线上遇到 MySQL 锁等待,很多人的第一反应是把 innodb_lock_wait_timeout 调大。这个动作有时候像给发烧的人多盖一床被子:看起来在处理问题,实际上可能让连接堆得更久,把线程池和连接池一起拖下水。
这篇我按一次转账服务的事故复盘来写,重点不背锁类型名词,而是讲怎么复现、怎么找到阻塞者、怎么读 performance_schema.data_locks 和 data_lock_waits,以及为什么死锁不是“彻底消灭”,而是要减少概率并让业务能安全重试。适用版本:MySQL 8.0 / 8.4,存储引擎默认按 InnoDB 讨论。
业务场景:转账接口偶发 1213
假设有一张账户表,转账时从 A 扣钱、给 B 加钱。两个用户互相转账,或者后台批量调账和用户转账同时发生,就可能出现事务拿锁顺序相反。
CREATE TABLE accounts ( id BIGINT PRIMARY KEY, balance DECIMAL(12,2) NOT NULL ) ENGINE=InnoDB;
事务 A 先锁 id=1,再锁 id=2;事务 B 先锁 id=2,再锁 id=1。两个事务都拿着对方想要的锁,谁也走不下去,这就是很典型的死锁。
先复现:别一上来就改参数
会复现,排查就成功了一半。两个会话分别执行下面的 SQL,很容易制造一个事务顺序相反的现场。
-- 会话 A BEGIN; UPDATE accounts SET balance = balance - 100 WHERE id = 1; UPDATE accounts SET balance = balance + 100 WHERE id = 2; -- 会话 B BEGIN; UPDATE accounts SET balance = balance - 50 WHERE id = 2; UPDATE accounts SET balance = balance + 50 WHERE id = 1;
如果时序刚好卡住,MySQL 会检测到死锁并回滚其中一个事务,客户端通常会收到 ERROR 1213 (40001): Deadlock found when trying to get lock。如果不是死锁,而只是等不到锁,常见的是 ERROR 1205: Lock wait timeout exceeded。
死锁和锁等待不是一回事
死锁是互相等待,MySQL 检测到后会挑一个事务回滚。锁等待是一个事务等另一个事务释放锁,不一定形成环。前者通常要业务重试,后者要先找谁挡住了路。
所以报警里看到 1213 和 1205,处理思路不一样。1213 要看事务顺序和重试策略;1205 要定位阻塞者、长事务、慢 SQL 或未提交事务。别拿一个超时时间参数糊所有问题。
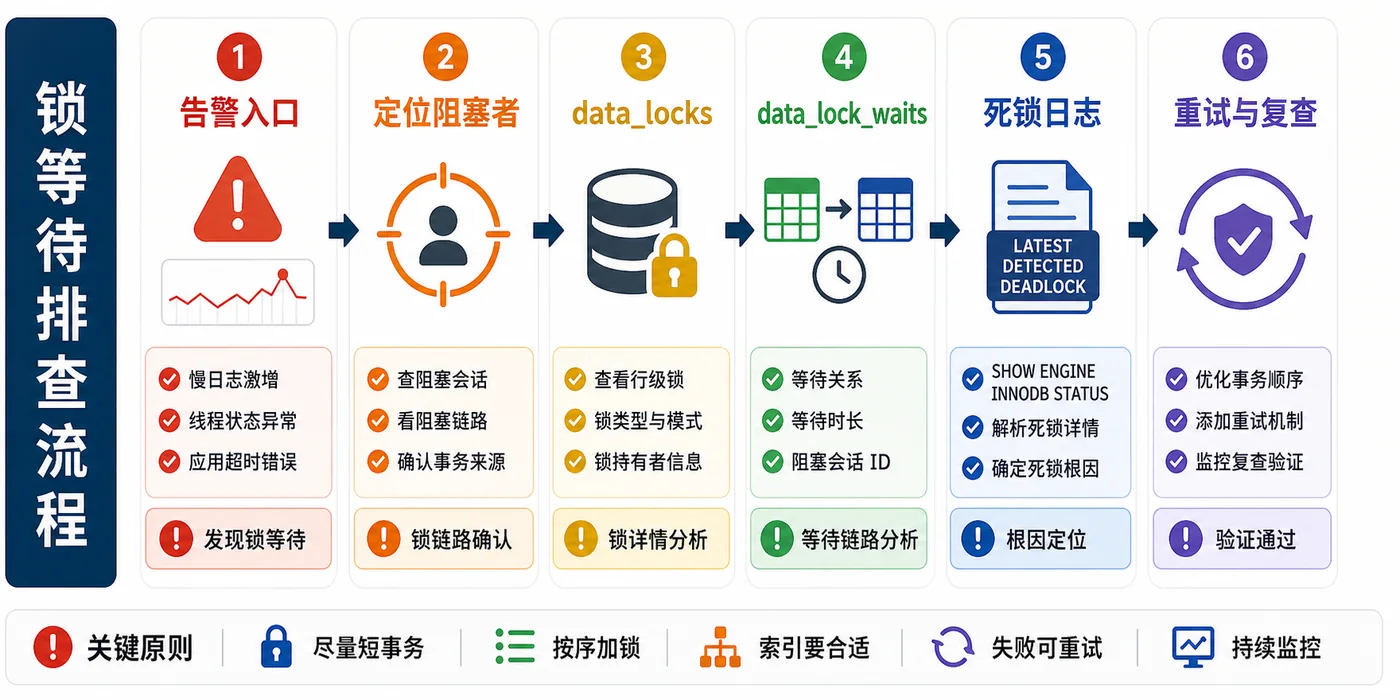
看最后一次死锁现场
MySQL 官方建议用 SHOW ENGINE INNODB STATUS 查看最近一次 InnoDB 用户事务死锁。这个输出很长,但你要抓住几块:哪个事务等待哪个锁,持有哪些锁,执行的是哪条 SQL,最后谁被回滚。
SHOW ENGINE INNODB STATUS\G
如果死锁很频繁,只看最后一次不够,可以考虑临时打开 innodb_print_all_deadlocks,让死锁信息写到错误日志里。注意这是排障手段,不是长期替代监控的方式,打开前要确认日志量和敏感 SQL 风险。
SET GLOBAL innodb_print_all_deadlocks = ON;
MySQL 8.x 更推荐用 performance_schema 看锁
在线上排查锁等待,我更喜欢先查 performance_schema.data_lock_waits,它能把等待者和阻塞者关联起来;再连 data_locks 看锁在哪个库、哪个表、哪个索引、什么锁模式。
SELECT w.REQUESTING_ENGINE_TRANSACTION_ID AS waiting_trx, w.BLOCKING_ENGINE_TRANSACTION_ID AS blocking_trx FROM performance_schema.data_lock_waits AS w;
再把事务 ID 和锁表关联起来看细节:
SELECT
ENGINE_TRANSACTION_ID,
OBJECT_SCHEMA,
OBJECT_NAME,
INDEX_NAME,
LOCK_MODE,
LOCK_STATUS
FROM performance_schema.data_locks
WHERE LOCK_STATUS IN ('WAITING','GRANTED');
排查时不要只看 LOCK_MODE,还要看 INDEX_NAME。很多锁范围过大的问题,本质是 SQL 没走到合适索引,导致 InnoDB 锁住了比你以为更多的记录或范围。

间隙锁为什么会让人误判
在 InnoDB 的默认可重复读隔离级别下,范围查询加锁时可能出现 next-key lock,也就是记录锁加间隙锁。你明明只想改一行,结果因为条件没有好索引,锁住了一段范围,其他插入或更新也跟着排队。
这类问题最容易被误判成“数据库偶尔抽风”。实际根因可能是:范围条件没索引、索引列顺序不对、事务里先查范围再更新、或者批量任务一口气锁太多行。
修复思路一:统一加锁顺序
转账这种场景,我会强制按账户 id 从小到大加锁。无论 A 转 B,还是 B 转 A,事务内部都按同一个顺序锁定账户。这样能显著降低互相反向等待的概率。
-- 先锁较小 id,再锁较大 id SELECT id FROM accounts WHERE id IN (1, 2) ORDER BY id FOR UPDATE;
拿到锁之后再按业务方向扣减和增加余额。注意,ORDER BY 只是表达意图,真正落地时要确认执行计划和索引,避免扫描范围扩大。
修复思路二:让锁更小、更短
事务里不要夹杂远程调用、复杂计算、慢日志写入、用户交互等待。锁一旦拿到,就尽快完成数据库内的关键更新并提交。长事务不是慢一点而已,它会把别人的锁等待一起拉长。
另外,更新条件必须尽量命中精确索引。比如按订单号更新就建订单号唯一索引,按用户和状态批量处理就要评估复合索引。没有合适索引的 UPDATE ... WHERE,很容易让锁范围超出预期。
修复思路三:业务必须能重试
官方文档也强调,死锁并不表示数据库坏了。InnoDB 默认会检测死锁并回滚一个事务,应用需要能捕获错误并重试。关键是重试必须幂等,不能把扣款、发券、写流水这种副作用重复执行。
我的习惯是:数据库事务里只做可回滚的数据修改;外部消息、通知、回调放到事务成功后,或者用事务消息/流水状态保证幂等。遇到 1213 可以短暂退避后重试 1 到 3 次,超过次数就记录现场。
上线前检查什么
- 同一类业务是否统一加锁顺序,尤其是转账、库存调拨、批量状态流转。
- 事务里是否包含远程调用、sleep、复杂循环或大批量更新。
- 更新条件是否命中合适索引,是否可能扩大锁范围。
- 是否有 1213 死锁重试和 1205 锁等待超时的不同处理。
- 是否能通过
data_lock_waits快速看到 blocking_trx。 - 上线后是否观察死锁次数、锁等待时间、活跃连接数和慢事务。
我的排查顺序
第一,看报警是 1213 还是 1205。第二,用 SHOW ENGINE INNODB STATUS 拿最近死锁现场。第三,用 performance_schema.data_lock_waits 找等待者和阻塞者。第四,回到业务代码看事务边界和加锁顺序。第五,再决定改索引、改 SQL、拆事务还是补重试。
这个顺序能避免一个常见误区:一上来就调大超时,结果把问题藏得更深。锁问题不是靠等解决的,是靠缩短事务、缩小锁范围、统一顺序和安全重试解决的。
最后聊两句
MySQL InnoDB 死锁不是罕见事故,它是并发写入系统里迟早会遇到的正常现象。真正区分工程质量的,不是系统永远不死锁,而是死锁发生时能不能快速定位、自动重试、保住数据一致性。
我的建议很朴素:把每一次死锁当成一次事务设计 review。把 SQL、锁等待图、事务顺序、索引和重试结果都留下来。下次类似问题来时,你就不是靠猜,而是靠证据往前推。
参考资料:MySQL 8.4 Reference Manual:Deadlocks in InnoDB、MySQL 8.4 Reference Manual:data_locks Table、MySQL 8.4 Reference Manual:InnoDB Locking。




