Python requests 请求总是卡住?timeout、重试和错误处理配方
来源:17golang原创
时间:2026-06-27 17:57:42 478浏览 收藏
Python 项目里用 requests 调接口很顺手,但线上最常见的问题也很直接:某个外部接口慢了,调用方线程一直等,页面转圈、任务堆积、日志里只剩下“还没返回”。这篇文章按配方卡片的方式处理一个具体问题:给所有外部 HTTP 请求加上合理的 timeout、可控的重试和清晰的错误边界。
- 问题:请求为什么会一直卡住
- 最小配方:每个外部请求都写 timeout
- 关键代码:连接超时和读取超时分开设
- 变体一:Session + Retry 统一处理重试
- 变体二:封装业务请求函数
- 常见坑和检查清单
- 完整片段
问题:请求为什么会一直卡住
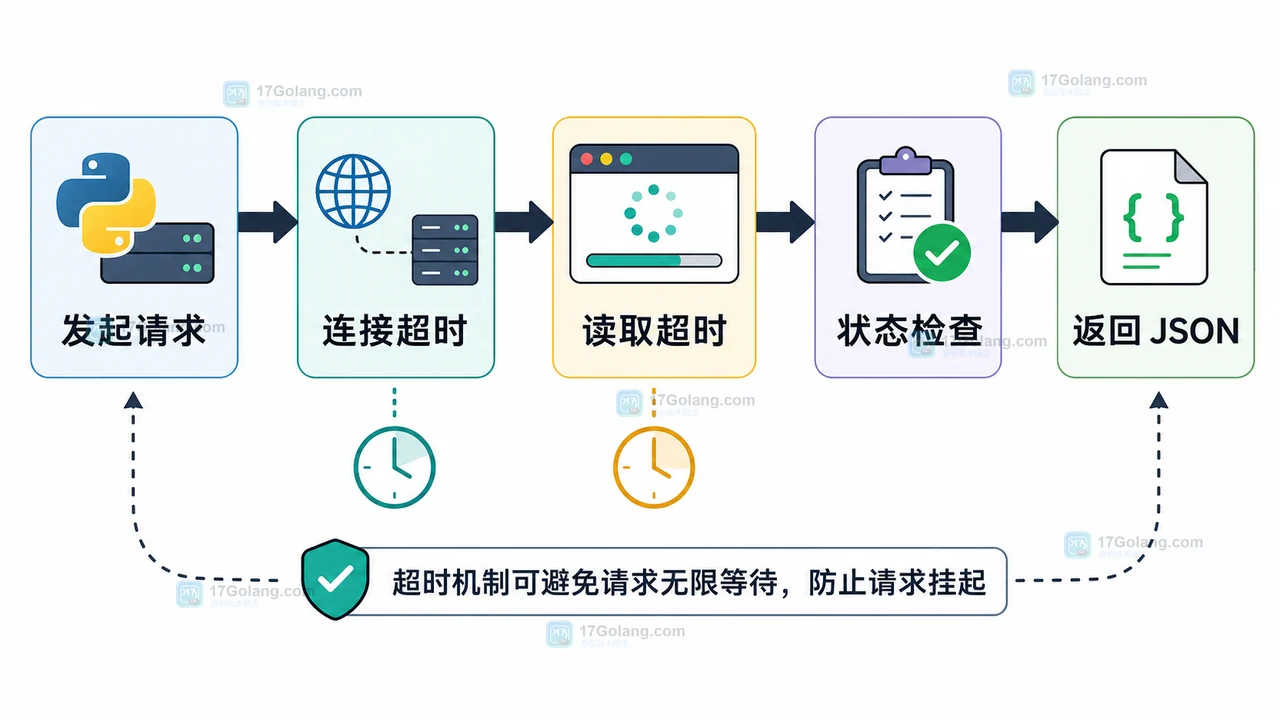
很多示例代码会写成 requests.get(url)。在本地测试时它看起来没有问题,因为目标接口通常很快返回;到了线上,DNS、网络连接、代理、对方服务排队、响应体过大,都可能让调用方等待很久。真正危险的点不是“请求失败”,而是“请求迟迟没有失败”。
建议把外部调用当成不可靠依赖来处理:每次请求必须有时间上限,失败要能分类,重试必须有次数和退避等待,业务层要拿到明确的错误。
最小配方:每个外部请求都写 timeout
最小可用写法是给 timeout 传一个二元组:第一个值控制建立连接的等待时间,第二个值控制读取响应的等待时间。这样既能快速发现网络不可达,也不会因为对方慢慢吐数据而无限等待。
import requests
resp = requests.get(
"https://api.example.com/orders",
params={"page": 1},
timeout=(3, 10),
)
resp.raise_for_status()
data = resp.json()
这里的 (3, 10) 不是固定标准,而是一个起点:连接 3 秒仍然无法建立,通常可以认为网络或目标地址有问题;连接成功后 10 秒还没有读完响应,就要看接口类型、响应体大小和业务容忍度。
关键代码:连接超时和读取超时分开设
timeout=10 也能用,但它把连接和读取混在一个数里,不利于定位问题。实际排查时,连接超时通常指向网络、域名、代理或端口;读取超时更常见于对方服务慢、SQL 慢、队列排队或返回体太大。
try:
resp = requests.get(
"https://api.example.com/profile",
timeout=(2, 8),
)
resp.raise_for_status()
except requests.ConnectTimeout as err:
raise RuntimeError("connect timeout") from err
except requests.ReadTimeout as err:
raise RuntimeError("read timeout") from err
如果你只想在业务层展示统一提示,可以捕获 requests.Timeout;如果你正在做线上问题定位,建议先把连接和读取分开记录到日志里。
变体一:Session + Retry 统一处理重试
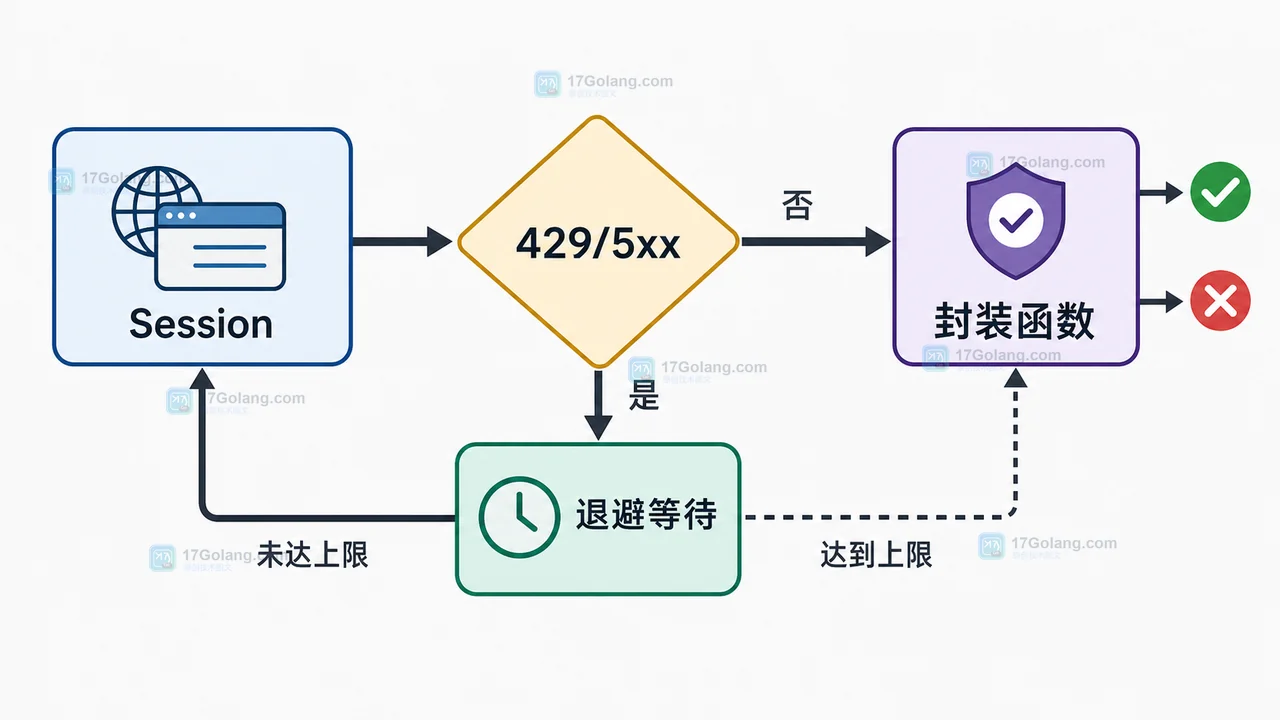
单次请求设置 timeout 只能避免一直等待,不能处理偶发的 429、502、503。这类状态码常见于限流、网关抖动或服务短暂不可用,可以给幂等请求增加少量重试。
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
import requests
retry = Retry(
total=3,
connect=3,
read=2,
backoff_factor=0.5,
status_forcelist=(429, 500, 502, 503, 504),
allowed_methods=("GET", "HEAD", "OPTIONS"),
)
session = requests.Session()
adapter = HTTPAdapter(max_retries=retry)
session.mount("http://", adapter)
session.mount("https://", adapter)
这段配置的重点有三个:只重试少数明确状态码;只默认重试幂等方法;用 backoff_factor 做退避等待,避免失败后立刻连续打满对方服务。
变体二:封装业务请求函数
如果项目里每个地方都直接调用 requests.get,超时、重试、日志、状态码检查很容易写散。更稳的做法是封装一个小函数,让业务层拿到结构化结果,或者拿到明确异常。
def fetch_json(url: str, *, params: dict | None = None) -> dict:
try:
resp = session.get(url, params=params, timeout=(3, 10))
resp.raise_for_status()
return resp.json()
except requests.Timeout as err:
raise RuntimeError("request timeout") from err
except requests.HTTPError as err:
status_code = err.response.status_code if err.response else "unknown"
raise RuntimeError(f"bad status: {status_code}") from err
except requests.RequestException as err:
raise RuntimeError("request failed") from err
封装后,调用方不需要关心底层库的各种异常类型。对外部接口较多的系统,还可以在这里统一加入请求 ID、耗时日志、响应体大小限制和错误上报。
常见坑和检查清单
坑 1:只写重试,不写 timeout
没有时间上限的请求会先卡住,重试逻辑根本没有机会触发。顺序应该是先限制每次请求的最长等待,再决定是否重试。
坑 2:对 POST 默认重试
创建订单、扣库存、扣款这类请求通常不是天然幂等。除非服务端有幂等键,否则不要随意重试会改变数据的请求。
坑 3:timeout 设得过长
把超时设成 60 秒看似“更稳”,实际上会拖住工作线程。接口面向用户时,通常应该更短;后台批处理可以稍长,但也要有总耗时预算。
坑 4:吞掉原始异常
业务层可以返回统一错误,但日志里要保留原始异常、URL 域名、状态码、耗时和重试次数。否则问题发生时很难判断是网络、网关还是对方服务慢。
完整片段
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
import requests
def build_session() -> requests.Session:
retry = Retry(
total=3,
connect=3,
read=2,
backoff_factor=0.5,
status_forcelist=(429, 500, 502, 503, 504),
allowed_methods=("GET", "HEAD", "OPTIONS"),
)
adapter = HTTPAdapter(max_retries=retry)
session = requests.Session()
session.mount("http://", adapter)
session.mount("https://", adapter)
return session
session = build_session()
def fetch_json(url: str, *, params: dict | None = None) -> dict:
try:
resp = session.get(url, params=params, timeout=(3, 10))
resp.raise_for_status()
return resp.json()
except requests.Timeout as err:
raise RuntimeError("request timeout") from err
except requests.HTTPError as err:
status_code = err.response.status_code if err.response else "unknown"
raise RuntimeError(f"bad status: {status_code}") from err
except requests.RequestException as err:
raise RuntimeError("request failed") from err
orders = fetch_json("https://api.example.com/orders", params={"page": 1})
总结一下:requests 的稳定用法不是多写几行配置,而是把外部依赖的边界讲清楚。每次请求设置连接和读取超时;对少量可重试状态做有限重试;在封装函数里统一状态检查和错误分类。这样接口慢的时候,系统会明确失败,而不是悄悄卡住。
-
101 收藏
-
101 收藏
-
102 收藏
-
102 收藏
-
104 收藏
-
196 收藏
-
文章 · python教程 | 1小时前 | logging · Python教程 · 后端开发 · 日志排查 · Python logging 日志重复 propagate addHandler basicConfig324 收藏
-
435 收藏
-
文章 · python教程 | 1星期前 | 异步编程 · 后端工程 · Python教程 · asyncio · 超时排查 · Python 超时控制 asyncio 任务取消 wait_for 异步清理320 收藏
-
321 收藏
-
365 收藏
-
文章 · python教程 | 1星期前 | 默认值 · python · 数据建模 · dataclass · default_factory · field · Python 数据类 Field 可变默认值 dataclass default_factory228 收藏
-
文章 · python教程 | 1星期前 | 重试机制 · timeout · requests · Python教程 · 接口调试 · Python Http请求 Requests timeout retry 接口排查330 收藏
-
299 收藏
-
308 收藏
-
209 收藏
-
329 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习