MySQL 覆盖索引实验:从慢查询到 EXPLAIN 显示 Using index
来源:17golang原创
时间:2026-06-27 19:03:06 276浏览 收藏
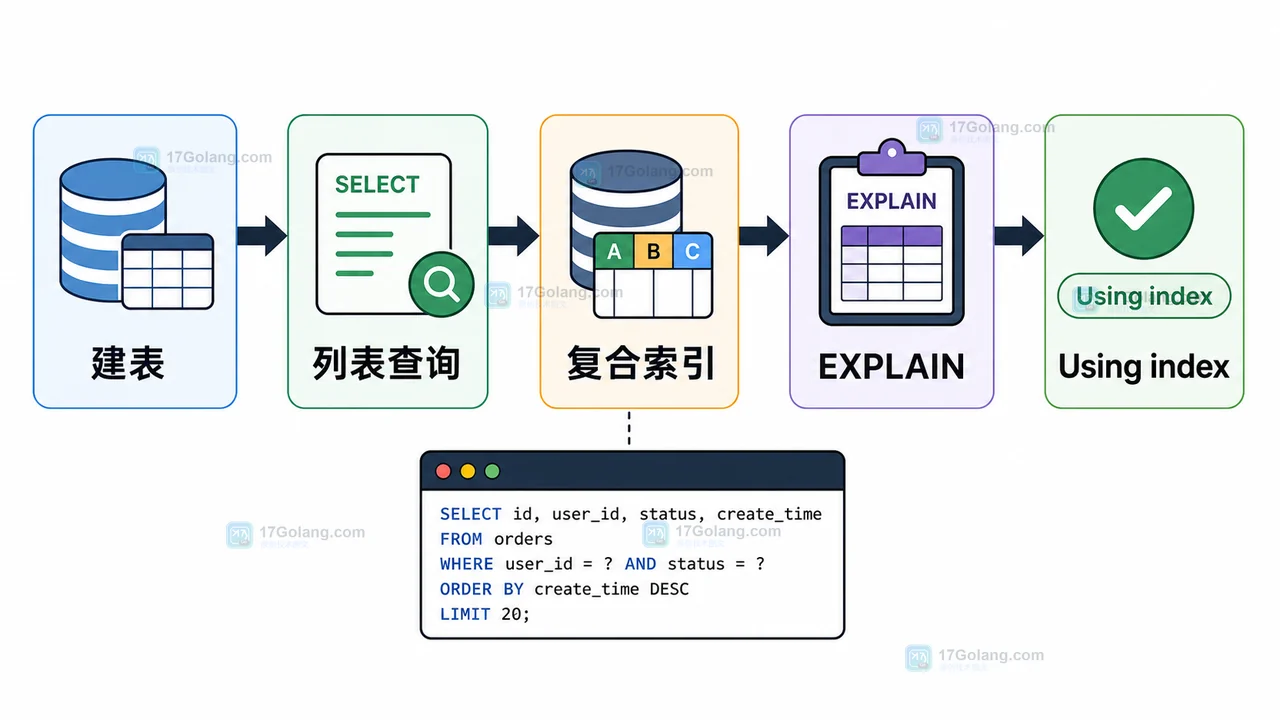
MySQL 查询慢时,很多人会先问“是不是该加索引”。但索引不是越多越好,真正要看查询条件、排序字段和返回列是否能被同一个索引覆盖。本文用一个小实验走完整流程:建表、插入测试数据、观察慢查询、添加复合索引、用 EXPLAIN 检查结果。
目标不是背概念,而是让读者亲手看到:当查询只需要索引里的列时,MySQL 可以少回表,Extra 里会出现 Using index,这就是覆盖索引发挥作用的典型信号。
- 前置条件:准备一个订单列表查询场景
- 初始化:建表并插入测试数据
- 编写查询:先故意保留回表路径
- 运行检查:添加复合索引并观察 Using index
- 扩展实验:返回更多列会发生什么
- 清理和总结:哪些查询适合覆盖索引
前置条件:准备一个订单列表查询场景
这个实验适合 MySQL 8.x,也适合大多数支持 EXPLAIN 的 MySQL 版本。你需要一个可测试的数据库账号,并能创建表、插入数据、添加索引。
我们模拟一个后台订单列表:按用户 ID 查询最近订单,只展示订单 ID、订单状态、创建时间和金额。这个场景很常见,也很适合演示覆盖索引。
初始化:建表并插入测试数据
先创建一张简化的订单表。为了让实验更清晰,表里保留了列表页常用字段,也保留了一个不会出现在列表页里的备注字段。
DROP TABLE IF EXISTS lab_orders; CREATE TABLE lab_orders ( id BIGINT PRIMARY KEY AUTO_INCREMENT, user_id BIGINT NOT NULL, status TINYINT NOT NULL, amount DECIMAL(10, 2) NOT NULL, created_at DATETIME NOT NULL, remark VARCHAR(255) NOT NULL DEFAULT '', KEY idx_user_created (user_id, created_at) ) ENGINE=InnoDB;
然后插入一些测试数据。实际环境可以用脚本批量插入;这里给出最小样例,方便你快速跑通。
INSERT INTO lab_orders (user_id, status, amount, created_at, remark) VALUES (1001, 1, 39.90, '2026-06-01 10:00:00', 'first order'), (1001, 2, 59.00, '2026-06-02 11:30:00', 'paid'), (1001, 3, 88.80, '2026-06-03 09:20:00', 'sent'), (1002, 1, 19.90, '2026-06-02 08:15:00', 'new'), (1003, 2, 129.00, '2026-06-04 18:10:00', 'vip');
编写查询:先故意保留回表路径
先看一个常见列表查询。它按 user_id 过滤,按 created_at 倒序排列,返回列表页需要的四个字段。
EXPLAIN SELECT id, status, amount, created_at FROM lab_orders WHERE user_id = 1001 ORDER BY created_at DESC LIMIT 10;
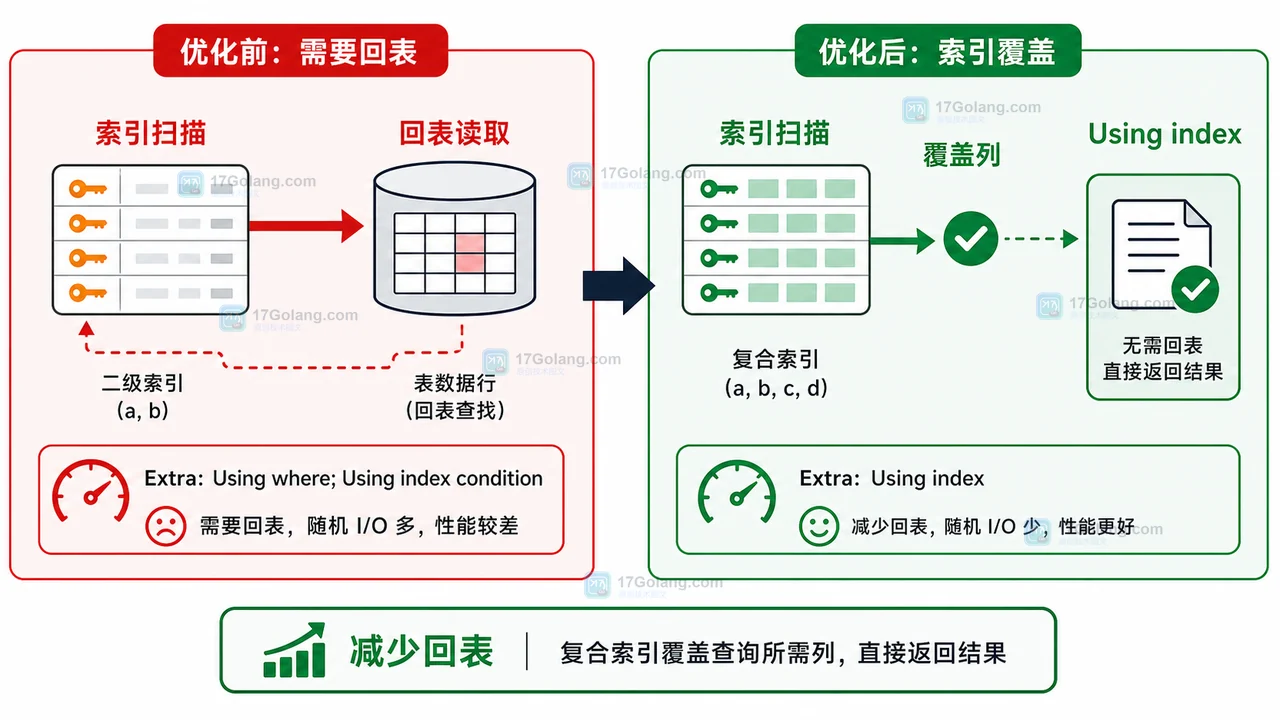
当前只有 (user_id, created_at) 索引。这个索引可以帮助定位用户和排序,但返回列里还有 status、amount,MySQL 仍可能需要回到聚簇索引读取完整行。此时 Extra 通常不会显示 Using index。
运行检查:添加复合索引并观察 Using index
现在添加一个覆盖列表查询的复合索引。索引顺序按“过滤字段、排序字段、返回字段”的思路组织。由于 InnoDB 二级索引会带上主键值,id 不一定需要显式放入索引;但为了让实验更直观,这里把列表返回列都写清楚。
ALTER TABLE lab_orders ADD KEY idx_user_created_list (user_id, created_at, status, amount); EXPLAIN SELECT status, amount, created_at FROM lab_orders WHERE user_id = 1001 ORDER BY created_at DESC LIMIT 10;
再次查看 EXPLAIN。如果 key 命中 idx_user_created_list,并且 Extra 中出现 Using index,说明这条查询读取的列已经由索引覆盖,减少了读取完整行的开销。
key: idx_user_created_list Extra: Using where; Using index
注意,上面的第二条查询没有返回 remark。这是实验的核心:只返回列表页真正需要的列,覆盖索引才更容易成立。
扩展实验:返回更多列会发生什么
现在把 remark 加回查询:
EXPLAIN SELECT status, amount, created_at, remark FROM lab_orders WHERE user_id = 1001 ORDER BY created_at DESC LIMIT 10;
如果 remark 不在索引里,MySQL 就需要回表读取完整行,Using index 通常会消失。这不是 MySQL 失效,而是查询需要的列已经超出了索引覆盖范围。
不要为了让所有查询都覆盖而把大字段放进索引。长字符串、文本字段、频繁更新字段放入复合索引,会增加索引体积和写入成本。列表页应该先收窄返回列,再判断是否需要覆盖索引。
清理和总结:哪些查询适合覆盖索引
实验结束后可以清理测试表:
DROP TABLE IF EXISTS lab_orders;
覆盖索引适合这类查询:
- 返回列少,通常是列表页、统计页、下拉选项。
- 查询条件和排序字段稳定,索引顺序容易确定。
- 读请求多,减少回表能带来实际收益。
- 返回字段不包含大文本、大 JSON 或频繁更新列。
最后记住一个判断方法:先用 EXPLAIN 看当前查询命中的索引,再根据业务返回列设计复合索引,最后确认 Extra 是否出现 Using index。覆盖索引不是固定写法,而是查询形状和索引列刚好匹配后的结果。
-
499 收藏
-
206 收藏
-
293 收藏
-
135 收藏
-
294 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习