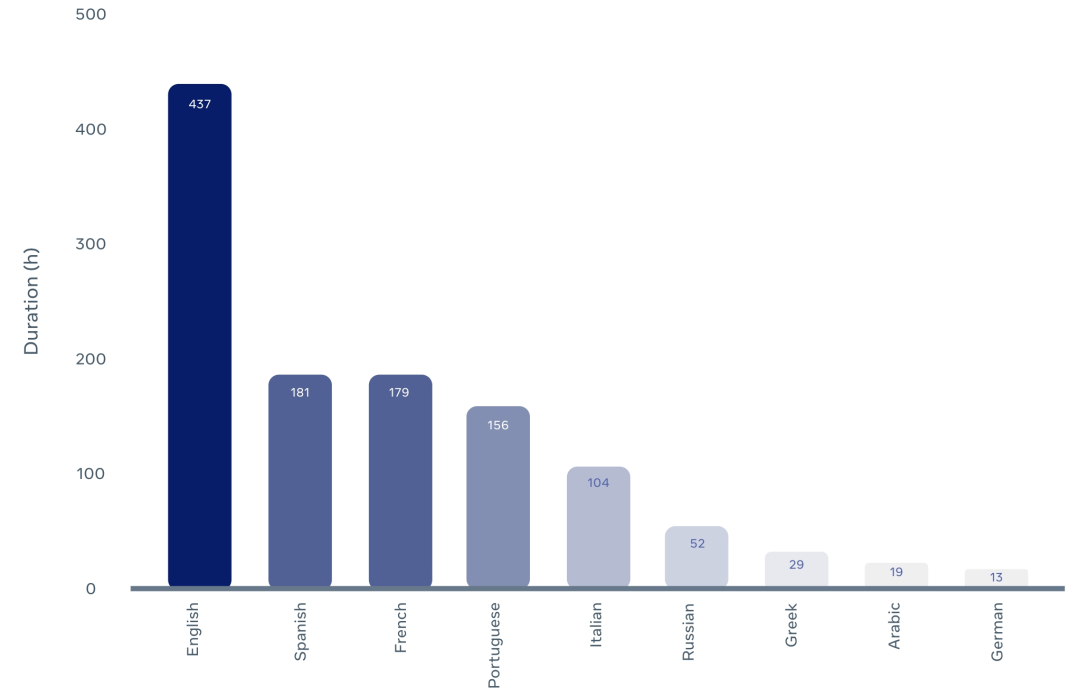
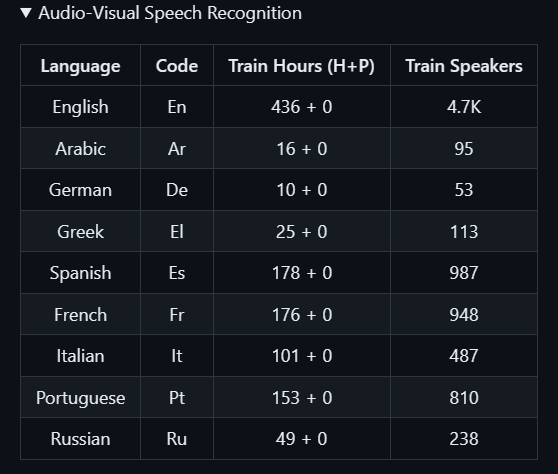
语音识别数据的详细内容包括:
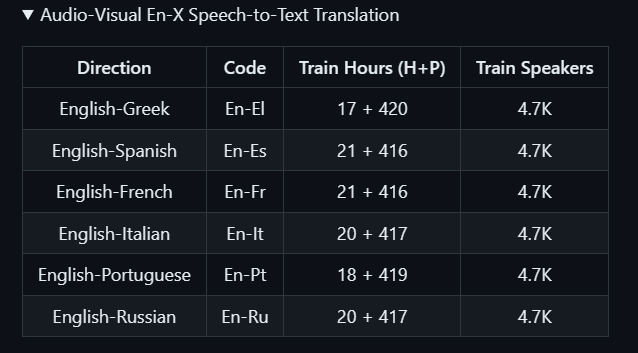
具体包括将英语翻译成六种不同的语言的素材
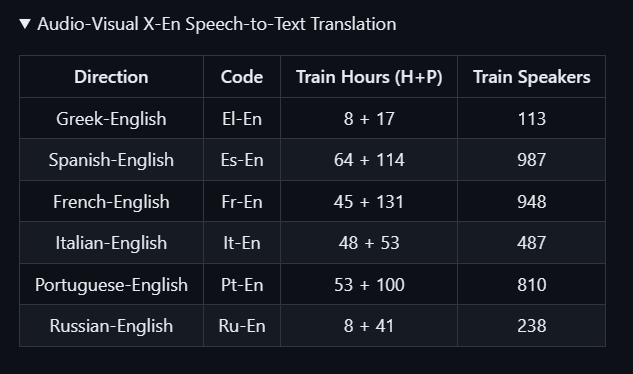
具体包括以下6种语言到英语的翻译素材:
论文
对于这个系统,Mate的研究人员还发表了一篇论文,介绍了它与现有的最先进技术的对比

需要重写的内容是:https://arxiv.org/pdf/2303.00628.pdf
视听语料库的收集
需要进行重新编写的内容是:中文语料收集
研究人员在处理英语语料时,重新利用了LRS3-TED中的视听数据,并按照原始数据进行了拆分
研究人员通过对LRS3-TED的转录与TED2020的原文进行匹配,从TED2020的机器翻译语料库中找到了这些会谈的人工翻译
将匹配的LRS3-TED示例与TED2020中相应的目标句子配对,以获得翻译标签
为了确保最佳准确性,研究人员对开发集和测试集示例进行了精确的文本匹配
为了提高训练集的匹配召回率,研究人员开发了一种模糊文本匹配策略:如果句对双方包含相同数量的句段,他们首先用标点符号分割TED2020源句和目标句
为了规范TED2020和LRS3-TED文本,我们需要进行一些步骤。首先,我们需要去除标点符号和将所有字母转换为小写。这样可以统一文本的格式,使其更易于处理和分析
最后,我们将在两个语料库之间进行准确的文本匹配
研究人员在处理TED2020中没有匹配的LRS3-TED训练集示例时,决定从机器翻译模型M2M-100 418M中获得伪翻译标签。为此,他们采用了默认的解码超参数方法
非英语语料的收集
为了处理非英语语料,研究人员采用了之前研究中收集的mTEDx纯音频数据、转录和文本翻译。他们还按照mTEDx的方式对数据进行了拆分
我们会提取原始录音的视频轨迹,并将经过处理的视频数据与音频数据对齐,形成视听数据,类似于LRS3-TED
虽然mTEDx中的所有音频数据都已转录,但其中只有一个子集进行了翻译。重新写成:尽管mTEDx的所有音频数据都已经转录,但只有其中的一部分进行了翻译
研究人员从M2M-100 418M中获取伪翻译标签,以便在未翻译的训练集示例中使用默认解码超参数
实验
需要重新编写的内容是:实验设置
研究人员在研究视听语音识别(AVSR)和视听语音翻译(AVST)时,采用了英语AV-HuBERT大型预训练模型。该模型是通过结合LRS3-TED和VoxCeleb2中的英语部分进行训练而得到的
研究人员根据AV-HuBERT论文的方法微调超参数,但与此不同的是,他们将双语模型微调为30K次更新,将多语言AVSR模型微调为90K次更新。研究人员还分别冻结了X-En AVST和En-X AVST模型的第一个4K和24K次更新的预训练编码器
需要进行重新编写的内容是:AVSR测试
在宁静的环境中
研究人员对AVSR模型进行了评估,分别在纯音频("A")和视听("AV")模式下进行。在纯音频模式下,模型仅利用音频进行微调和推理;而在视听模式下,模型同时利用音频和视觉进行微调和推理
根据表1所示,英语 AVSR 模型的测试误码率分别为 2.5 和 2.3
研究人员对非英语AVSR进行了重新编写。他们对预先训练好的英语AVHuBERT模型进行了微调,微调的方式可以是对每种语言分别进行微调(共有8种单语模型),也可以是对所有8种非英语语言进行联合微调(多语模型)
请参考下表2以获取测试误码率数据
研究人员发现,在视听模式下,他们的单语AVSR模型的WER平均降低了52%,比同类ASR基线(Transformer,单语)表现更好
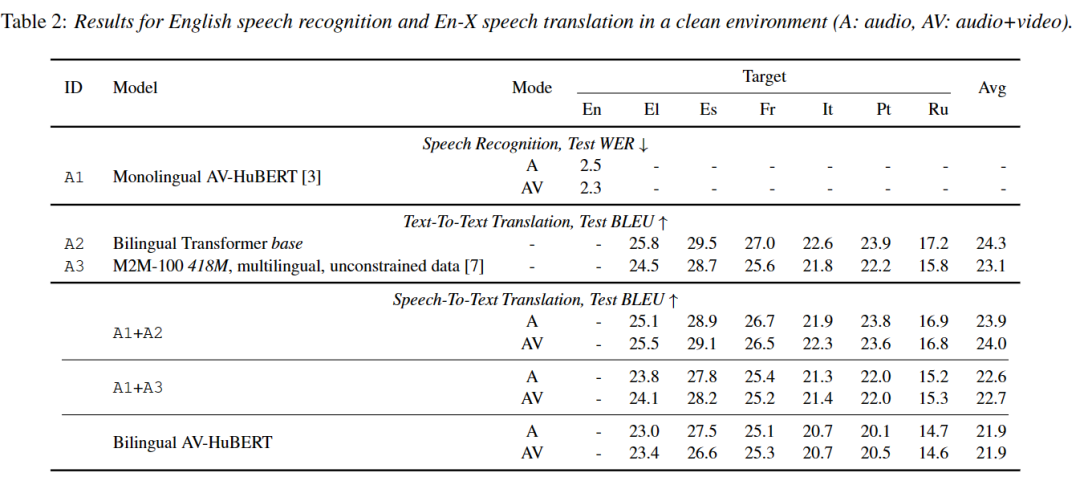 表1
表1
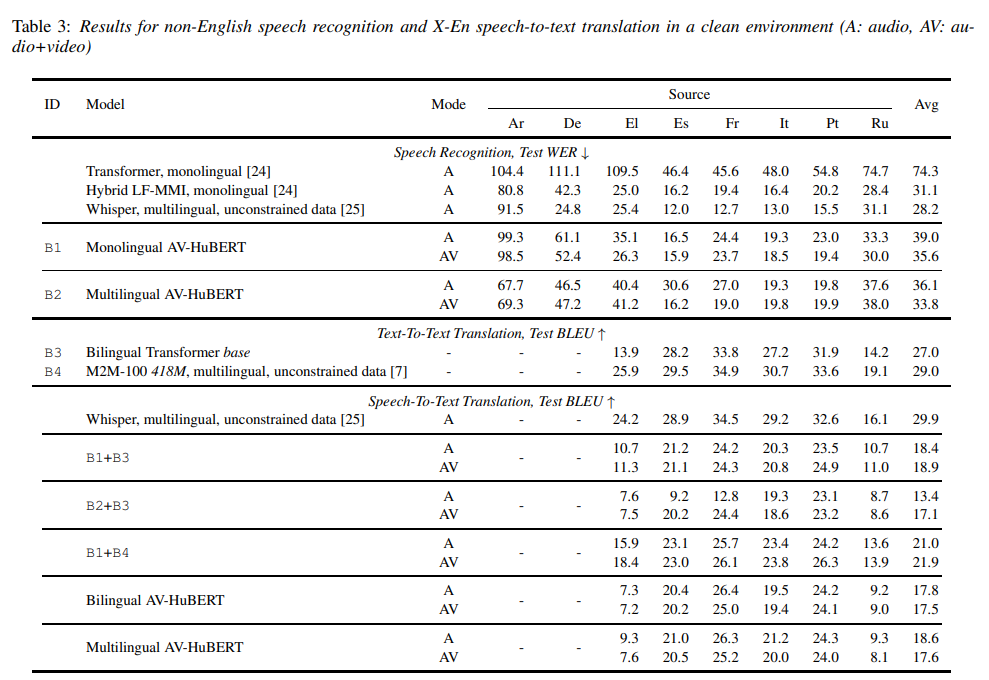 表2
表2
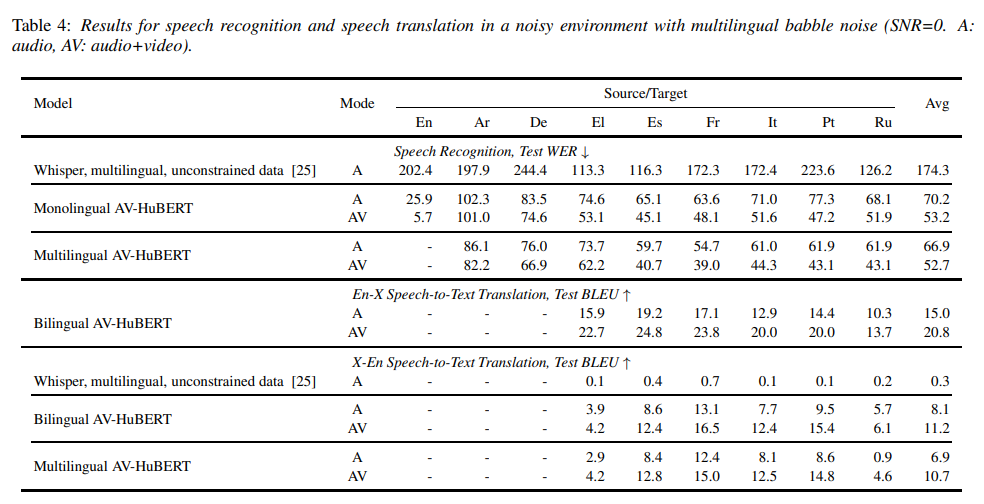 表3
表3
在噪音环境中
在高噪音环境下,研究人员的 AVSR 模型的测试误码率在表3的第一部分中得到了展示
研究人员发现,在这个具有挑战性的设置中,SOTA多语种ASR模型Whisper的表现不佳,平均误码率为174.3
研究人员的单语言AVSR模型在纯音频模式下的平均误码率相比之下分别为70.2和66.7
在视听模式下,研究人员发现模型的平均误码率下降了32%,这说明它们成功地利用了视觉信息来减少嘈杂环境的干扰
在纯音频和视听模式下,研究人员发现多语言AVSR模型在每种非英语语言(除了El语)上的表现都比单语言模型更好
理论要掌握,实操不能落!以上关于《Meta开源唇语翻译系统,支持6种语言的模型识别和本地部署,适用于所有人》的详细介绍,大家都掌握了吧!如果想要继续提升自己的能力,那么就来关注golang学习网公众号吧!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
299 收藏
-
科技周边 · 人工智能 | 2天前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-
453 收藏
-
202 收藏
-
419 收藏
-
170 收藏
-
475 收藏
-
科技周边 · 人工智能 | 6天前 | 人工智能 · tracing · ai agent · 可观测性 · 工具调用 · 可观测性 AI Agent Tracing 工具调用 OpenAI Agents SDK292 收藏
-
379 收藏
-
394 收藏
-
101 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习