AI 知识库回答跑偏怎么办:RAG 检索、重排和引用检查完整流程
来源:17golang原创
时间:2026-06-16 13:47:43 419浏览 收藏
很多团队接入 AI 知识库后,最先遇到的不是“完全答不出来”,而是“看起来答了,但答案跑偏”。用户问的是退款规则,模型却拿到了注册流程;用户问的是某个版本配置,答案却混进了旧文档。
这类问题不能只怪模型。RAG 知识库问答是一条链路:问题怎么改写、片段怎么命中、结果怎么排序、低相关片段怎么过滤、答案有没有引用支撑。只看最后一句回答,很难定位问题。
摘要
RAG 回答跑偏通常不是单点问题,而是检索链路和生成链路共同造成的。推荐按固定顺序排查:先保存原始问题和改写问题,再查看命中片段,接着检查 TopK、分数阈值和重排结果,最后要求答案必须带引用;证据不足时不要硬答,应该进入拒答兜底。
适合人群
- 正在做企业知识库、客服问答、内部文档助手的开发者。
- 遇到过 AI 回答“貌似合理但来源不对”的工程同学。
- 想把 RAG 从演示效果推进到线上可维护流程的团队。
- 目标和边界
- 全流程总览
- 阶段一:固定原始问题和改写问题
- 阶段二:检查命中片段是否真的相关
- 阶段三:用阈值和引用检查拦住跑偏回答
- 阶段四:建立小样本复查集
- 我的推荐流程
- 容易踩坑
- 落地清单
目标和边界
本文的目标不是讲一个“万能提示词”,而是给出一套可复查的 RAG 排查流程。我们假设系统已经有文档切片、向量索引、模型问答三个基本模块,现在的问题是:答案经常偏离用户问题,或者引用不到真正支撑答案的片段。
边界也要先说清楚:如果知识库本身没有这条信息,RAG 不应该强行编答案;如果文档版本混乱,单靠调参数也解决不了。本文关注的是工程侧如何定位问题、收紧结果、保留证据。
全流程总览
先把链路拆开。一次可靠的知识库问答,至少要经过下面五步:用户提问、问题改写、向量检索、重排过滤、引用回答。
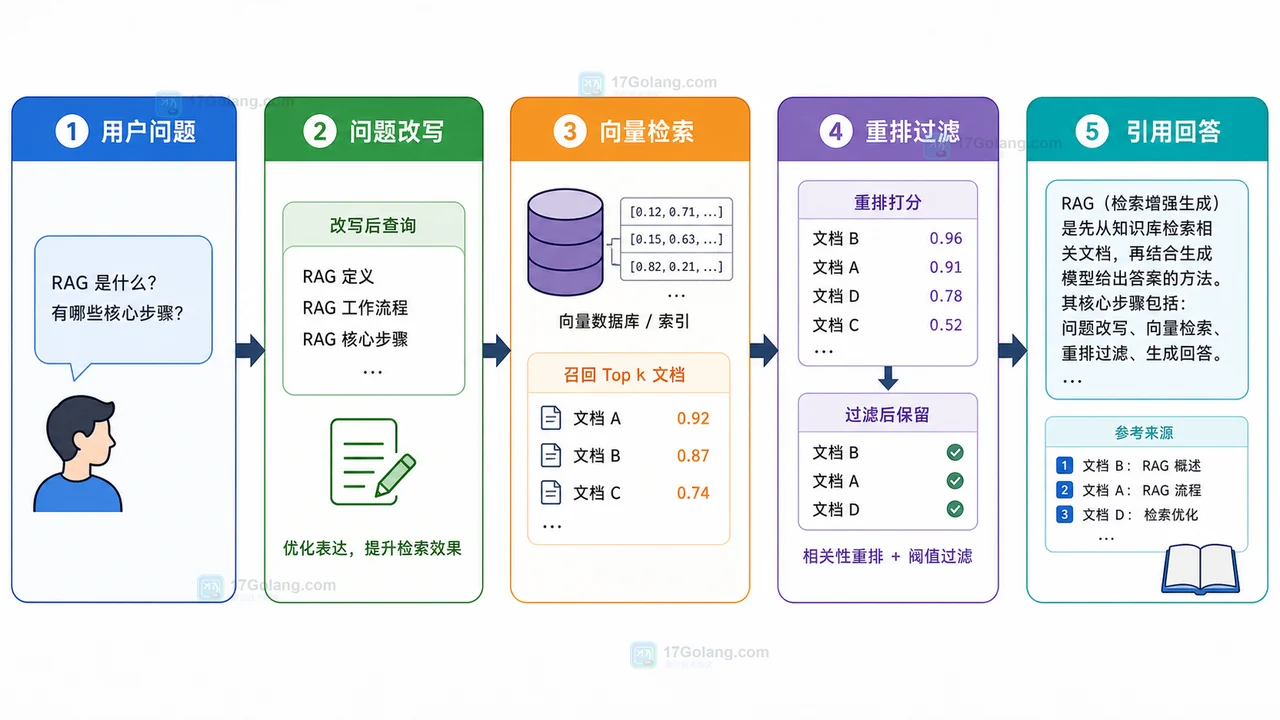
| 阶段 | 目标 | 关键动作 | 检查点 |
|---|---|---|---|
| 问题改写 | 让问题更适合检索 | 补充同义词、保留关键限制 | 改写后没有改变用户原意 |
| 向量检索 | 找到候选片段 | 设置 TopK,返回相关分数 | 前几条片段能直接回答问题 |
| 重排过滤 | 剔除低相关片段 | 按相关性重排,设置最低分数 | 最终上下文不混入噪声 |
| 引用回答 | 让答案可追溯 | 答案必须绑定文档片段 | 每个关键结论都有来源 |
阶段一:固定原始问题和改写问题
到这一步不要急着调 TopK。先把用户原始问题和系统改写后的问题都记录下来。很多跑偏问题,其实从改写阶段就开始偏了。
{
"raw_question": "会员退款后还能恢复权益吗?",
"rewritten_question": "会员退款 恢复权益 退款规则 权益状态",
"trace_id": "qa-20260616-001"
}
检查点有两个:
- 改写问题是否保留了用户限制,例如“退款后”“恢复权益”。
- 改写问题是否引入了不存在的方向,例如把退款问题改成支付失败问题。
如果改写阶段已经偏了,后面检索再强也会命中错误片段。
阶段二:检查命中片段是否真的相关
接着看命中的候选片段。这里不要只看模型最终回答,要把“命中了哪些片段、分数是多少、片段来自哪篇文档”打印出来。
[
{
"doc": "会员退款规则",
"section": "退款后权益状态",
"score": 0.82,
"text": "退款完成后,会员权益会在订单关闭时失效..."
},
{
"doc": "会员开通流程",
"section": "权益生效时间",
"score": 0.51,
"text": "会员开通后,权益通常在数分钟内生效..."
}
]
如果第一条片段就不相关,优先检查切片方式、向量索引和问题改写。如果前几条相关、后面混入大量弱相关内容,就要进入下一阶段:收紧 TopK、分数阈值和重排策略。
阶段三:用阈值和引用检查拦住跑偏回答
一个常见错误是 TopK 设置很大,系统把二十段候选片段全部塞给模型。看起来上下文更多,但低相关片段也更容易混进来,模型会在噪声里找一个貌似合理的答案。
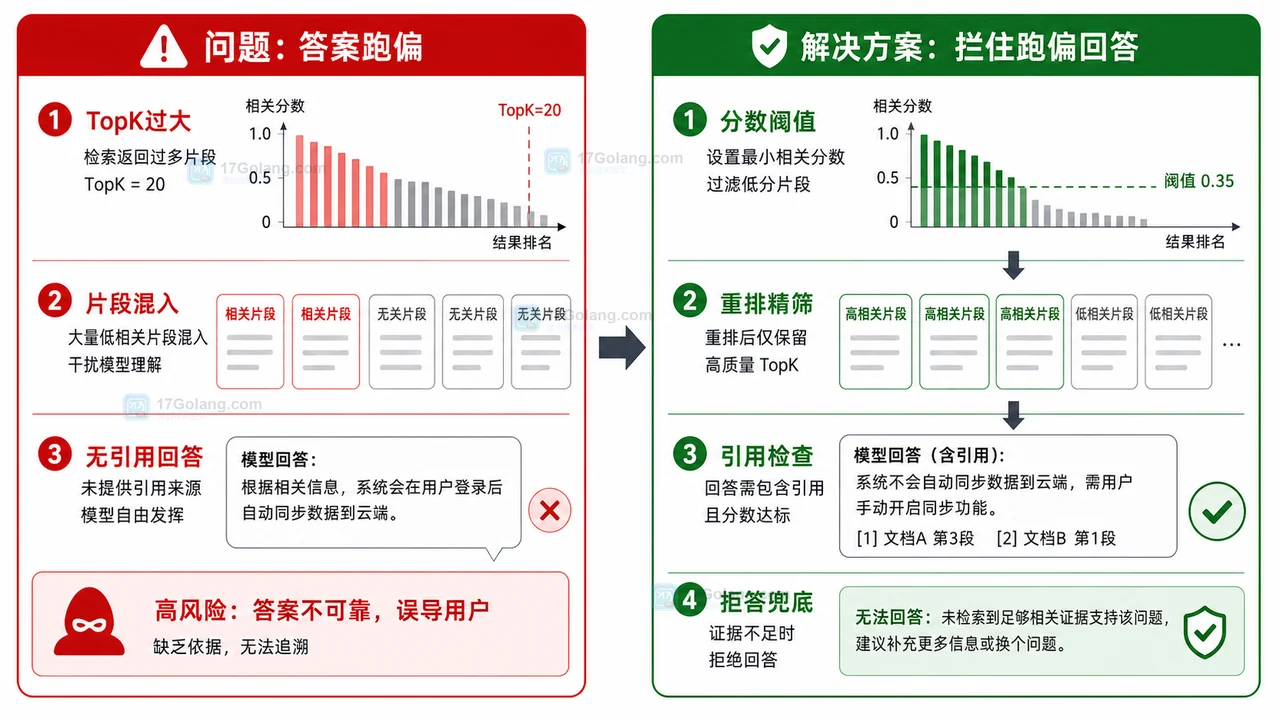
建议把候选结果分成三层处理:
- 先用向量检索拿到候选片段,不要直接全部交给模型。
- 再做重排或规则过滤,只保留最相关的少量片段。
- 最后检查答案是否引用了足够片段;证据不足时进入拒答兜底。
{
"top_k": 8,
"min_score": 0.35,
"max_context_chunks": 4,
"require_citation": true,
"fallback": "没有检索到足够相关的知识库内容,请补充问题或换个问法。"
}
这里的数值不是固定标准,需要结合业务数据调整。关键是系统必须有“低于阈值就不硬答”的机制。
阶段四:建立小样本复查集
排查不能只靠一条问题。建议准备一个小样本集,覆盖高频问题、容易混淆的问题、旧版本和新版本都出现过的问题。
| 样本类型 | 检查目标 | 通过标准 |
|---|---|---|
| 高频问法 | 命中稳定性 | 核心片段排在前列 |
| 相似问题 | 区分能力 | 不会把退款、续费、开通混在一起 |
| 证据不足 | 拒答能力 | 不编造,不硬答 |
| 版本差异 | 文档版本控制 | 回答引用正确版本片段 |
这个小样本集的价值是让调参可复查。每次修改切片、TopK、阈值或提示词,都用同一批样本比较前后结果。
我的推荐流程
- 保存用户原始问题、改写问题、命中片段、分数和最终答案。
- 先检查问题改写是否改变原意,必要时减少自动扩写。
- 查看前 5 条命中片段,确认是否能直接支撑答案。
- 收紧 TopK,加入最低分数阈值,避免低相关片段进入上下文。
- 增加重排过滤,把最相关片段放到更靠前的位置。
- 要求答案带引用;没有足够引用时返回兜底话术。
- 用固定小样本集复查,不只看单条效果。
容易踩坑
只调提示词,不看命中片段
如果传给模型的上下文本身就是错的,再好的提示词也只能在错误材料里组织答案。先看片段,再看回答。
TopK 越大越放心
TopK 太大容易混入噪声。更稳的做法是先召回候选,再通过重排、阈值和引用检查收紧。
答案没有来源也直接返回
知识库问答的可信度来自可追溯来源。没有引用,就很难判断答案是来自文档还是模型自行补全。
落地清单
| 检查项 | 是否必须 | 建议做法 |
|---|---|---|
| 记录 trace_id | 必须 | 把问题、片段、分数、答案串起来。 |
| 检查改写问题 | 必须 | 确认没有改变用户真实意图。 |
| 设置最低分数 | 建议 | 低相关片段不要进入最终上下文。 |
| 要求引用 | 必须 | 答案关键结论要能回到原文片段。 |
| 拒答兜底 | 必须 | 证据不足时明确说明,而不是猜答案。 |
总结
AI 知识库回答跑偏,表面看是模型问题,实际常常是 RAG 链路没有被拆开观察。只要把原始问题、改写问题、命中片段、分数、重排结果和引用答案都记录下来,问题就会从“模型乱答”变成可定位的工程节点。
我的建议是:先看命中片段,再调阈值和重排;先要求引用,再允许输出答案;证据不足时要敢于拒答。这样知识库问答才更接近线上可维护系统,而不是一次性演示。
-
284 收藏
-
387 收藏
-
328 收藏
-
426 收藏
-
147 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习