这篇写一个 Java 后端非常典型的生产故障:Spring Boot 服务突然大量报 Connection is not available, request timed out,接口 p99 飙升,线程堆栈里一片等连接。第一反应如果只是把 maximumPoolSize 从 20 改成 80,通常只是把事故往后推了一点。
本文适用于 Java 17/21、Spring Boot 3.x、HikariCP、MyBatis/JPA 常见服务。资料只用于核对事实:Spring Boot 默认连接池常见实现是 HikariCP,Actuator/Micrometer 能暴露 Hikari 连接池指标。正文按线上排查复盘写,重点是找到连接为什么没有及时归还。
业务场景:订单接口突然排队
我们有一个订单详情接口,平时 QPS 不高,但活动页会把它打成热点。服务使用 Spring Boot 3、MyBatis、HikariCP,数据库连接池最大 20。某天活动开始后,接口从 80ms 变成 2s 以上,日志里反复出现获取连接超时。
一开始有人建议把连接池改成 80。这个动作不是绝对不能做,但它应该是容量评估后的结果,不应该是第一反应。连接池满了说明连接被占住了,先要找谁占着、占多久、为什么不回来。
问题复现:把慢点放进事务里
最小复现很简单:开一个 20 大小的池,在 @Transactional 方法里先查订单,再调用一个慢 500ms 的远程接口,最后再更新访问记录。压测一上来,数据库连接并不是只服务 SQL,而是陪着远程接口一起等待。
这个坑很隐蔽,因为代码看起来业务顺序没问题:查订单、查库存、组装返回。但从连接池视角看,事务没结束,连接就不能归还。高峰时每个请求多占 500ms,20 个连接很快全部被占满。
踩坑原因:连接池不是线程池
很多人会把连接池当成“数据库线程池”,觉得大一点就更能扛。实际上连接池是一个稀缺资源闸口,连接越多,数据库端压力也越大。应用把池调大,数据库未必接得住,锁等待、IO、CPU 都可能继续放大。
HikariCP 的优势是轻量和稳定,但它不会替你修复慢 SQL、长事务、连接泄漏、错误的流式查询关闭方式。池满时先调大参数,就像听到烟雾报警器响了先把电池拆掉。
代码案例:快拿快还,别把远程调用塞进事务
下面的对比是我 review Java 项目时经常指出的问题。坏写法里,事务包住了远程调用;好写法里,数据库操作尽量短,远程补充信息放到事务外,并且连接池参数更强调快速失败和泄漏发现。

@Service
public class OrderQueryService {
private final OrderMapper orderMapper;
private final StockClient stockClient;
public OrderDetail detail(long orderId) {
Order order = loadOrder(orderId); // 事务短,连接尽快归还
Stock stock = stockClient.query(order.getSkuId());
return OrderDetail.of(order, stock);
}
@Transactional(readOnly = true)
public Order loadOrder(long orderId) {
return orderMapper.selectById(orderId);
}
}
如果你用 JPA,也要注意懒加载边界。事务外访问懒加载字段会抛异常,事务里做太多事情又会拉长连接占用时间。我的习惯是查询层返回明确 DTO,少把实体对象带着事务上下文到处跑。
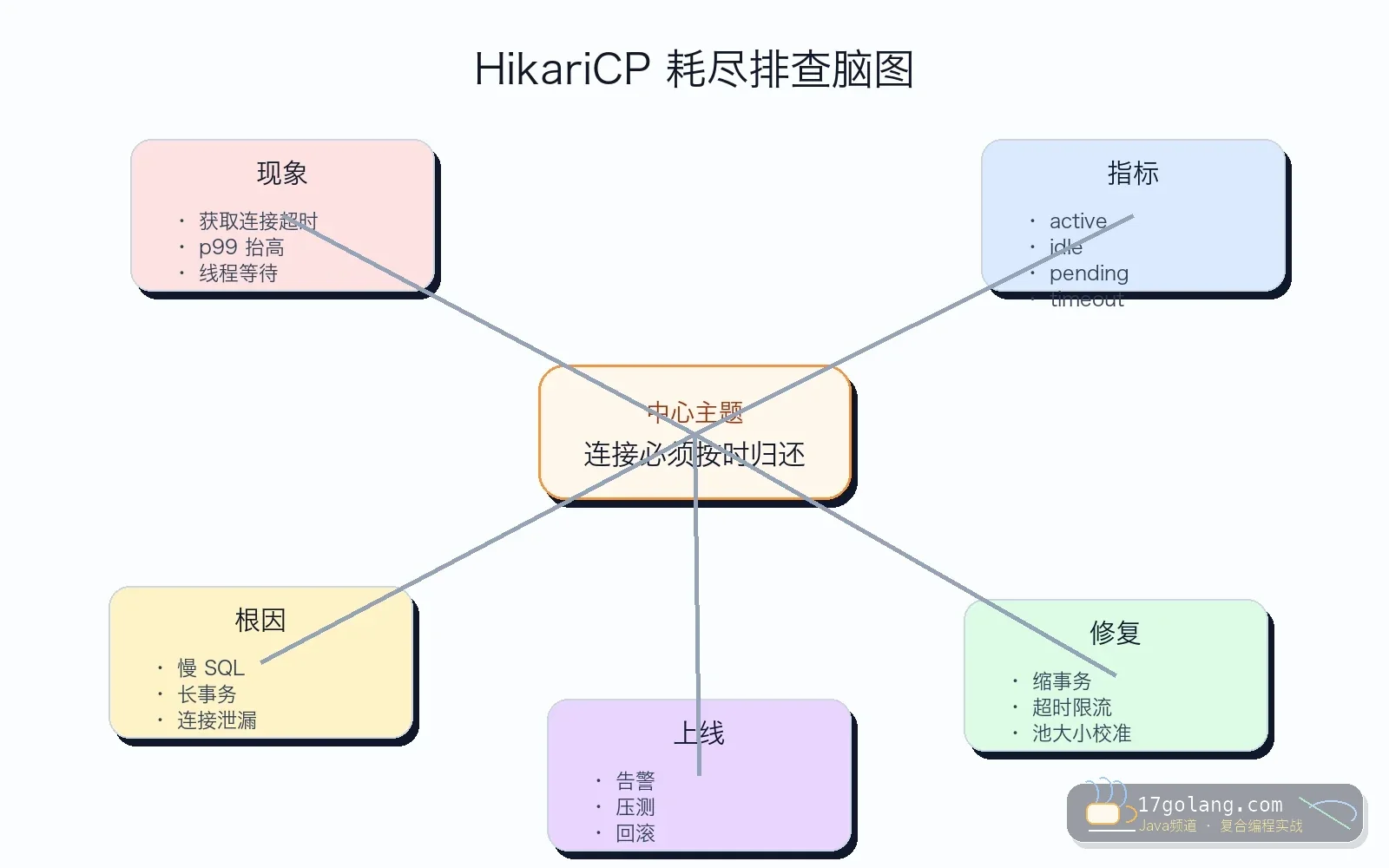
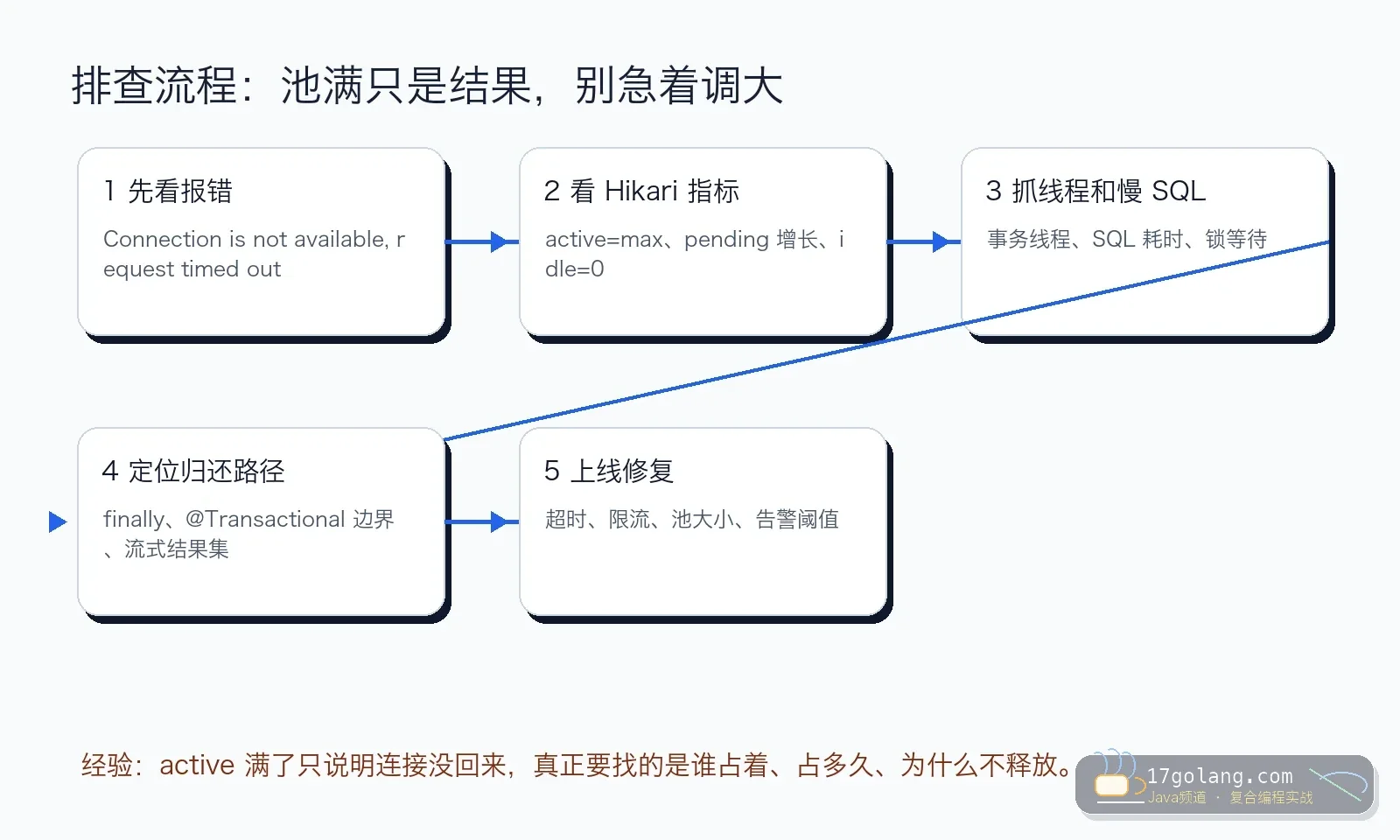
诊断步骤:我会按这六个证据查
第一,看 Hikari 指标。 重点不是只看 active,而是 active、idle、pending、timeout 一起看。active 接近 max、idle 长时间为 0、pending 增长,基本就能确认池处于耗尽状态。
第二,看慢 SQL。 如果 SQL 本身 2 秒,连接当然 2 秒回不来。先找 top SQL、执行计划、锁等待,再谈连接池。
第三,看事务边界。 搜索 @Transactional 方法里是否有远程 HTTP、消息发送、文件处理、复杂计算。事务越长,连接占用越久。
第四,看连接泄漏。 可以在预发或短时间生产窗口打开 leakDetectionThreshold,让日志指出可能长时间未归还连接的调用栈。阈值不要设太低,否则会制造噪音。
第五,看线程堆栈。 如果大量业务线程卡在获取连接,说明池已经成为入口瓶颈;如果大量线程卡在数据库驱动读写,说明连接拿到了但 SQL 或网络慢。
第六,看数据库端。 应用侧只能看到池,数据库侧才能看到锁、活跃会话、慢查询和资源水位。两边时间线要对齐。
上线检查:改参数也要有理由
maximumPoolSize要结合数据库承载、实例数、接口并发和 SQL 耗时估算。connectionTimeout不要过长,用户请求等 60 秒通常没有意义。- 长事务必须拆短,远程调用、文件处理、消息发送不要放在事务里。
- 对
hikaricp.connections.active、idle、pending、timeout做告警。 - 灰度后对比 p95/p99、数据库慢 SQL、连接池 pending 和错误率。
我的经验总结
HikariCP 连接池耗尽很少是单一参数问题。更多时候,它是慢 SQL、长事务、下游抖动、连接泄漏和容量估算一起暴露出来的结果。你可以调参数,但要先拿到证据。
我最推荐的处理顺序是:先恢复服务,限制流量或临时扩容;再用指标和堆栈定位连接占用;最后缩短事务、优化 SQL、补齐告警。Java 后端服务要稳,不是把池调到最大,而是让每个连接都尽快、有序、可观测地回家。




