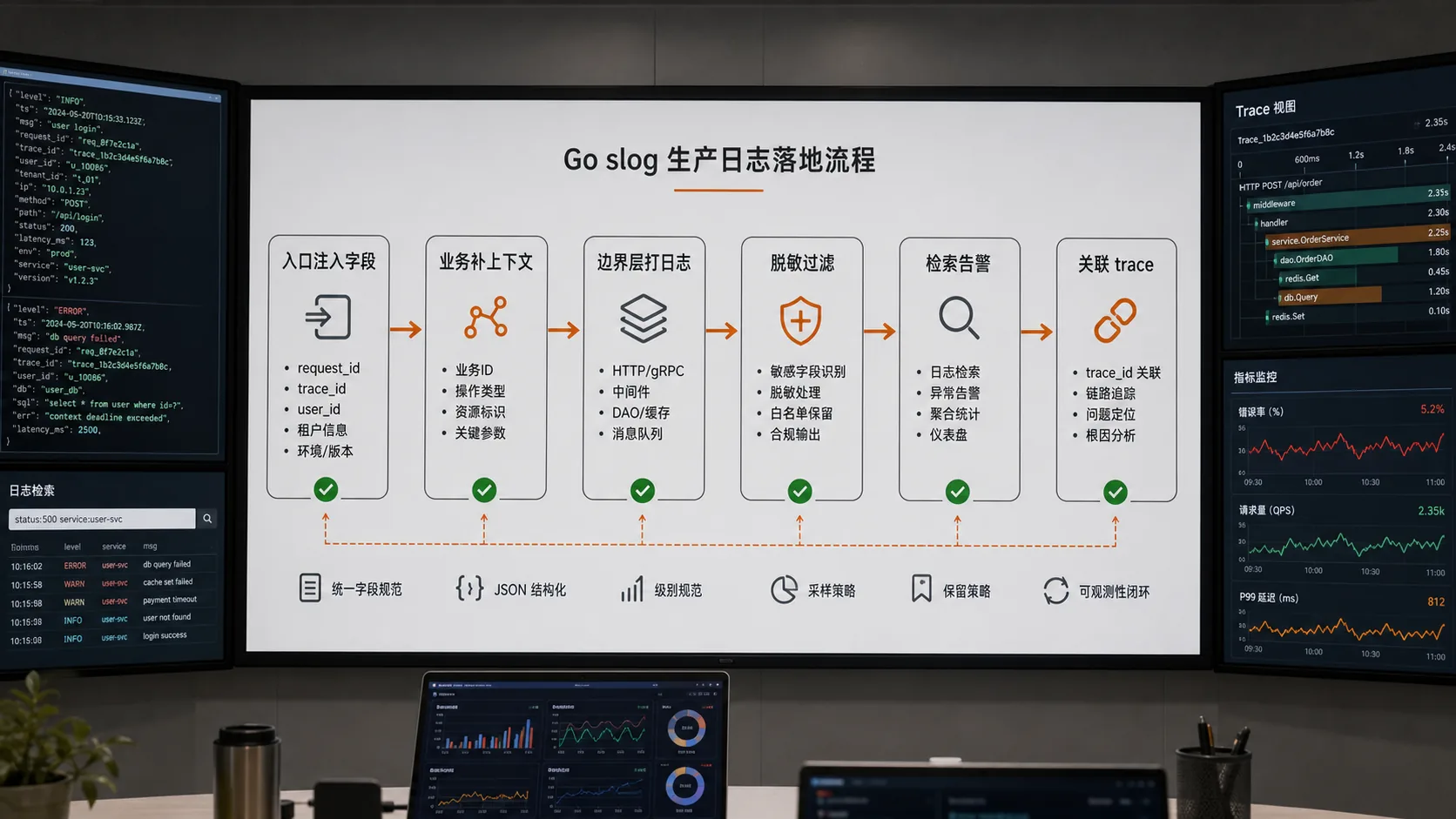
很多 Go 服务不是没有日志,而是日志没法用:一堆 log.Println(err),线上真出事时,你搜不到 request_id,看不到用户、订单、下游、耗时,也不知道这条 error 到底该告警还是只是业务拒绝。Go 标准库里的 log/slog,真正值得用的地方不是“换个 logger”,而是让日志变成可查询、可聚合、可关联的结构化事件。
这篇按我做线上服务的习惯聊,不堆 API 清单。我们重点看:字段怎么设计,context 里放什么,错误怎么打,敏感信息怎么脱敏,最后怎么让日志和 trace、metrics 对得上。

先想清楚:日志是给机器查的,不只是给人看的
普通文本日志适合本地调试,但生产环境里你更常做的是搜索和聚合:某个用户最近 10 分钟发生了什么、某个接口 P99 升高时有没有下游错误、某类 error 一小时出现了多少次。
所以字段名要稳定。不要今天叫 uid,明天叫 userId,后天又叫 user_id。日志系统最怕字段随心情漂移,最后查询语句比业务代码还难维护。
我的基础字段习惯
入口层我通常会固定这些字段:service、env、request_id、trace_id、method、path、status、cost_ms。业务字段另算,比如 user_id、order_id、tenant_id。
字段不是越多越好。高基数字段比如完整 URL、原始请求体、超长 SQL,不应该随便打进每条日志。否则检索成本、存储成本、隐私风险都会上来。
入口层先做一件事:准备好带上下文的 logger
我不喜欢在每个函数里重新拼 request_id。更舒服的做法是在入口处构造一个带公共字段的 logger,然后往下传,或者从 context 里取。
func withLogger(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
rid := requestID(r)
traceID := traceIDFromContext(r.Context())
logger := slog.Default().With(
"request_id", rid,
"trace_id", traceID,
"method", r.Method,
"path", r.URL.Path,
)
ctx := context.WithValue(r.Context(), loggerKey{}, logger)
next.ServeHTTP(w, r.WithContext(ctx))
})
}
这里要克制一点:context 里可以放 request-scoped logger,但不要把一堆业务参数都塞进去。业务参数还是通过函数参数传,日志字段只保留排障需要的上下文。
错误日志:不要每层都打,也不要只打一层 failed
Go 代码里最容易把日志打乱的地方就是 error。底层一失败就打一条,service 再打一条,handler 又打一条,最后同一个错误刷三遍,告警看起来像三次事故。
我的规则是:中间层负责返回带上下文的 error,边界层负责决定日志级别和字段。比如 handler、consumer、cron job 这些地方才是真正适合落日志的位置。
func (h *Handler) GetOrder(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
orderID := r.PathValue("id")
order, err := h.svc.GetOrder(ctx, orderID)
if err != nil {
logger := Logger(ctx).With("order_id", orderID)
if errors.Is(err, ErrOrderNotFound) {
logger.WarnContext(ctx, "order not found", "err", err)
http.Error(w, "not found", http.StatusNotFound)
return
}
logger.ErrorContext(ctx, "get order failed", "err", err)
http.Error(w, "internal error", http.StatusInternalServerError)
return
}
_ = json.NewEncoder(w).Encode(order)
}

脱敏要在 handler 里形成制度
日志最怕“临时加一个字段看看”,然后把手机号、身份证、token、cookie、银行卡号打进生产。slog 的好处是你可以通过 LogValuer 或自定义 Handler 统一处理敏感字段。
我建议至少把这些字段列进禁止清单:password、token、authorization、cookie、phone、id_card。能打 hash 就别打原文,能打后四位就别打完整值。
日志级别别当装饰
Info 是关键业务事件,Warn 是可预期但需要关注的异常,Error 是请求失败、任务失败、依赖不可用这类需要排查的问题。不要所有失败都 Error,也不要所有事情都 Info。
一个常见例子:用户输入错误、订单不存在、权限不足,很多时候是业务可预期结果,打 Warn 就够了。数据库超时、Redis 故障、下游 500,才应该进入 Error 和告警候选。
和 trace、metrics 对齐才真的好用
单独一条日志价值有限。生产排障更常见的路径是:metrics 发现某接口错误率升高,trace 找到慢链路,日志通过 trace_id 或 request_id 查到具体错误上下文。三者能对齐,排障速度才会明显提升。
所以 request_id、trace_id 不要只出现在网关日志里,应用日志也要带上。否则你会在不同系统之间手工拼时间戳,这事凌晨两点做起来很痛苦。
我的 slog review 清单
- 字段命名是否稳定,比如统一使用
request_id、trace_id、user_id? - 入口层是否统一注入公共字段,而不是每个业务函数各写各的?
- 错误是否只在边界层落一次日志,中间层只补上下文返回?
- 敏感字段是否统一脱敏,token、cookie、手机号有没有直接输出?
- 日志级别是否有语义,Warn 和 Error 有没有明确边界?
- 高基数字段和大字段有没有控制,避免日志成本失控?
- 日志里是否能和 trace、metrics 对齐,至少有 request_id 或 trace_id?
最后聊两句
slog 不是为了让日志看起来更现代,而是为了让线上排障少一点猜谜。真正有用的日志,应该能在事故时回答三个问题:这是谁的请求,在哪个环节失败,下一步该查哪个依赖。
我的建议是先别急着换一堆花哨封装。把字段名、错误落点、脱敏规则、trace_id 这几件基础事做好,slog 就已经能让你的 Go 服务排障体验上一个台阶。




