Redis 缓存雪崩治理实战:TTL 抖动、预热和降级保护怎么做
来源:17golang原创
时间:2026-06-13 07:51:42 139浏览 收藏
缓存雪崩不是 Redis 本身突然变慢,而是大量缓存键在同一时间失效,请求同时绕过缓存打到数据库。线上表现通常很直接:接口延迟突然升高、数据库连接数飙升、错误率开始抬头,过几分钟又像什么都没发生。
本文用“商品详情页缓存”做例子,把雪崩链路拆开,再给出三类常用治理手段:TTL 抖动、热点数据预热、降级保护。重点不是把代码写得复杂,而是让缓存失效这件事变得分散、可控、可观察。
摘要
如果一批缓存使用完全相同的过期时间,那么在流量高峰期会出现集中失效。治理思路可以分三步:第一,给 TTL 加随机抖动,避免同一秒过期;第二,把热点数据提前预热,减少冷启动;第三,在缓存重建失败或数据库压力升高时启用降级保护,优先保证核心页面可用。
适合人群
适合正在使用 Redis 做查询缓存、商品缓存、配置缓存的后端开发者。你只需要了解 Redis 基本读写、TTL 过期、数据库查询流程,就能按文中的步骤在项目里改造。
目录
- 为什么会发生缓存雪崩
- 给 TTL 增加抖动,先拆散过期时间
- 热点数据预热,别等用户触发冷缓存
- 降级保护:缓存重建失败也要稳住数据库
- 上线检查清单
一、为什么会发生缓存雪崩
最常见的诱因是“批量写入 + 固定 TTL”。例如每天凌晨导入商品数据后统一写入缓存,并给所有商品详情设置 30 分钟过期。半小时后,这批 key 几乎同时失效,用户请求会从缓存命中变成缓存未命中,数据库会在短时间内承接大量查询。
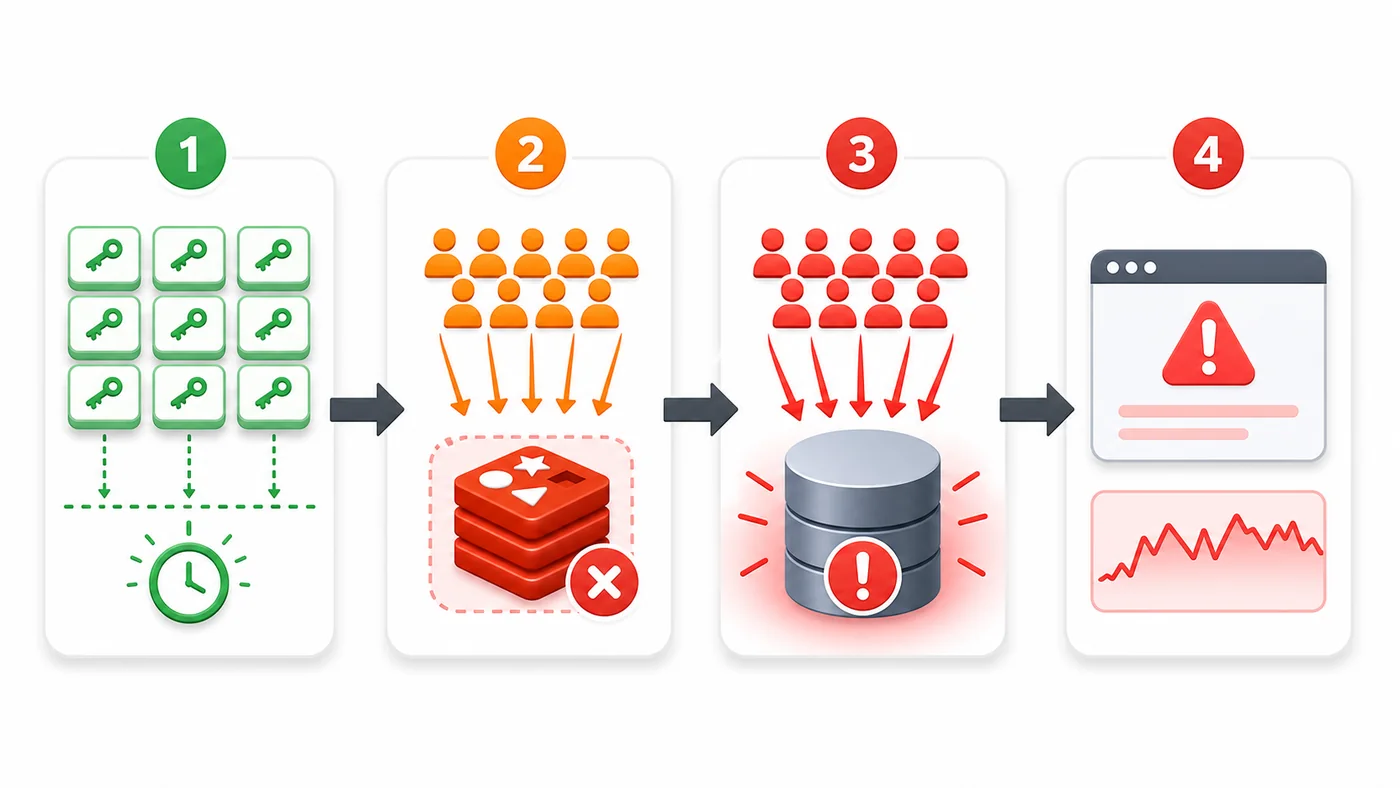
上图可以看成一次典型雪崩:第一步,一批缓存有相近的失效时间;第二步,用户请求集中到达,缓存未命中;第三步,请求一起查数据库;第四步,页面开始变慢,错误率和重试量进一步放大压力。
一个容易踩坑的写法
setex($key, 1800, json_encode($product, JSON_UNESCAPED_UNICODE)); }
这段代码本身能跑,也不一定马上出问题。真正的风险在于:当同类数据被批量写入时,固定 TTL 会把很多 key 的失效时间排到一起。流量越集中,这个问题越明显。
二、给 TTL 增加抖动,先拆散过期时间
TTL 抖动是最便宜、最先该做的治理动作。做法很简单:在基础过期时间上加一个随机范围,让同一批缓存不要在同一秒失效。比如基础 TTL 是 30 分钟,可以随机增加 0 到 10 分钟。
setex($key, $ttl, json_encode($product, JSON_UNESCAPED_UNICODE)); }
抖动范围不建议太小。假设有 10 万个商品详情缓存,随机范围只有 10 秒,流量仍然可能被压到很窄的窗口。实际项目里可以按数据量、访问峰值和缓存重建成本设置 5 到 30 分钟的随机区间。
三、热点数据预热,别等用户触发冷缓存
TTL 抖动能拆散过期时间,但它解决不了另一个问题:服务刚发布、Redis 刚迁移、或者大促开始前,热点 key 可能还没有缓存。此时如果完全依赖用户请求触发重建,第一波用户就会替系统“探路”。
预热的目标是把明确的热点数据提前写入缓存。商品详情、首页配置、热门榜单、活动会场数据,都适合预热。预热任务最好有数量限制和失败记录,避免一次任务把数据库扫得太重。
findVisibleById($id);
if (!$product) {
continue;
}
$key = 'product:detail:' . $id;
$ttl = buildCacheTtl(3600, 900);
$redis->setex($key, $ttl, json_encode($product, JSON_UNESCAPED_UNICODE));
}
}
预热不是越多越好。建议先从“访问量最高、重建成本最高、对用户路径最关键”的数据开始。比如首页首屏、热门商品详情、限时活动配置,比全量商品更值得优先预热。
四、降级保护:缓存重建失败也要稳住数据库
缓存未命中时,很多请求会同时尝试重建同一个 key。如果没有保护,就会出现“缓存没扛住,数据库也被打满”的连锁反应。这里可以组合三件事:互斥重建、短暂等待、旧值兜底。
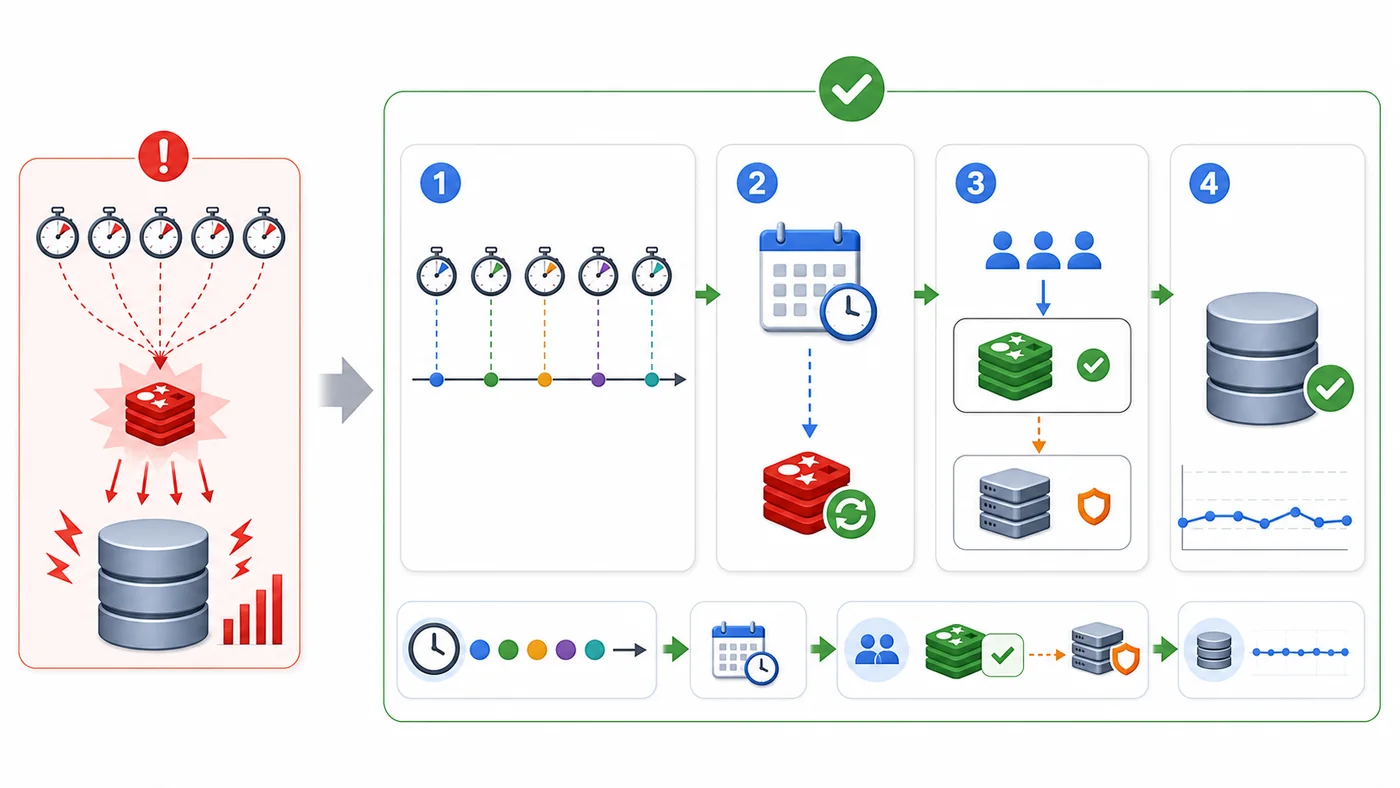
修复后的链路应该是这样的:缓存过期时间被拆散,预热任务提前刷新热点 key;当少量请求仍然遇到未命中时,只允许一个请求查询数据库并回填缓存;其他请求短暂等待,或读取一份可接受的旧值,避免所有请求一起压到数据库。
互斥重建示例
get($key);
if ($cached !== false) {
return json_decode($cached, true);
}
$token = bin2hex(random_bytes(8));
$locked = $redis->set($lockKey, $token, ['nx', 'ex' => 8]);
if ($locked) {
try {
$product = $repo->findVisibleById($id);
if (!$product) {
return null;
}
$payload = json_encode($product, JSON_UNESCAPED_UNICODE);
$redis->setex($key, buildCacheTtl(1800, 600), $payload);
$redis->setex($staleKey, 7200, $payload);
return $product;
} finally {
if ($redis->get($lockKey) === $token) {
$redis->del($lockKey);
}
}
}
usleep(80000);
$retry = $redis->get($key);
if ($retry !== false) {
return json_decode($retry, true);
}
$stale = $redis->get($staleKey);
if ($stale !== false) {
return json_decode($stale, true);
}
return null;
}
这段代码有两个关键点。第一,锁的过期时间要短,防止异常情况下锁长时间存在。第二,旧值缓存不是长期正确数据,只是压力高时的保护垫,适合用于商品展示、配置读取、榜单等可以接受短暂延迟更新的场景。
五、上线检查清单
缓存雪崩治理改完以后,不要只看本地能不能跑。建议至少检查下面几项:
- 缓存 TTL 是否有随机抖动,批量写入时是否仍然集中到同一分钟。
- 热点 key 是否有预热入口,预热任务是否限制批量大小。
- 缓存未命中时,是否只有一个请求负责重建同一个 key。
- 数据库查询失败或超时时,是否有可接受的旧值兜底。
- 监控里是否能看到缓存命中率、数据库 QPS、接口耗时和错误率。
压测时可以模拟“删除一批热点 key 后再打流量”。如果数据库 QPS 瞬间升高很多,说明重建保护还不够;如果接口短暂变慢但数据库没有被打穿,说明治理方向是有效的。
常见问题
1. TTL 抖动会不会导致缓存更难清理?
不会。抖动只是让过期时间分散,不改变缓存删除和主动更新策略。对于强一致要求高的数据,仍然建议在业务写入后主动删除或更新对应 key。
2. 旧值兜底会不会展示脏数据?
要看业务场景。价格、库存、支付状态这类强准确数据不适合旧值兜底;商品描述、首页配置、排行榜这类展示型数据,可以接受短时间旧值。关键是给旧值设置明确的最长保留时间,并在页面或接口层做好业务边界。
3. 只加 Redis 集群能解决雪崩吗?
不能完全解决。集群能提高 Redis 层的容量,但缓存一起失效后,压力最终会落到数据库和后端服务。治理雪崩的核心仍然是分散失效、控制重建、准备兜底。
总结
Redis 缓存雪崩的本质是“失效时间太集中,重建流量太集中”。实战中可以先从 TTL 抖动开始,低成本拆散过期时间;再对热点数据做预热,减少冷启动压力;最后给缓存重建加互斥和旧值兜底,让数据库在异常窗口里不被瞬时流量打满。
把这三步落到代码、任务和监控里,缓存就不再只是提升速度的工具,也会成为系统稳定性的一部分。
-
374 收藏
-
398 收藏
-
117 收藏
-
426 收藏
-
298 收藏
-
280 收藏
-
数据库 · Redis | 5天前 | Redis · 缓存治理 · Keyspace Notifications · 过期事件 · redis Pub/Sub Keyspace Notifications 过期事件 缓存监听 补偿任务181 收藏
-
501 收藏
-
400 收藏
-
313 收藏
-
235 收藏
-
464 收藏
-
436 收藏
-
407 收藏
-
数据库 · Redis | 2星期前 | Redis · Streams · 消费者组 · Pending · XACK · 消息堆积 消费者组 XACK XPENDING XAUTOCLAIM Redis Streams385 收藏
-
194 收藏
-
368 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习