DeepSeek-V4:新一代大语言模型发布
时间:2026-05-14 09:12:51 223浏览 收藏
DeepSeek-V4作为新一代开源大语言模型,以百万Token超长上下文、CSA+HCA混合注意力架构和双版本(Pro/Flash)设计实现性能与效率的双重突破:它在世界知识(SimpleQA 57.9%)、中文理解(84.4%)、数学与代码竞赛(Codeforces 3206分)、Agent工程能力(SWE Verified 80.6%)等关键指标上全面领跑开源阵营,逼近甚至局部超越Gemini-3.1-Pro、GPT-5.4与Claude Opus等顶级闭源模型,同时API成本低至竞品的1/12,并完全开源权重与技术细节——这意味着开发者无需妥协于性能或预算,即可获得真正普惠、可部署、可定制的下一代AI基础设施。
DeepSeek-V4是什么
DeepSeek-V4是DeepSeek推出的新一代大语言模型系列预览版,拥有百万字超长上下文窗口,在Agent能力、世界知识与推理性能方面达到开源领域领先水平。模型包含deepseek-v4-pro 和 deepseek-v4-flash 两个版本,分别定位高性能与经济高效,均已开源并提供API服务,支持非思考与思考双模式,为长文本处理与智能体应用提供普惠化基础设施。

DeepSeek-V4的主要功能
- 百万上下文处理:原生支持1M Token超长文本理解与记忆,为官方服务标配。
- 混合注意力机制:CSA与HCA架构大幅降低长上下文计算与显存开销。
- Agent编码增强:针对Claude Code、OpenClaw等主流Agent框架深度优化。
- 双模式推理:支持非思考与思考模式,后者可通过reasoning_effort参数调节强度。
- 多领域专家融合:通过OPD蒸馏整合数学、代码、Agent等领域专家能力。
- 经济高效选择:Flash版本用更低参数实现接近Pro的推理性能,API成本显著降低。
DeepSeek-V4的技术原理
- CSA压缩稀疏注意力:将每m个token的KV压缩为1个条目,通过Lightning Indexer计算索引分数并执行Top-k稀疏选择,结合滑动窗口与Attention Sink机制保留局部依赖。
- HCA重度压缩注意力:以更大压缩比m’将KV条目合并为单个条目,保持密集注意力而不采用稀疏选择,进一步降低计算量。
- mHC流形约束超连接:将残差映射矩阵通过Sinkhorn-Knopp算法投影到双随机矩阵流形,约束谱范数不超过1,增强深层信号传播稳定性。
- Muon优化器:模型采用混合Newton-Schulz迭代对梯度矩阵进行正交化,分快速收敛与精确稳定两个阶段,支持大规模MoE高效训练。
- FP4量化感知训练:对MoE专家权重和CSA索引器QK路径进行FP4量化,用FP8扩展动态范围实现无损反量化,降低内存与计算开销。
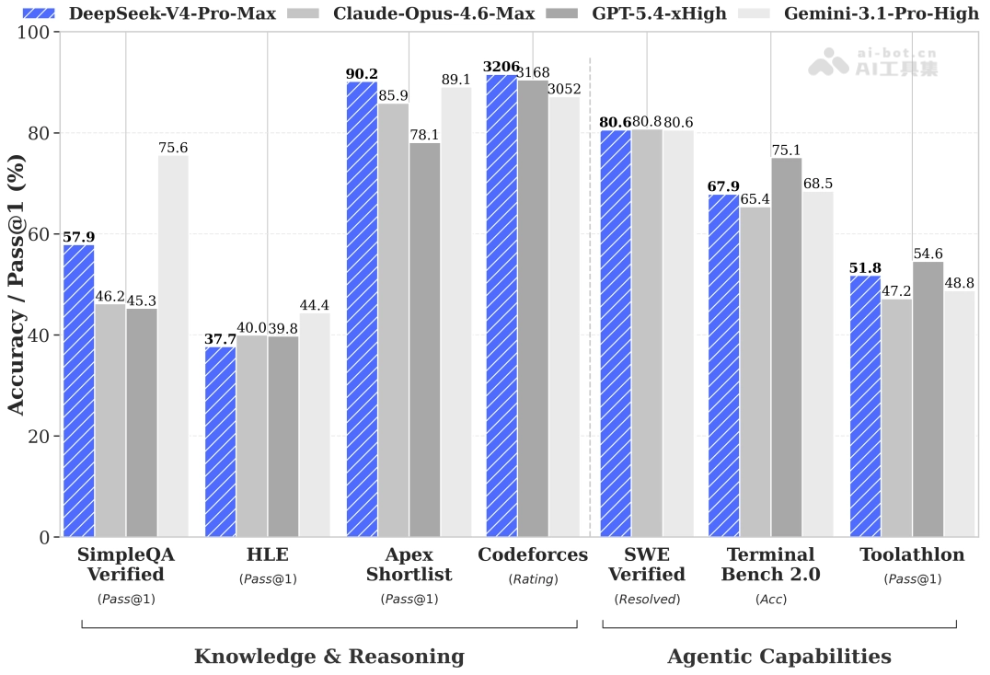
DeepSeek-V4的性能体现
- 知识能力
- 世界知识领先开源:SimpleQA-Verified达57.9%,超越所有已评测开源模型20个百分点,仅稍逊于Gemini-3.1-Pro(75.6%)。
- 中文知识突出:Chinese-SimpleQA达84.4%,大幅领先K2.6(75.9%)与GLM-5.1(75.0%)。
- 教育知识接近前沿:MMLU-Pro 87.5%、GPQA Diamond 90.1%,与GPT-5.4持平,略低于Gemini-3.1-Pro。
- 推理与代码能力
- 数学竞赛比肩闭源:HMMT 2026 Feb达95.2%,IMOAnswerBench达89.8%,超越K2.6与GLM-5.1,接近GPT-5.4与Opus-4.6。
- 代码竞赛首次开源追平闭源:Codeforces Rating达3206,与GPT-5.4(3168)相当,当前排名人类选手第23位。
- 高难度推理突破:Apex Shortlist达90.2%,超越GPT-5.4(78.1%)与Opus-4.6(85.9%);LiveCodeBench达93.5%,领先所有对比模型。
- Agent能力
- 软件工程接近顶级闭源:SWE Verified达80.6%,与Opus-4.6(80.8%)基本持平;SWE Pro 55.4%、SWE Multilingual 76.2%。
- 终端操作领先开源:Terminal Bench 2.0达67.9%,超越K2.6(66.7%)、GLM-5.1(63.5%)与Opus-4.6(65.4%)。
- 工具调用泛化优秀:MCPAtlas Public 73.6%、Toolathlon 51.8%,在包含广泛工具和MCP服务的评测中表现突出。
- 长上下文能力
- 百万上下文检索强劲:MRCR 1M达83.5%,超越Gemini-3.1-Pro(76.3%);128K内检索性能高度稳定,1M时仍保持较强能力。
- 真实场景长文档理解:CorpusQA 1M达62.0%,优于Gemini-3.1-Pro(53.8%)。
- 效率表现
- 计算量断崖式下降:1M上下文下,V4-Pro单Token推理FLOPs仅为V3.2的27%,V4-Flash仅为10%。
- KV缓存大幅压缩:1M上下文下,V4-Pro累计KV缓存为V3.2的10%,V4-Flash仅为7%。
- 路由专家FP4量化:专家权重采用FP4存储,未来硬件上理论可再提升1/3效率。
如何使用DeepSeek-V4
- 网页端/App:访问DeepSeek官网或官方App,选择专家模式(Pro)或快速模式(Flash)。
- API调用:修改model参数为deepseek-v4-pro或deepseek-v4-flash,base_url保持不变。
- 思考模式:复杂Agent场景建议启用思考模式并设置reasoning_effort: max。
- 本地部署:通过Hugging Face或ModelScope下载开源权重自行部署。
DeepSeek-V4的关键信息和使用要求
- 版本规格:Pro版1.6T参数/49B激活,Flash版284B参数/13B激活,预训练数据分别为33T与32T。
- 上下文长度:两个版本均支持1M Token,旧接口deepseek-chat与deepseek-reasoner将于2026-07-24停用。
- API定价(每百万Token):Pro输入缓存命中1元/未命中12元,输出24元;Flash输入缓存命中0.2元/未命中1元,输出2元。
- 算力限制:Pro版当前服务吞吐有限,预计下半年昇腾950超节点批量上市后价格将大幅下调。
DeepSeek-V4的核心优势
- 百万上下文普惠化:1M Token超长上下文成为官方服务标配,突破传统注意力机制的二次计算瓶颈,使长文本任务与测试时缩放真正可行。
- 极致长上下文效率:通过CSA压缩稀疏注意力与HCA重度压缩注意力的混合架构,1M上下文下V4-Pro的单Token推理FLOPs仅为V3.2的27%,KV缓存仅10%,Flash版更是低至10%与7%。
- 开源模型性能新标杆:V4-Pro-Max在知识、推理、代码竞赛等评测中全面领先前代开源模型,Agent编码能力内部评测优于Claude Sonnet 4.5,交付质量接近Opus 4.6非思考模式。
- 双版本灵活覆盖:Pro版(1.6T/49B)定位顶级性能,Flash版(284B/13B)以极小激活参数实现接近的推理能力,API价格低至Pro的1/12,普惠不同预算场景。
- Agent能力原生增强:针对Claude Code、OpenClaw等主流Agent框架专项优化,支持跨用户消息边界的连贯推理保留,在SWE、Terminal Bench等Agent评测中表现优异。
DeepSeek-V4的项目地址
- HuggingFace模型库:http://huggingface.co/collections/deepseek-ai/deepseek-v4
- 技术论文:http://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
DeepSeek-V4的同类竞品对比
| 对比维度 | DeepSeek-V4-Pro | Claude Opus 4.6 | Kimi K2.6 |
|---|---|---|---|
| 模型定位 | 开源高性能MoE | 闭源顶级通用 | 开源Agent智能 |
| 开源状态 | 完全开源 | 闭源API | 开源/开放API |
| 总参数量 | 1.6T | 未公开 | 未公开 |
| 激活参数 | 49B | 未公开 | 未公开 |
| 上下文长度 | 1M Token | 200K | 1M Token |
| 核心架构 | CSA+HCA混合注意力 | 传统Transformer | MoE+长上下文 |
| MMLU-Pro | 87.5 | 89.1 | 87.1 |
| SimpleQA | 57.9 | 46.2 | 36.9 |
| Codeforces | 3206 | – | – |
| SWE Verified | 80.6 | 80.8 | 80.2 |
| Terminal Bench | 67.9 | 65.4 | 66.7 |
| MRCR 1M | 83.5 | 92.9 | – |
| API输入价格 | 12元/百万Token | 约150元/百万Token | 约60元/百万Token |
| 长上下文效率 | KV缓存仅为V3.2的10% | 标准KV缓存 | 高效但细节未公开 |
DeepSeek-V4的应用场景
- 长文档分析:支持百万字级论文、报告、法律合同的全文理解与跨章节推理。
- 智能体编码:在Claude Code、OpenClaw等框架中执行复杂代码生成、重构与调试任务。
- 多轮工具调用:在Agent工作流中保留完整推理历史,支持跨用户消息边界的连贯思考。
- 知识密集型问答:在世界知识评测中大幅领先开源模型,适用于教育、科研与专业咨询。
- 白领办公任务:模型在中文写作、信息分析、文档生成与编辑等场景表现优异。
今天带大家了解了的相关知识,希望对你有所帮助;关于科技周边的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
相关阅读
更多>
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
最新阅读
更多>
-
468 收藏
-
科技周边 · 人工智能 | 4天前 | 人工智能 · ai agent · AI应用 · 工具调用 · 权限边界 · 审计链路 · 人工智能 权限控制 AI Agent 工具调用 审批链路 审计回放 上线指标343 收藏
-
科技周边 · 人工智能 | 1星期前 | 人工智能 · GenAI · opentelemetry · 可观测性 · AI工程 · 人工智能 链路追踪 GenAI OpenTelemetry AI可观测性 LLM网关 Token统计427 收藏
-
154 收藏
-
309 收藏
-
234 收藏
-
科技周边 · 人工智能 | 2星期前 | 人工智能 · 前端流式输出 · AI聊天 · Fetch Stream · 前端 AI聊天 流式输出 ReadableStream TextDecoder Fetch Stream448 收藏
-
427 收藏
-
191 收藏
-
299 收藏
-
科技周边 · 人工智能 | 3星期前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
课程推荐
更多>
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习