Java CompletableFuture 接口聚合工作流:从超时边界到降级返回
来源:17golang原创
时间:2026-06-22 17:13:02 365浏览 收藏
用户首页接口经常要同时读取用户资料、最近订单、优惠信息等多个数据源。如果每个依赖都串行调用,页面会被最慢的一段拖住;如果只把调用改成并发,又容易在超时、异常和空数据上留下隐患。本文用一个可落地的 Java CompletableFuture 工作流,把接口聚合从目标边界、阶段拆解到最终检查串起来。
先说结论:接口聚合不要只追求“并发更快”,更重要的是给每个分支设置独立超时、准备业务可接受的降级值、在合并前统一收口,并用日志和耗时指标确认效果。下面的示例以 JDK 11 及以上为参考,不展开线程池容量调优和网关限流。
- 目标和边界:先定义接口能承受什么
- 全流程总览:并发拉取、超时边界、降级值、页面返回
- 阶段一:拆出互不依赖的数据分支
- 阶段二:给每个分支设置超时和降级
- 阶段三:统一合并并保留可观测信号
- 我的推荐流程
- 常见误区
- 落地速查表
目标和边界:先定义接口能承受什么
这个方案要解决的是“一个页面接口依赖多个下游服务,整体响应不应该被单个慢依赖拖垮”的问题。目标不是让所有下游都百分百成功,而是在可接受的数据缺省下,让页面先稳定展示。
| 边界项 | 建议做法 | 检查点 |
|---|---|---|
| 核心资料 | 失败时返回最小用户对象 | 页面仍能展示用户名占位和基础状态 |
| 订单列表 | 失败时返回空列表 | 前端展示“暂无记录”,而不是白屏 |
| 优惠信息 | 失败时返回无优惠对象 | 结算入口不依赖优惠接口成功 |
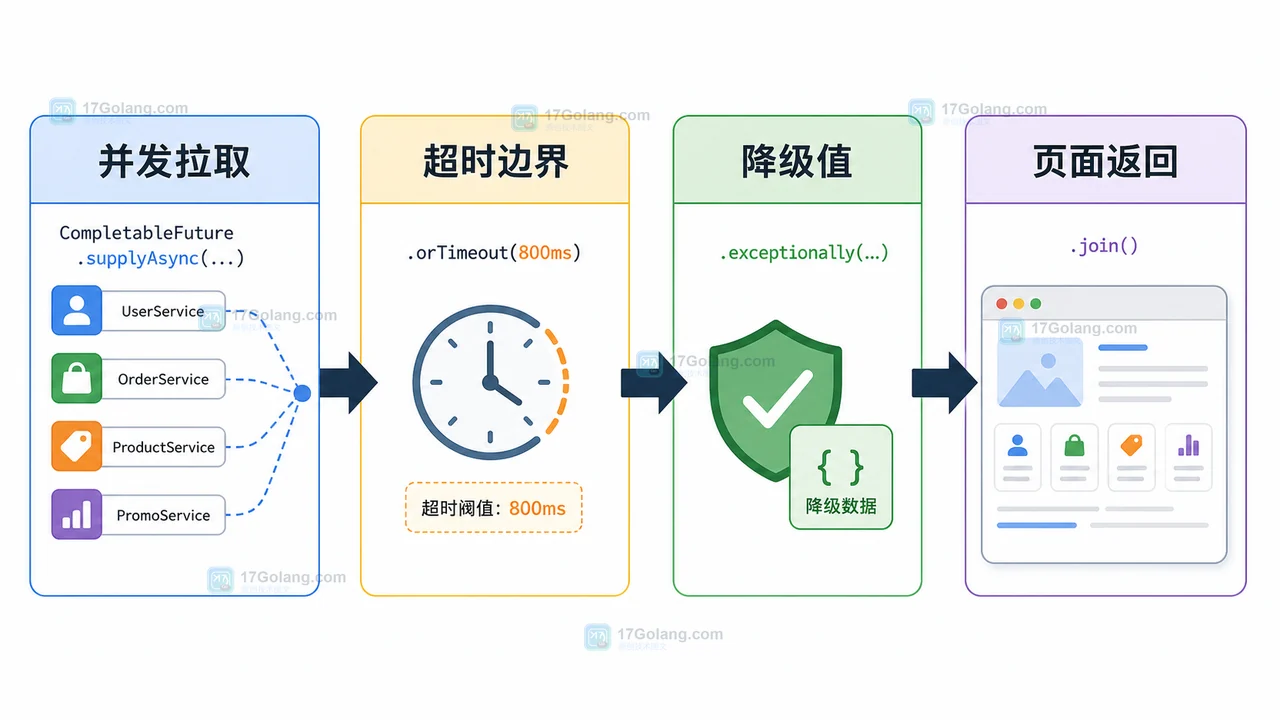
全流程总览:并发拉取、超时边界、降级值、页面返回
完整流程可以拆成四步:先把互不依赖的数据源并发拉取;再给每个分支设置自己的超时边界;接着在分支内部转成可接受的降级值;最后把所有结果合并成页面对象。这样做的好处是,慢分支只影响自己的数据,不会拖住整个接口。
阶段一:拆出互不依赖的数据分支
目标:确认哪些数据可以并行读取,哪些必须等待前置结果。用户资料、最近订单、优惠信息只依赖同一个用户编号,因此可以拆成三个分支。关键动作是把每个分支封装成一个返回明确类型的方法,避免在合并阶段再处理大量分支细节。
public class UserPageService {
private final UserClient userClient;
private final OrderClient orderClient;
private final CouponClient couponClient;
public UserPageService(UserClient userClient,
OrderClient orderClient,
CouponClient couponClient) {
this.userClient = userClient;
this.orderClient = orderClient;
this.couponClient = couponClient;
}
public UserPage page(String uid) {
CompletableFuture userFuture =
CompletableFuture.supplyAsync(() -> userClient.get(uid));
CompletableFuture> orderFuture =
CompletableFuture.supplyAsync(() -> orderClient.recent(uid));
CompletableFuture couponFuture =
CompletableFuture.supplyAsync(() -> couponClient.best(uid));
CompletableFuture.allOf(userFuture, orderFuture, couponFuture).join();
return new UserPage(userFuture.join(), orderFuture.join(), couponFuture.join());
}
}
这段代码已经把串行等待变成了并发拉取,但还不够安全:任意一个分支卡住或抛出异常,最终合并都会受到影响。因此下一阶段要把超时和降级放到每个分支内部。
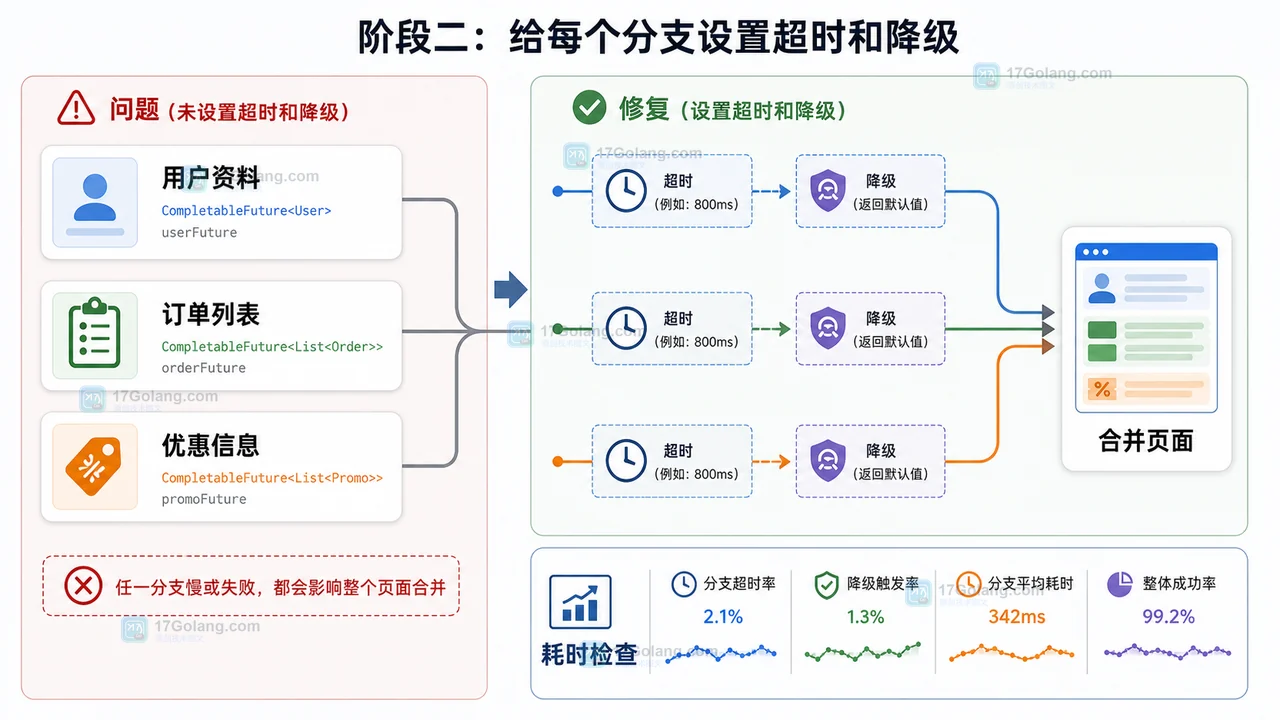
阶段二:给每个分支设置超时和降级
目标:让慢依赖在指定时间内停止影响主流程。关键动作是给每个 CompletableFuture 接上 completeOnTimeout 和 exceptionally,前者处理超时,后者处理异常。检查点是每个分支都能独立返回业务可接受的默认值。
public UserPage page(String uid) {
CompletableFuture userFuture = CompletableFuture
.supplyAsync(() -> userClient.get(uid))
.completeOnTimeout(UserInfo.empty(uid), 800, TimeUnit.MILLISECONDS)
.exceptionally(err -> UserInfo.empty(uid));
CompletableFuture> orderFuture = CompletableFuture
.supplyAsync(() -> orderClient.recent(uid))
.completeOnTimeout(List.of(), 900, TimeUnit.MILLISECONDS)
.exceptionally(err -> List.of());
CompletableFuture couponFuture = CompletableFuture
.supplyAsync(() -> couponClient.best(uid))
.completeOnTimeout(CouponView.none(), 600, TimeUnit.MILLISECONDS)
.exceptionally(err -> CouponView.none());
CompletableFuture.allOf(userFuture, orderFuture, couponFuture).join();
return new UserPage(userFuture.join(), orderFuture.join(), couponFuture.join());
}
这里的关键不是把超时时间写得越短越好,而是按业务重要性设置:用户资料可稍长,优惠信息可稍短,订单列表需要结合页面首屏要求决定。每个默认值都应该被前端识别并正常展示。
阶段三:统一合并并保留可观测信号
目标:合并页面对象时不要再让异常扩散,同时保留排查依据。关键动作有两个:第一,分支内部必须完成兜底;第二,记录每个分支的耗时、是否走了降级、最终返回的数据规模。检查点是接口返回稳定,日志能说明哪个依赖慢、哪个依赖返回了空数据。
record BranchLog(String name, long costMs, boolean fallbackUsed) {}
private T mark(String name, long costMs, T value, List logs, boolean fallbackUsed) {
logs.add(new BranchLog(name, costMs, fallbackUsed));
return value;
}
如果线上 WAF 对英文敏感子串非常严格,示例中的日志字段名可以改成中文或更短的业务名。真正上线时,更推荐把这些信号写入指标平台,而不是只依赖文本日志。
我的推荐流程
落地时可以按这个顺序推进:
- 先列出页面需要的所有数据块,标注哪些是强依赖,哪些可以缺省。
- 把互不依赖的数据块拆成独立方法,返回类型要稳定,不要返回松散对象。
- 给每个分支配置超时边界,并写清楚默认值的业务含义。
- 用 CompletableFuture.allOf 做统一等待,合并前确保分支已经完成兜底。
- 压测慢依赖场景,确认主接口耗时接近最慢超时边界,而不是多个分支耗时之和。
- 上线后观察分支耗时、降级比例、页面空数据比例,再微调边界值。
常见误区
| 误区 | 问题 | 建议 |
|---|---|---|
| 只做并发,不做超时 | 慢依赖仍然会拖住整体返回 | 每个分支都设置独立边界 |
| 默认值随便给 | 前端无法区分真实空数据和降级数据 | 为默认值设计明确业务语义 |
| 在合并阶段才处理异常 | 排查困难,分支责任不清晰 | 分支内部完成兜底,合并阶段只组装结果 |
| 没有慢依赖演练 | 上线后才发现边界值不合理 | 用测试桩模拟延迟和异常 |
落地速查表
- 能并发:数据块之间没有顺序依赖。
- 能降级:每个分支都有业务可接受的默认值。
- 能观测:每个分支有耗时、状态和数据规模记录。
- 能验证:慢依赖场景下,主接口仍能在预期边界内返回。
- 能维护:页面对象的字段含义清晰,前端能识别缺省状态。
总结一下,CompletableFuture 的价值不只是把多个调用并发起来。真正可上线的接口聚合,需要把“并发拉取、超时边界、降级值、统一合并、观测检查”放在同一个流程里。这样即使某个下游变慢,用户看到的也会是可控的缺省状态,而不是长时间等待或页面失败。
-
413 收藏
-
501 收藏
-
Golang · Go教程 | 3星期前 | goroutine · Context · 超时控制 · Go教程 · 后端开发 · Go Goroutine context 超时控制 WithTimeout Done QueryContext166 收藏
-
Golang · Go教程 | 5天前 | HTTP服务 · Go教程 · 后端开发 · 超时配置 · 服务稳定性 · net/http WriteTimeout HTTP超时 Go教程 ReadHeaderTimeout IdleTimeout140 收藏
-
Golang · Go问答 | 1星期前 | JSON · 后端开发 · Go问答 · encoding/json · 接口解析 · JSON解析 encoding/json DisallowUnknownFields Go问答 RawMessage json.Decoder UseNumber151 收藏
-
136 收藏
-
304 收藏
-
182 收藏
-
文章 · java教程 | 1星期前 | 性能优化 · Java教程 · CompletableFuture · 接口聚合 · java completablefuture orTimeout completeOnTimeout 接口性能 P95255 收藏
-
文章 · java教程 | 2星期前 | Spring Boot · Java教程 · 接口设计 · Webhook · 幂等设计 · java spring boot WebHook 回调接口 幂等 状态流转 验签488 收藏
-
文章 · java教程 | 2星期前 | Java教程 · TTL缓存 · ConcurrentHashMap · 小项目 · java 本地缓存 concurrenthashmap TTL缓存 过期淘汰394 收藏
-
355 收藏
-
495 收藏
-
455 收藏
-
文章 · java教程 | 3星期前 | hashmap · 集合 · Java教程 · hashCode · equals · java HashMap map equals hashCode 可变key474 收藏
-
178 收藏
-
文章 · java教程 | 3星期前 | map · 并发安全 · 缓存设计 · Java教程 · java optional concurrenthashmap computeIfAbsent Map缓存236 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习