MySQL LIKE 模糊查询变慢怎么办:从左通配符到前缀索引一步步排查
来源:17golang原创
时间:2026-06-15 14:09:49 308浏览 收藏
一个商品后台搜索框上线后,运营输入关键字“phone”,列表从几十毫秒变成几秒。第一反应可能是“数据太多了”,但我们先别急着加机器。MySQL 里 `LIKE` 的写法很容易让索引从可用变成不可用,尤其是左侧带通配符的查询。
这篇文章我们按排查现场来走:先复现慢查询,再看执行计划,接着验证不同 `LIKE` 写法对索引的影响,最后给出能落地的改法。
摘要
`LIKE 'abc%'` 通常可以利用普通 BTree 索引做范围查找,而 `LIKE '%abc%'` 很难直接用上前缀有序的索引。遇到搜索变慢时,应先确认条件写法、执行计划、返回行数和业务搜索目标,再决定是改成前缀匹配、增加冗余字段、使用全文索引,还是交给搜索服务。
适合人群
适合正在维护 MySQL 搜索接口、商品后台、用户列表、订单备注查询的开发同学。文章示例以 `products` 表为例,重点讲排查思路。
目录
- 问题现场:一个搜索框把查询拖慢了
- 第一轮验证:看 LIKE 条件怎么写
- 继续定位:执行计划说明了什么
- 修复方案:按搜索目标选择改法
- 常见坑和最终检查
问题现场:一个搜索框把查询拖慢了
先看一个常见查询。商品表里有 `name` 字段,也建了普通索引:
CREATE INDEX idx_products_name ON products(name); SELECT id, name, price FROM products WHERE name LIKE '%phone%' LIMIT 20;
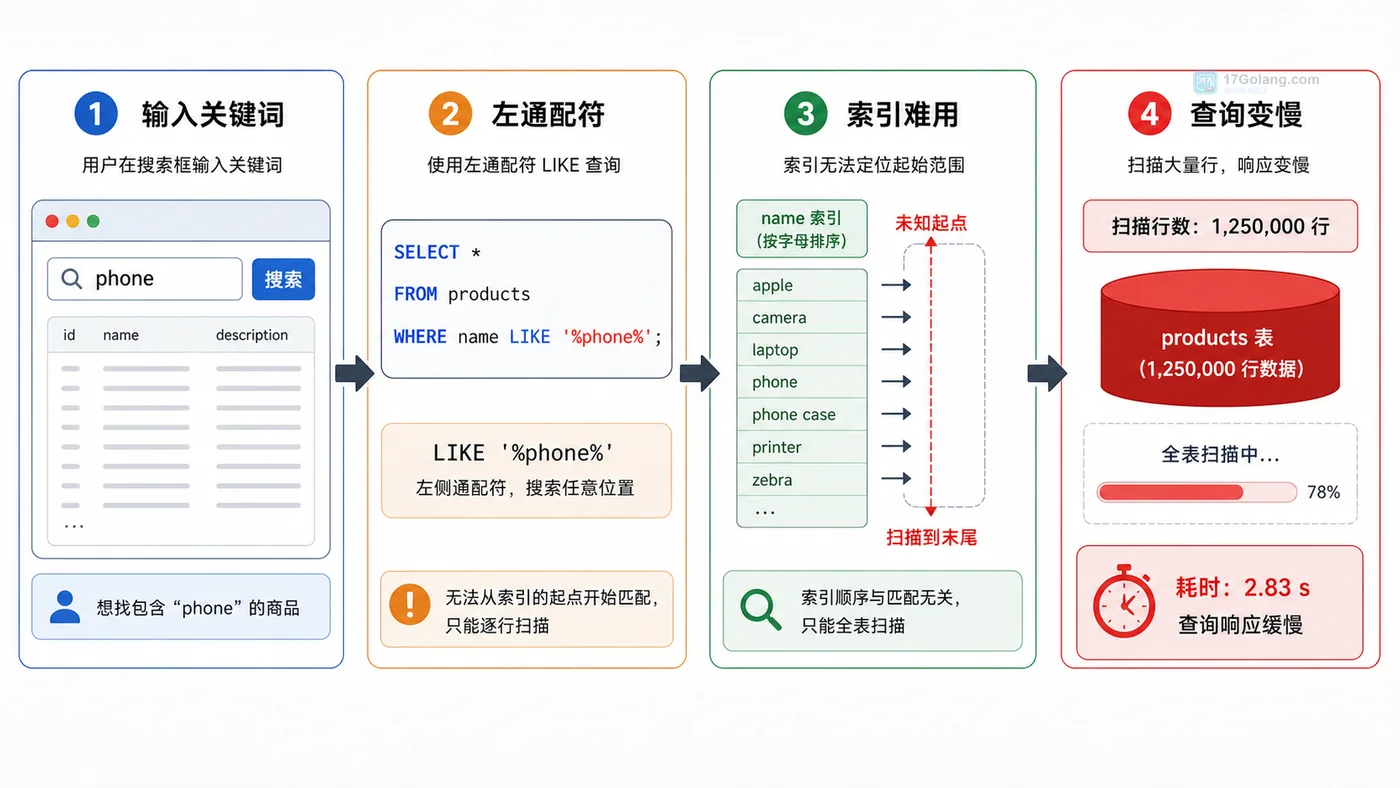
看起来已经有索引,为什么还是慢?我们先做一个小判断:如果条件是“包含 phone”,数据库必须从任意位置找这个词。普通索引按字段从左到右排序,无法直接从中间字符定位起点。
第一轮验证:看 LIKE 条件怎么写
我们把两个查询放在一起比较:
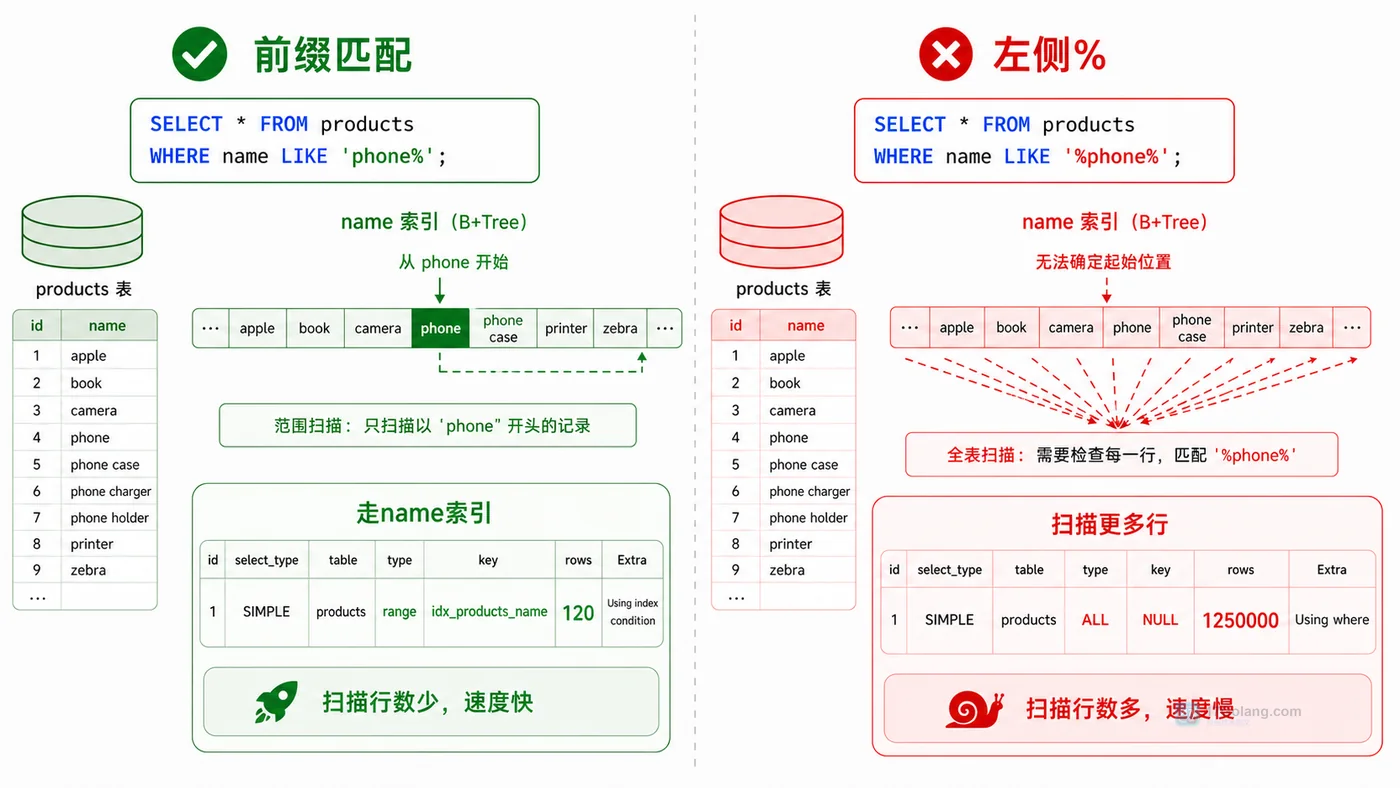
-- 前缀匹配:有明确起点 SELECT id, name FROM products WHERE name LIKE 'phone%'; -- 包含匹配:从任意位置找 SELECT id, name FROM products WHERE name LIKE '%phone%';
第一条是前缀匹配,索引可以从 `phone` 附近开始扫描;第二条左侧有 `%`,相当于告诉数据库“开头是什么我不知道”,索引的有序性就很难发挥作用。
这一步我们先得到一个猜测:慢的根因不是“没有索引”,而是查询条件让这个索引用不上。
继续定位:执行计划说明了什么
接着看执行计划。为了让问题可见,我们对两条 SQL 分别查看:
EXPLAIN SELECT id, name FROM products WHERE name LIKE 'phone%'; EXPLAIN SELECT id, name FROM products WHERE name LIKE '%phone%';
如果前缀匹配能走 `idx_products_name`,而包含匹配扫描行数明显更大,就说明判断方向是对的。此时不要只看 `key` 有没有显示索引,还要看 `rows` 估算数量和过滤比例。
我们再补一个验证:把关键字从 `%phone%` 改成 `phone%` 后,如果响应时间明显下降,就能确认左通配符是主要原因。
修复方案:按搜索目标选择改法
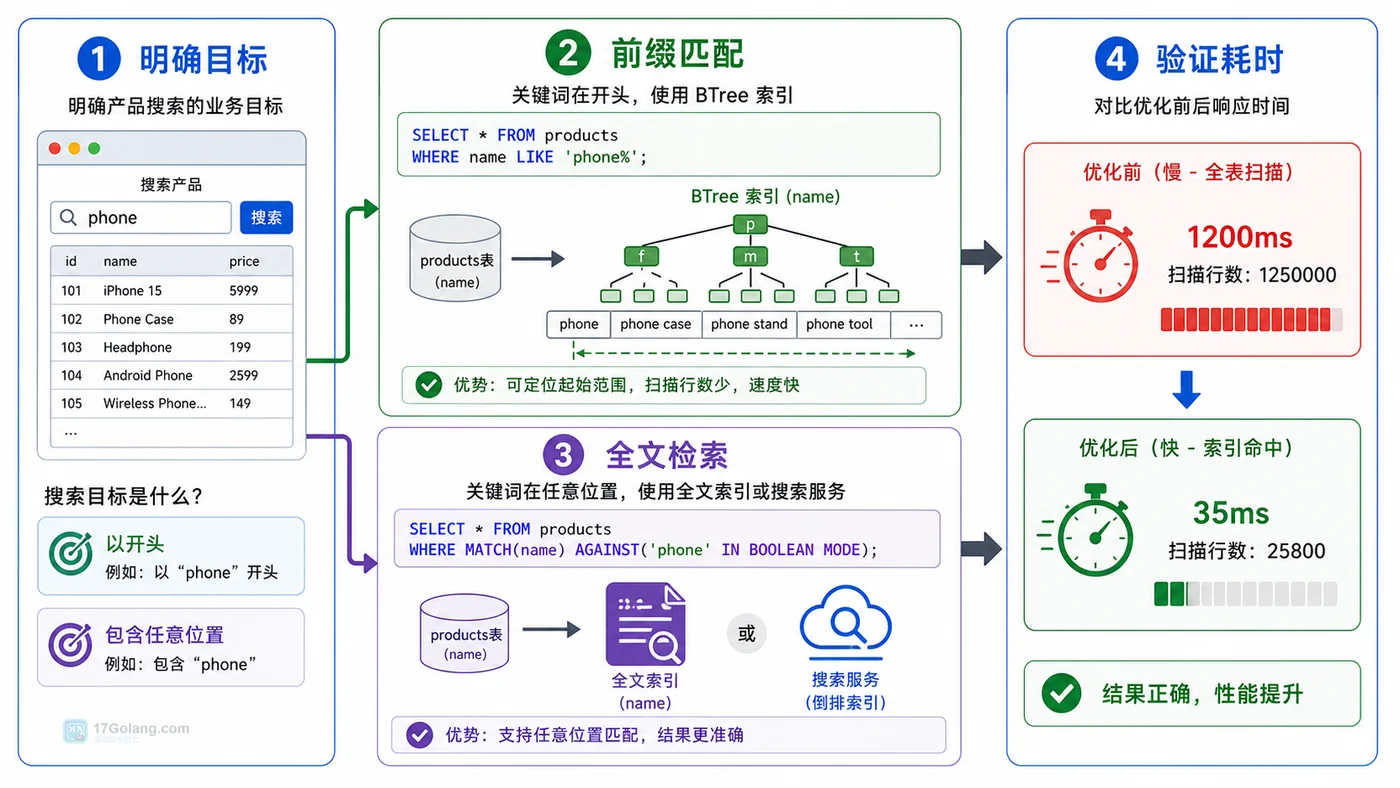
现在进入修复。第一种情况:业务只需要从开头匹配,比如商品编码、用户名、手机号前缀。那就把查询改成前缀匹配:
SELECT id, name, price FROM products WHERE name LIKE 'phone%' ORDER BY id DESC LIMIT 20;
第二种情况:用户确实要搜“包含关键字”。这时普通索引不是最适合的工具,可以考虑把搜索字段拆出关键词表、使用 MySQL 全文索引,或者把搜索交给专门的搜索服务。
CREATE FULLTEXT INDEX ft_products_name ON products(name);
SELECT id, name, price
FROM products
WHERE MATCH(name) AGAINST('phone');
第三种情况:只需要某些固定片段,比如订单号后四位、手机号后四位。可以增加冗余字段,例如 `phone_suffix`,让查询重新变成等值或前缀匹配,而不是在原字段中间找。
常见坑和最终检查
第一个坑是“有索引就一定快”。索引要和查询条件匹配,左侧通配符会破坏从索引起点查找的能力。
第二个坑是盲目给长文本字段加普通索引。备注、描述、正文这类字段更适合先明确搜索目标,再决定全文索引或搜索服务。
第三个坑是只看平均耗时。搜索词不同,命中范围也不同。要拿高频词、低频词、空结果词分别测,避免只优化了一个样例。
最终检查可以按这几步走:
EXPLAIN SELECT id FROM products WHERE name LIKE 'phone%'; EXPLAIN SELECT id FROM products WHERE name LIKE '%phone%'; SELECT COUNT(*) FROM products WHERE name LIKE 'phone%';
如果前缀查询走了目标索引,扫描行数下降,接口响应时间也稳定到可接受范围,就说明这次改法有效。包含搜索如果仍是核心需求,就应该升级搜索方案,而不是继续在一个普通索引上硬扛。
总结
MySQL `LIKE` 模糊查询变慢时,排查顺序要清楚:先看条件是不是左侧通配符,再看执行计划和扫描行数,最后根据业务到底要“前缀搜索”还是“包含搜索”选择方案。
普通索引擅长从左到右定位范围,不擅长在字段中间找词。把搜索目标讲清楚,查询写法和索引设计才能对上,搜索接口也会稳定很多。
-
499 收藏
-
244 收藏
-
235 收藏
-
157 收藏
-
101 收藏
-
数据库 · MySQL | 2小时前 | MySQL · 数据库 · 联合索引 · ORDER BY · 慢查询排查 · mysql order by explain 慢查询 联合索引 filesort203 收藏
-
261 收藏
-
455 收藏
-
381 收藏
-
336 收藏
-
152 收藏
-
404 收藏
-
339 收藏
-
429 收藏
-
159 收藏
-
数据库 · MySQL | 6天前 | 性能优化 · 执行计划 · MySQL教程 · 慢查询治理 · 数据库运维 · mysql GROUP BY优化 TempTable 内部临时表 Created_tmp_disk_tables267 收藏
-
数据库 · MySQL | 1星期前 | 性能优化 · InnoDB · MySQL教程 · 数据库运维 · 高并发写入 · mysql innodb 批量写入 Change Buffer innodb_change_buffering270 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习