DeepSeek专家模式升级,或为V4版本预热
时间:2026-04-26 14:58:17 332浏览 收藏
DeepSeek近日上线的“专家模式”并非全新大模型,而是一次精巧的产品架构升级:它与“快速模式”共同构成任务导向的双轨策略——前者专注复杂推理与深度思考,后者延续高效响应与多模态兼容,二者可能共享底层模型但通过提示工程、解码策略或推理路径实现差异化调度;实测显示其在高考作文等逻辑性任务中表现更优,但在代码生成等创意任务上仍逊于Gemini或GPT系列,印证其本质是资源调度机制而非能力跃迁;更值得关注的是,此次更新暗藏伏笔——缺席的“视觉模式”极可能成为即将发布的V4版本核心亮点,配合昇腾芯片适配与原生多模态支持,预示DeepSeek正以渐进式预告片的方式,为下一代旗舰模型蓄势铺路。
4 月 8 日,DeepSeek 正式推出专家模式。
访问 DeepSeek 官网或启动其 App 后,你将在输入框旁发现两个新增选项:快速模式与专家模式。前者强调响应效率,后者专注高难度任务——DeepSeek 正在以功能分治的方式,重塑自身定位。
功能分化:高效 VS 深度
两种模式的差异,并非仅停留在界面层面,其内在逻辑更值得玩味。
快速模式延续了用户熟悉的 DeepSeek 风格:响应敏捷、支持图片及文件上传,适用于日常交流与轻量级任务。但需注意的是,它对图像的解析仍基于 OCR 技术——本质上是在“读字”,而非真正“看图”。
 专家模式则聚焦复杂推理与智能检索,具备更强的深度思考能力。相应的限制也十分明确:文件上传功能被完全移除,当前仅支持纯文本输入,附件入口彻底隐去。
专家模式则聚焦复杂推理与智能检索,具备更强的深度思考能力。相应的限制也十分明确:文件上传功能被完全移除,当前仅支持纯文本输入,附件入口彻底隐去。
至于两者背后调用的具体模型或策略,官方尚未给出任何技术说明。
我围绕 2025 年江苏高考作文题进行了对比实测。快速模式输出的内容基本达标,但段落衔接松散、逻辑连贯性较弱;而专家模式生成的文章在结构过渡、层次推进与论证严密性上明显更优。
 快速模式
快速模式 专家模式值得注意的是,专家模式下的 Token 吞吐速度并未明显放缓,反而保持较高节奏,远非传统重型推理模型那种“慢工出细活”的风格。由此推测:二者很可能对应不同的模型分支或差异化推理路径——专家模式或在面对复杂任务时自动激活更长的思维链与更高密度的算力调度,而快速模式则始终将低延迟置于首位。
专家模式值得注意的是,专家模式下的 Token 吞吐速度并未明显放缓,反而保持较高节奏,远非传统重型推理模型那种“慢工出细活”的风格。由此推测:二者很可能对应不同的模型分支或差异化推理路径——专家模式或在面对复杂任务时自动激活更长的思维链与更高密度的算力调度,而快速模式则始终将低延迟置于首位。
这一思路与 DeepSeek-V3.2-Speciale 的设计理念高度吻合。官方曾指出,Speciale 版本在极端复杂任务中显著优于标准版,但 Token 消耗亦大幅提升。专家模式的定位与其如出一辙,只是二者是否直接关联,尚待验证。
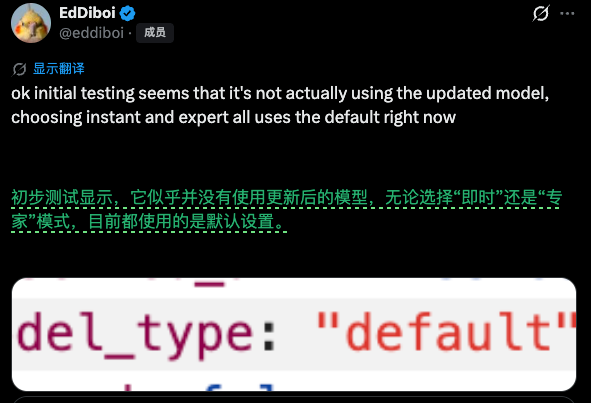
不过有开发者通过前端代码检测发现,快速模式与专家模式均显示为“default”标识,暗示它们或许共用同一套底层模型,仅在 prompt 工程、解码策略或推理流程上做了区分,且与传闻中的 V4 并无直接绑定。
 另有一位网友的横向测试结果也印证了这一点:两模式表现难分伯仲,甚至在部分场景下,专家模式的输出质量反不如快速模式。
另有一位网友的横向测试结果也印证了这一点:两模式表现难分伯仲,甚至在部分场景下,专家模式的输出质量反不如快速模式。
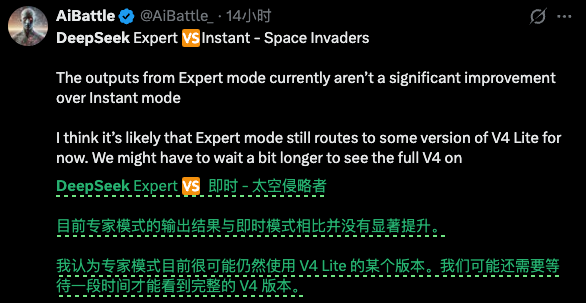
 动态测试案例:专家模式甚至不如快速模式实测验证:专家模式 ≠ 新模型
动态测试案例:专家模式甚至不如快速模式实测验证:专家模式 ≠ 新模型
为进一步探明专家模式的真实能力边界,我设计了多项创意类任务进行压力测试。
例如,使用专家模式构建一个宝可梦图鉴网站。结果略显遗憾。
首先,专家模式无法一次性完成整段代码输出,往往生成几行后即中断,必须手动点击“继续生成”才能延续,整个过程如同与一位频繁离席的程序员协同编码。
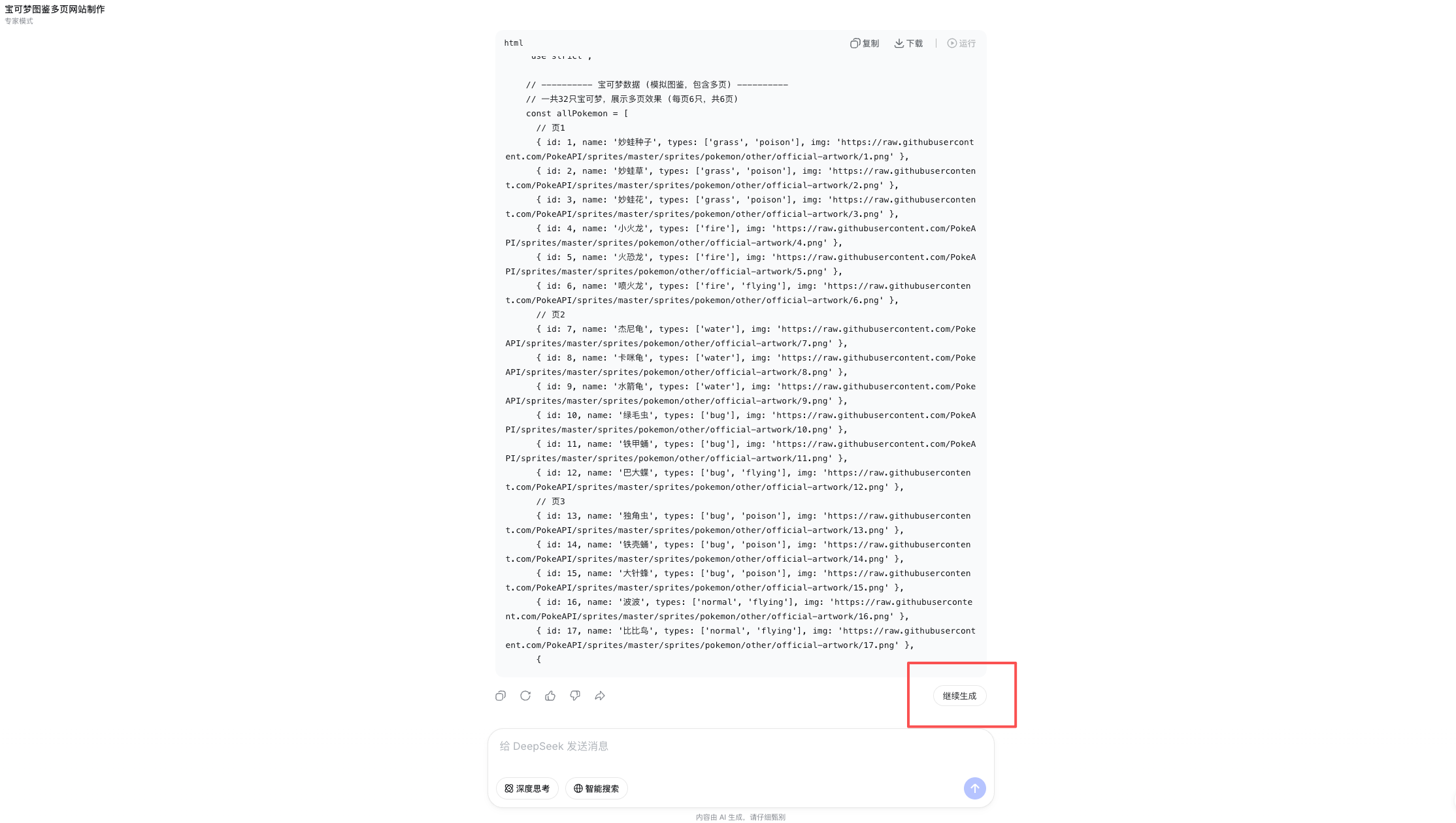 其次,最终呈现的网页效果不尽人意。无论是页面结构合理性、视觉一致性,还是整体完成度,相较 Gemini 或 GPT 系列同类任务输出,仍有明显差距:设计感偏弱、交互缺失、样式简陋,项目交付质量远未达到“开箱即用”水准。相比之下,Gemini 3.1 Pro 与 ChatGPT 5.4 Thinking 均能稳定输出完整、可运行、具备基础交互能力的前端代码,实现一键部署。
其次,最终呈现的网页效果不尽人意。无论是页面结构合理性、视觉一致性,还是整体完成度,相较 Gemini 或 GPT 系列同类任务输出,仍有明显差距:设计感偏弱、交互缺失、样式简陋,项目交付质量远未达到“开箱即用”水准。相比之下,Gemini 3.1 Pro 与 ChatGPT 5.4 Thinking 均能稳定输出完整、可运行、具备基础交互能力的前端代码,实现一键部署。
 DeepSeek 专家模式
DeepSeek 专家模式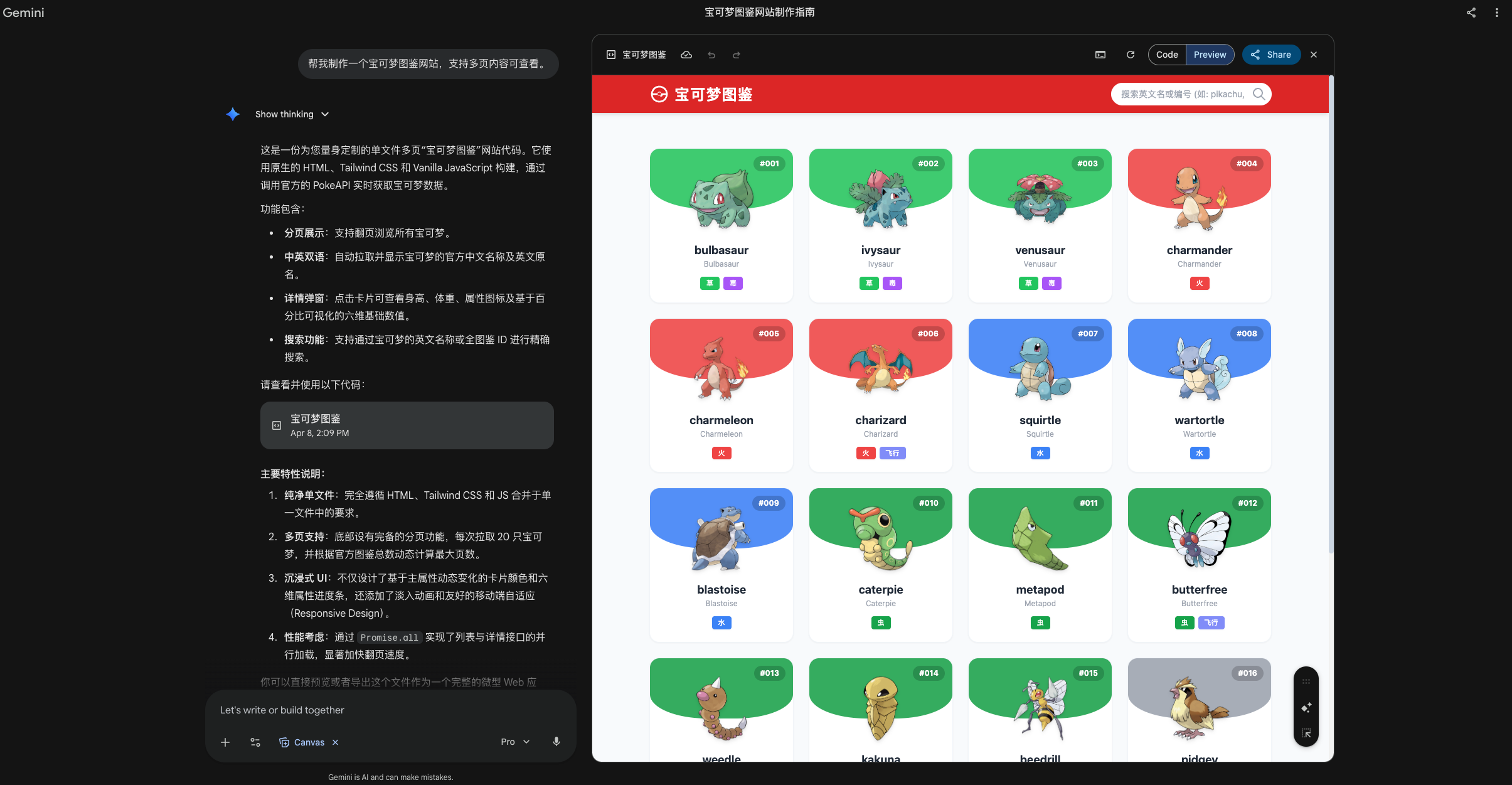 Gemini 3.1 Pro
Gemini 3.1 Pro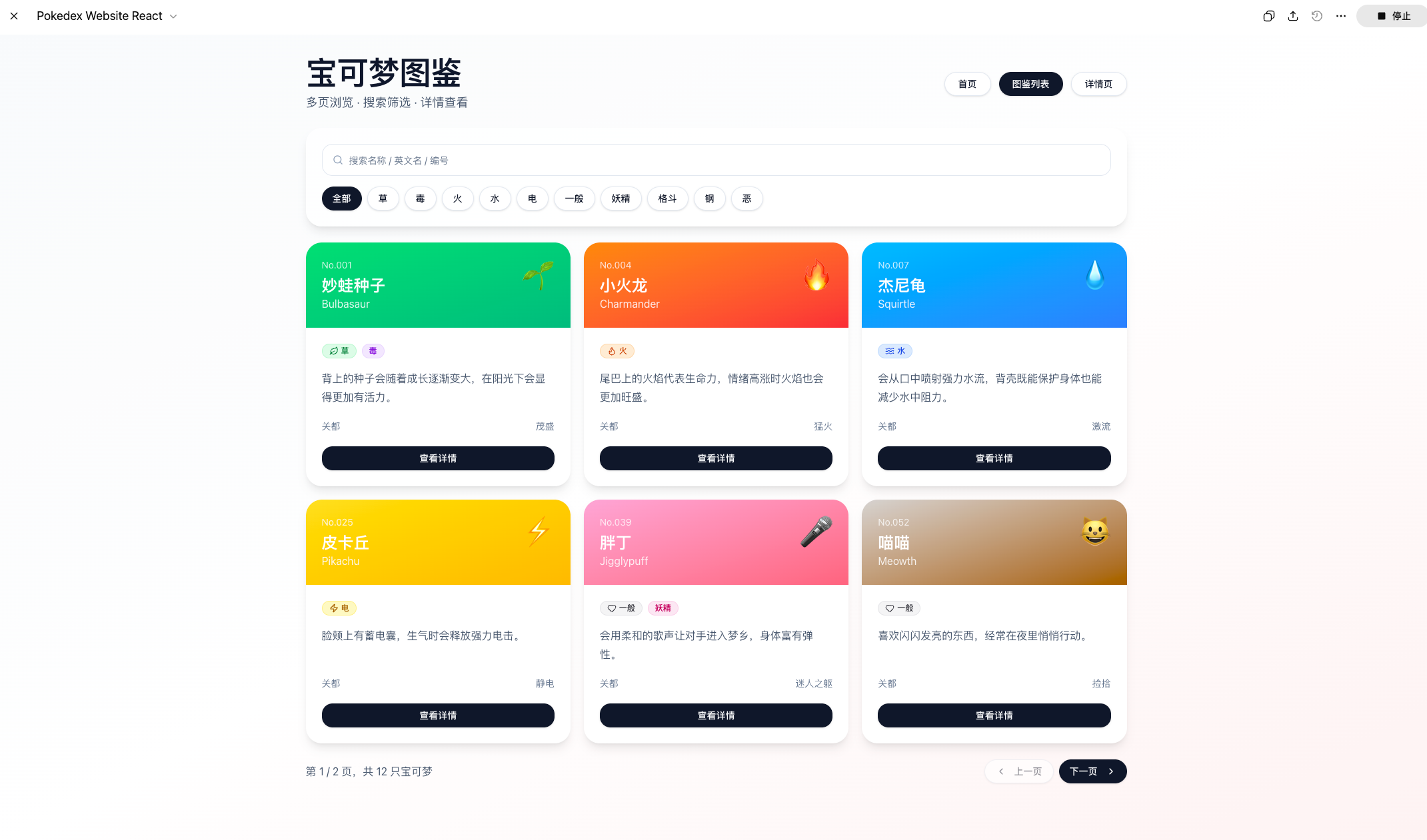 ChatGPT 5.4 Thinking该测试结果进一步佐证了一个判断:专家模式并非一次模型升级,而更接近一种面向任务类型的资源调度机制。DeepSeek 在传递这样一个信号:“我有能力启用更强的推理路径”,但并未承诺“我已经进化成一个更聪明的新模型”。
ChatGPT 5.4 Thinking该测试结果进一步佐证了一个判断:专家模式并非一次模型升级,而更接近一种面向任务类型的资源调度机制。DeepSeek 在传递这样一个信号:“我有能力启用更强的推理路径”,但并未承诺“我已经进化成一个更聪明的新模型”。
将其视为一次产品架构的精细化调整,比当作一次技术跃迁更为贴切。
视觉能力暂未登场,或留待 V4 揭幕
本次更新中最引人遐想的,恰恰是那个缺席的角色——视觉模式。
早在 4 月初,已有开发者从 DeepSeek 前端代码中挖掘出三类模式入口:快速、专家,以及尚未现身的视觉模式。然而此次正式上线,视觉模式却毫无踪影。
综合多方线索,视觉模式极有可能已被预留为 V4 的核心亮点。另有消息指出,DeepSeek V4 将首次大规模部署于华为昇腾芯片平台,并原生支持多模态理解能力。
因此,与其将本次更新定义为一次独立迭代,不如视其为一部精心编排的预告片。DeepSeek 正以“渐进式解锁”的节奏,为下一代旗舰模型铺路蓄势,真正的重头戏,或许已在路上。
 DeepSeek 的免费护城河,或将面临松动?
DeepSeek 的免费护城河,或将面临松动?
对 DeepSeek 而言,“免费”是其最锋利的竞争武器。无论网页端、App 还是第三方集成平台,用户均可零门槛使用。目前仅开放 API 收费通道,且定价在主流大模型中处于极低水平,堪称行业“价格屠夫”。
但不可忽视的是,来自 OpenAI、Anthropic、Google 等闭源巨头的压力持续加剧;开源阵营中,GLM、Kimi、MiniMax 等也在加速追赶。在当前技术代差尚未完全弥合的背景下,DeepSeek 如何守住阵地?
依托幻方科技雄厚的资金支持,DeepSeek 早期靠“烧钱换用户、换口碑”的打法尚具合理性。但随着模型迭代成本飙升、高端算力日益紧缺,这条路径终将收窄。
更值得警惕的是,由免费带来的用户黏性,其实异常脆弱。
多数用户选择 DeepSeek,并非出于对其产品深度认同,而是因为“够用+不花钱”。一旦竞品在能力上实现反超,或祭出更具诱惑力的免费策略,用户的迁移成本几乎为零。这种建立在价格优势之上的规模效应,难以构成真正可持续的护城河。
当然,也存在另一种战略可能——DeepSeek 主动以开源与低价为矛,持续下压行业 API 定价中枢,倒逼对手压缩利润空间,从而稳固自身生态位。但这要求其必须长期维持技术竞争力,否则“低价”只会沦为缺乏底气的空谈。
 说到底,免费是一把双刃剑。它助 DeepSeek 在短期内聚拢海量用户、打响品牌声量,却也在无形中挤压了其商业化拓展的空间。护城河能否守得住,关键在于 DeepSeek 是否能在免费红利消退前,锚定并兑现属于自己的独特价值。
说到底,免费是一把双刃剑。它助 DeepSeek 在短期内聚拢海量用户、打响品牌声量,却也在无形中挤压了其商业化拓展的空间。护城河能否守得住,关键在于 DeepSeek 是否能在免费红利消退前,锚定并兑现属于自己的独特价值。
此次的功能拆分,以及未来或将亮相的视觉模型,或许正是其商业化探索的初步信号。具体走向如何,仍有待观察。让我们静待后续。

以上就是《DeepSeek专家模式升级,或为V4版本预热》的详细内容,更多关于专家模式,视觉模式延期的资料请关注golang学习网公众号!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
科技周边 · 人工智能 | 7小时前 | go · openai · AI接口 · Responses API · Go OpenAI Responses API background mode 异步轮询 大模型接口388 收藏
-
科技周边 · 人工智能 | 9小时前 | go语言 · 异步任务 · 人工智能 · openai · API工程化 · Go 异步任务 轮询 数据保留 OpenAI Responses API background mode183 收藏
-
202 收藏
-
科技周边 · 人工智能 | 2天前 | API · go · 人工智能 · 工程实践 · 工具调用 · Go Anthropic Messages API tool_use tool_result Claude工具调用368 收藏
-
243 收藏
-
195 收藏
-
186 收藏
-
333 收藏
-
419 收藏
-
280 收藏
-
科技周边 · 人工智能 | 6天前 | 异步任务 · 人工智能 · jsonl · AI工程化 · Batch API · 结果对账 · JSONL 大模型批量任务 OpenAI Batch API custom_id AI 离线处理 结果对账113 收藏
-
149 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习