Redis Key 生命周期治理趋势:从临时缓存到可观测资产
来源:17golang原创
时间:2026-06-29 10:44:56 400浏览 收藏
很多团队最早使用 Redis,是为了把数据库查询结果缓存起来:写一个 Key,设置一个过期时间,接口变快就算完成。但系统运行一段时间后,Redis 里会出现大量命名不统一、没有 TTL、容量异常、没人认领的 Key。它们不一定马上导致故障,却会持续增加排查和扩容成本。
这篇文章用中立趋势分析的方式,讨论 Redis Key 生命周期治理为什么越来越重要。重点不是追热点,而是把一个真实工程变化讲清楚:Redis Key 正在从“临时缓存项”变成“需要命名、归属、保留期和指标的可观测资产”。
- 趋势信号:Redis Key 不再只是临时缓存
- 解决的问题:散落 Key 会放大容量和排查成本
- 受益角色:开发、运维和业务都需要同一份事实
- 风险:治理过度也会影响交付效率
- 采用路径:先治理高风险 Key,再沉淀平台规则
- 观察指标:用数据判断治理是否有效
趋势信号:Redis Key 不再只是临时缓存
一个常见变化是,Redis 里承载的内容越来越多:登录态、接口缓存、限流计数、活动库存、榜单、消息去重、临时状态、异步任务进度。它已经不是单纯的“加速层”,而是很多业务链路里的状态中心。
当 Key 规模变大后,团队会逐渐遇到这些信号:
- 同一个业务对象有多种命名方式,排查时不知道该查哪一个前缀。
- 部分 Key 没有 TTL,长期留在 Redis 里,占用容量却没人确认是否还在使用。
- 大 Key 偶发拖慢接口,处理时又担心误删线上数据。
- 扩容前只能看总内存,无法回答“哪些业务在增长”。
- 故障复盘时发现 Key 没有归属人、没有保留期、没有清理记录。

这些信号说明 Redis 的治理对象已经不只是实例和内存,而是每一类 Key 的生命周期:谁写入、保存多久、如何观察、何时清理、清理后如何确认。
解决的问题:散落 Key 会放大容量和排查成本
Key 生命周期治理首先解决的是“不知道”的问题。比如业务反馈订单页偶发读到旧数据,开发可能先查接口逻辑,运维可能先看 Redis 内存,而真实原因可能是一个历史缓存前缀还在被旧代码读取。
没有统一规则时,问题会被放大:
| 问题类型 | 典型表现 | 治理目标 |
|---|---|---|
| 命名混乱 | user:1、u_1、cache:user:1 同时存在 |
按业务、对象、场景约定前缀 |
| 无 TTL | 临时缓存长期留存,容量持续增加 | 为缓存类 Key 设置明确保留期 |
| 大 Key | 单个 Key 读写变慢,迁移和清理风险高 | 拆分结构或限制单 Key 体积 |
| 归属不清 | 告警时没人确认是否能删 | 每个高风险前缀有负责人和说明 |
治理不是为了让 Redis 使用变复杂,而是为了让关键问题有证据。看到一个前缀增长时,能知道它属于哪个业务;看到一个大 Key 时,能知道是否允许拆分;看到无 TTL Key 时,能知道它是长期状态还是遗漏配置。
受益角色:开发、运维和业务都需要同一份事实
Key 生命周期治理的收益会落到不同角色上。
开发同学需要更少的排查时间。命名规则和 TTL 策略清楚后,新接口接入 Redis 时不用重复讨论 Key 应该怎么设计,也能避免上线后才发现缓存无法清理。
运维同学需要更可解释的容量变化。只看 used_memory 很难判断谁在增长;如果按前缀记录 Key 数、估算体积和 TTL 覆盖率,就能把扩容讨论从“实例快满了”推进到“某类业务 Key 最近增长了多少”。
业务和产品也会受益。活动、订单、积分、会员这类状态如果依赖 Redis,清理策略会影响页面结果和运营数据。治理后,业务能更清楚哪些状态是短期缓存,哪些状态应该回源数据库。
风险:治理过度也会影响交付效率
中立看待这个趋势,也要看到它的风险。Redis Key 治理如果一开始就做成复杂平台,可能带来额外阻力。
- 规则太重:小功能接入 Redis 前要填很多表,开发会绕开流程。
- 扫描太猛:无节制全库扫描可能影响线上实例,尤其是高峰期。
- 误删风险:只按名称或 TTL 判断,很容易删掉仍在使用的业务状态。
- 指标误读:Key 数下降不一定代表治理成功,也可能是业务流量下降。
比较稳的原则是:先治理高风险区域,再逐步扩展规则。不要一开始追求全量、全自动、全平台化,先把“能发现、能认领、能复查”做起来。
采用路径:先治理高风险 Key,再沉淀平台规则
一个可落地的采用路径可以分成五步。
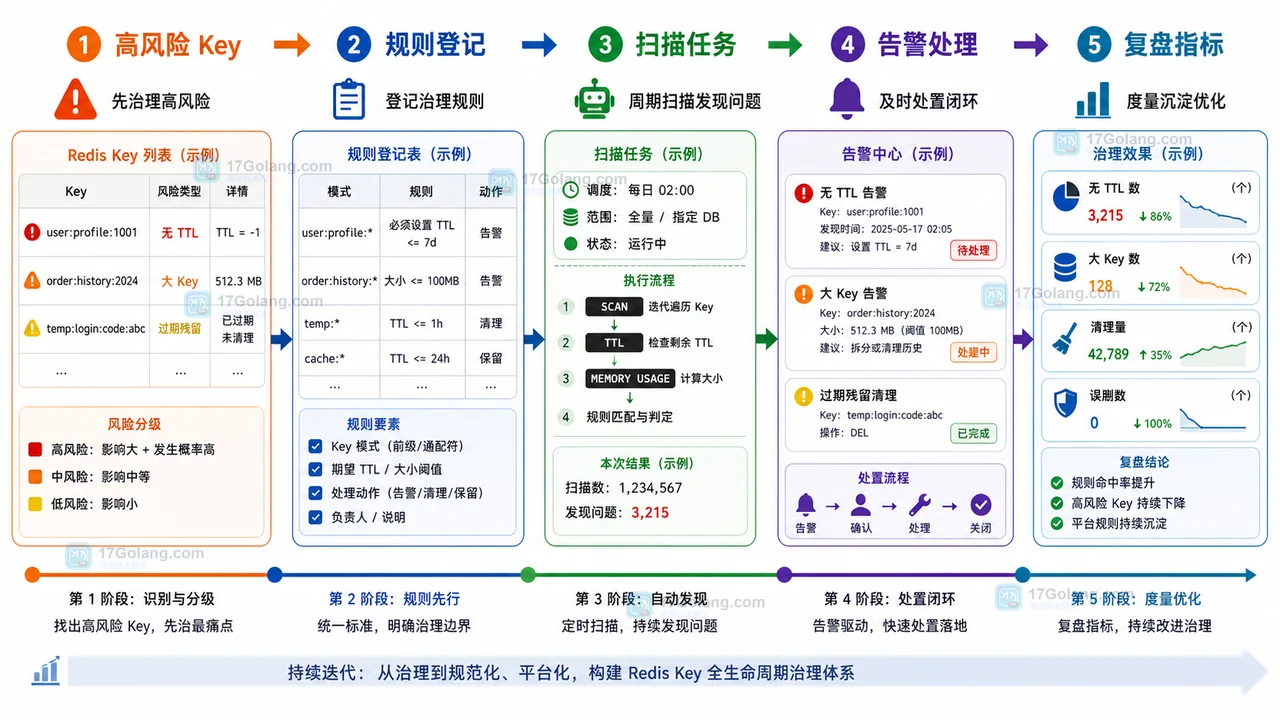
1. 先列出高风险 Key
优先看三类:无 TTL 的缓存类 Key、单 Key 体积异常的大 Key、增长速度明显高于业务流量的前缀。可以用只读方式做初筛:
redis-cli --scan --pattern 'order:*' | head -100 redis-cli TTL order:cache:1001 redis-cli MEMORY USAGE order:cache:1001 redis-cli INFO keyspace
这一步不急着清理,只记录现状:前缀、样例 Key、TTL、估算体积、负责人、是否能回源。
2. 建立前缀登记规则
登记表不需要很复杂,先包含这些字段即可:
- 前缀,例如
order:cache:*。 - 业务归属,例如订单中心。
- 数据来源,例如 MySQL 订单表或计算结果。
- 推荐 TTL,例如 10 分钟、1 小时或当天结束。
- 清理方式,例如可直接删、需灰度删、只能等自然过期。
3. 加入低频扫描任务
扫描任务要限速、分批、避开高峰。目标是生成观察报表,而不是在扫描阶段直接改数据。报表可以包含无 TTL 数、大 Key 数、前缀增长量和最近一次发现时间。
4. 告警后人工确认
当某个前缀突然增长,先通知负责人确认原因。只有满足“有归属、有回源、有备份或可重建”时,才进入清理动作。对大 Key 更要谨慎,优先拆分写入模型,而不是单次删除。
5. 复盘后固化规则
每次清理后记录结果:清理数量、释放内存、是否影响业务、是否出现误删。复盘通过后,再把该前缀加入固定规则,让后续新增 Key 自动继承命名和 TTL 要求。
观察指标:用数据判断治理是否有效
最后要看指标,而不是只看“有没有做治理”。建议至少跟踪这些数据:
- TTL 覆盖率:缓存类 Key 中有过期时间的比例。
- 无归属前缀数:扫描到但登记表没有记录的前缀数量。
- 大 Key 数量:超过团队阈值的 Key 数和所属业务。
- 清理释放量:按周或按月统计释放的内存。
- 误删次数:任何清理导致业务异常的事件都要单独记录。
- 告警确认时长:从发现异常到负责人确认的时间。
如果 TTL 覆盖率提高、无归属前缀减少、告警确认变快,同时误删次数没有上升,就说明治理方向是健康的。反过来,如果规则越来越多但开发仍然绕开,说明流程太重,需要缩小范围。
总结一下,Redis Key 生命周期治理不是把所有 Key 都管死,而是让重要 Key 有归属、有保留期、有观察指标、有清理闭环。它适合从高风险前缀开始,小步沉淀规则,再逐渐变成团队的缓存治理习惯。
-
374 收藏
-
398 收藏
-
117 收藏
-
426 收藏
-
171 收藏
-
数据库 · Redis | 18小时前 | Redis · 缓存 · go · Redis Cluster · 排错 · Redis Cluster CROSSSLOT Hash Tag MGET CLUSTER KEYSLOT259 收藏
-
183 收藏
-
413 收藏
-
数据库 · Redis | 2天前 | Redis · 安全配置 · 数据库运维 · ACL · 网络隔离 · Redis公网暴露 Redis protected-mode Redis ACL Redis安全配置 Redis审计364 收藏
-
250 收藏
-
110 收藏
-
366 收藏
-
449 收藏
-
441 收藏
-
119 收藏
-
280 收藏
-
数据库 · Redis | 2星期前 | Redis · 缓存治理 · Keyspace Notifications · 过期事件 · redis Pub/Sub Keyspace Notifications 过期事件 缓存监听 补偿任务181 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习