WebGPU 做浏览器端 AI 推理:能力边界、检测和降级方案
来源:17golang原创
时间:2026-06-29 16:54:34 234浏览 收藏
浏览器端 AI 推理越来越常见:图片分类、文本向量化、语音前处理、轻量模型试运行,都希望尽量减少服务端请求。WebGPU 给前端提供了访问 GPU 计算能力的标准接口,让一部分计算可以留在用户设备上完成。
但 WebGPU 不是“把任意大模型搬进浏览器”的开关。它更适合轻量模型、局部预处理、低延迟交互和隐私敏感的本地计算。本文按浏览器平台特性指南来讲:WebGPU 解决什么问题,当前支持边界怎么判断,最小示例怎么写,不支持时如何降级,以及性能和安全上要检查什么。
- 特性解决什么:把部分 AI 计算留在本地
- 支持范围:先做运行时检测,不写死浏览器名称
- 最小示例:从 adapter 到 device 的探测流程
- 兼容处理:WebGPU、Worker、服务端三层降级
- 性能注意:看端到端耗时,不只看单次推理
- 安全注意:模型、输入和设备能力都要设边界
特性解决什么:把部分 AI 计算留在本地
在传统架构里,用户上传输入,服务端完成模型推理,再把结果返回浏览器。这个流程适合重模型和统一部署,但也带来几个问题:网络往返增加延迟,服务端成本随调用量上涨,隐私数据要离开用户设备。
WebGPU 的价值是让浏览器可以更直接地使用 GPU 计算管线。对 AI 场景来说,它常见于三类任务:
- 轻量模型本地推理,例如小型分类器、向量编码器、图像处理模型。
- 模型前后处理,例如归一化、矩阵计算、批量 token 后处理。
- 交互式体验,例如实时预览、低延迟打分、离线可用的局部功能。
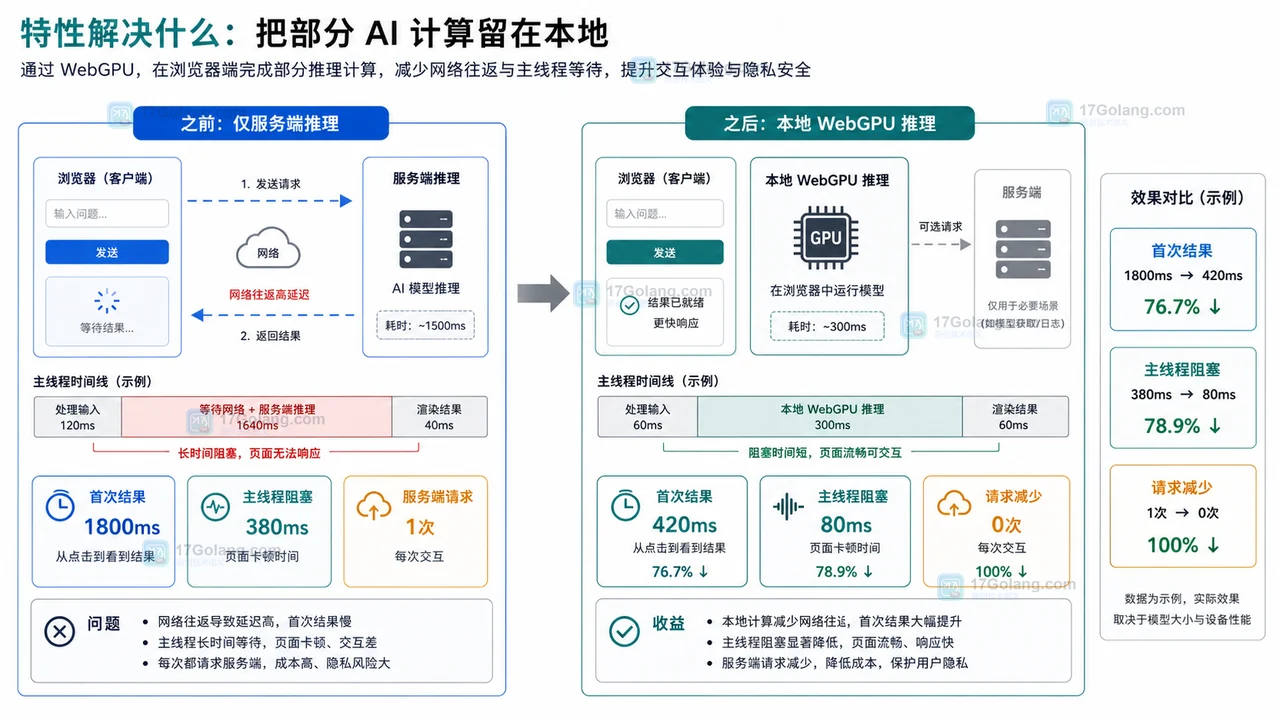
这里要强调边界:WebGPU 只解决“浏览器如何更高效地使用本机 GPU”这个问题。模型体积、内存占用、量化格式、加载时间、浏览器兼容性仍然要单独设计。页面变快与否,也要看端到端流程,而不是只看某一次矩阵计算。
支持范围:先做运行时检测,不写死浏览器名称
WebGPU 是较新的浏览器平台能力。不同浏览器、系统、硬件、驱动和安全上下文都会影响可用性。工程上不要只根据 UA 判断,而要在运行时检测。
async function detectWebGPU() {
if (!("gpu" in navigator)) {
return { ok: false, reason: "navigator.gpu 不存在" };
}
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) {
return { ok: false, reason: "没有可用 GPU adapter" };
}
const device = await adapter.requestDevice();
return {
ok: true,
adapter,
device,
};
}
这段检测比“Chrome 版本大于多少”更可靠。即使浏览器实现了 WebGPU,某些设备也可能因为驱动、权限、安全策略或硬件限制拿不到 adapter。运行时检测可以把失败原因交给降级逻辑处理。
最小示例:从 adapter 到 device 的探测流程
接入 WebGPU 的最小流程可以拆成三步:检测入口、申请 adapter、申请 device。真正跑模型前,还要额外加载模型文件和运行时库。本文先把平台能力探测写清楚。
async function prepareLocalAiRuntime() {
const state = await detectWebGPU();
if (!state.ok) {
return {
mode: "server",
reason: state.reason,
};
}
return {
mode: "webgpu",
device: state.device,
};
}
prepareLocalAiRuntime().then((runtime) => {
if (runtime.mode === "webgpu") {
console.log("使用 WebGPU 路径");
} else {
console.log("降级到服务端路径:", runtime.reason);
}
});
这个示例不直接绑定具体模型框架,是为了突出一个工程原则:先判断平台能力,再决定模型运行路径。否则页面可能在模型加载到一半时才失败,用户体验更差,错误也更难定位。
兼容处理:WebGPU、Worker、服务端三层降级
浏览器端 AI 功能应该默认带降级路线。推荐的顺序是:
- WebGPU 可用:使用本地 GPU 路径,适合低延迟和隐私敏感输入。
- WebGPU 不可用但设备还能承受:放到 Web Worker,避免阻塞主线程。
- 本地能力不足:调用服务端接口,由后端统一推理。
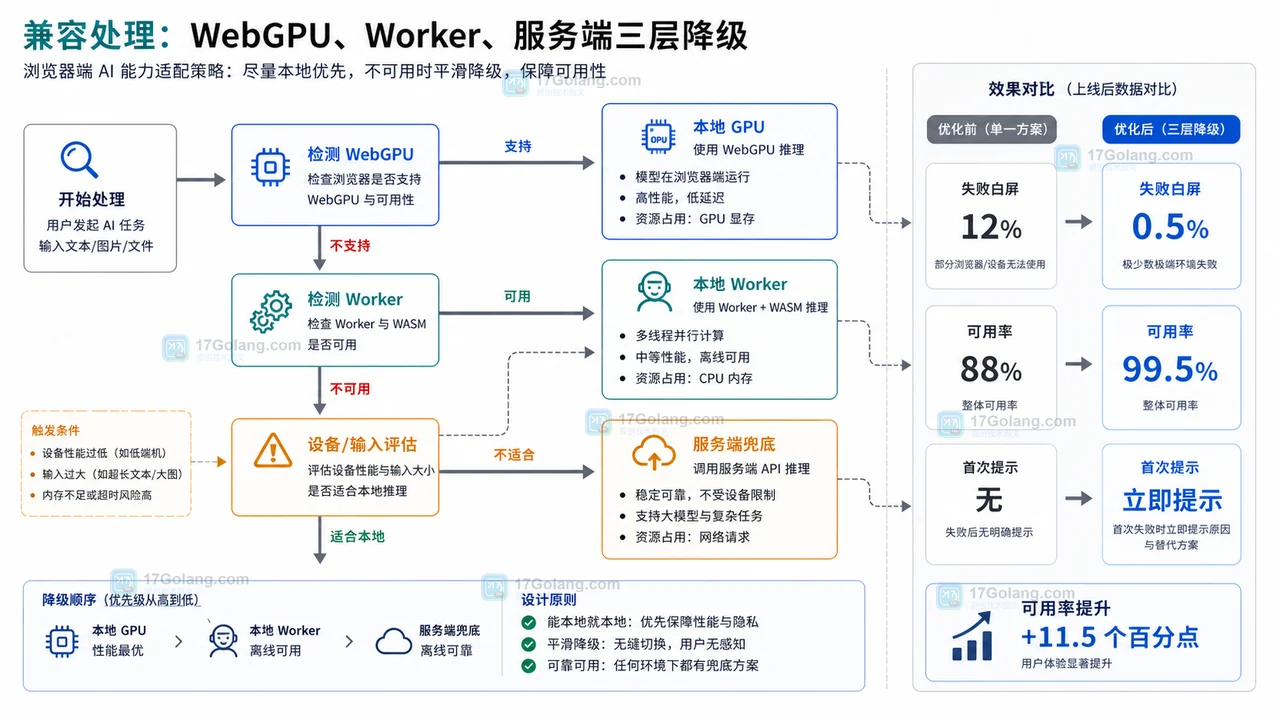
降级逻辑可以写成清晰的策略函数:
async function chooseAiPath(inputSize) {
const state = await detectWebGPU();
if (state.ok && inputSize
阈值不是固定答案,应该根据模型体积、设备性能和业务容忍度调整。关键是把选择条件写出来,并记录日志,方便后续观察多少用户走了本地路径,多少用户进入了服务端路径。
性能注意:看端到端耗时,不只看单次推理
WebGPU 路径可能让推理阶段更快,但完整体验还包括模型下载、初始化、输入预处理、结果后处理和 UI 更新。只测单次推理,很容易得出过度乐观的结论。
建议至少记录这些指标:
model_load_ms:模型文件下载和解析耗时。runtime_init_ms:adapter、device、运行时初始化耗时。first_result_ms:用户点击到看到第一条结果的耗时。main_thread_block_ms:主线程长任务时间。fallback_rate:降级到 Worker 或服务端的比例。
如果 WebGPU 推理很快,但模型首次加载要十几秒,用户仍然会觉得慢。可以通过懒加载、缓存模型、分阶段加载和提前探测来改善体验。
安全注意:模型、输入和设备能力都要设边界
浏览器端 AI 不能只看性能,还要考虑安全和资源边界。
- 模型文件要控制来源和版本,避免加载未知地址的模型资产。
- 输入大小要限制,避免用户一次提交过大的图片、音频或文本。
- 本地推理结果不能作为唯一可信结果,关键业务仍应服务端复核。
- 设备能力不足时要明确提示,不要让页面长时间无响应。
- 敏感数据尽量留在本地,但也要告诉用户哪些数据会被上传。
上线前可以用一张检查表收口:支持检测是否完整,降级路径是否可用,模型加载失败是否可恢复,主线程是否有长任务,服务端兜底是否限流。只有这些条件都过了,WebGPU 才是一个工程能力,而不是一个演示效果。
总结
WebGPU 让浏览器端 AI 推理有了更强的本地计算基础,但它不是万能加速按钮。正确的落地方式是:先用运行时检测确认支持情况,再把 WebGPU、Worker 和服务端推理做成可切换路径;性能上看端到端指标,安全上控制模型来源、输入大小和业务可信边界。这样才能让本地 AI 能力稳定进入真实页面。
-
284 收藏
-
387 收藏
-
328 收藏
-
426 收藏
-
147 收藏
-
243 收藏
-
195 收藏
-
186 收藏
-
333 收藏
-
419 收藏
-
280 收藏
-
科技周边 · 人工智能 | 3天前 | 异步任务 · 人工智能 · jsonl · AI工程化 · Batch API · 结果对账 · JSONL 大模型批量任务 OpenAI Batch API custom_id AI 离线处理 结果对账113 收藏
-
149 收藏
-
432 收藏
-
科技周边 · 人工智能 | 4天前 | 安全 · oauth · 人工智能 · mcp · 工具调用 · MCP 401 MCP 403 MCP OAuth mcp resource_metadata MCP scope MCP token audience443 收藏
-
科技周边 · 人工智能 | 5天前 | 前端 · 人工智能 · 用户体验 · 可访问性 · 流式输出 · AI对话 AbortController AbortSignal 流式输出 aria-live 停止生成425 收藏
-
468 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习