开源的Yi-VL多模态大模型在MMMU和CMMMU两大权威榜单中取得领先地位
来源:机器之心
时间:2024-01-24 19:29:38 123浏览 收藏
学习知识要善于思考,思考,再思考!今天golang学习网小编就给大家带来《开源的Yi-VL多模态大模型在MMMU和CMMMU两大权威榜单中取得领先地位》,以下内容主要包含等知识点,如果你正在学习或准备学习科技周边,就都不要错过本文啦~让我们一起来看看吧,能帮助到你就更好了!
https://huggingface.co/01-ai https://www.modelscope.cn/organization/01ai



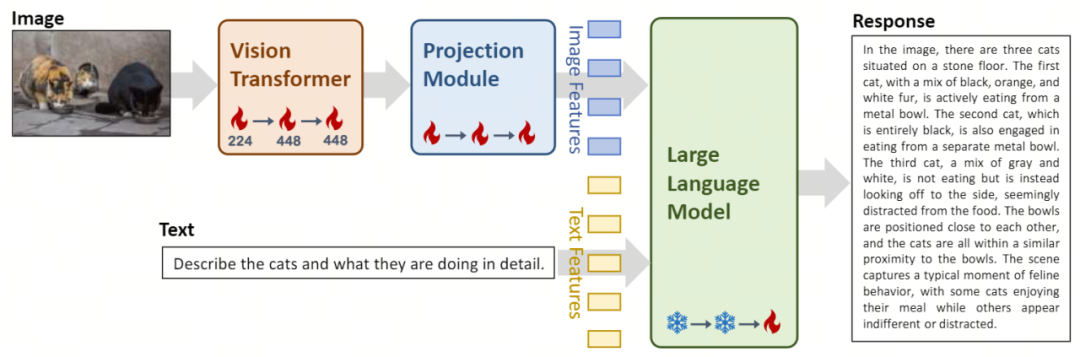
Vision Transformer(简称 ViT)用于图像编码,使用开源的 OpenClip ViT-H/14 模型初始化可训练参数,通过学习从大规模「图像 - 文本」对中提取特征,使模型具备处理和理解图像的能力。 Projection 模块为模型带来了图像特征与文本特征空间对齐的能力。该模块由一个包含层归一化(layer normalizations)的多层感知机(Multilayer Perceptron,简称 MLP)构成。这一设计使得模型可以更有效地融合和处理视觉和文本信息,提高了多模态理解和生成的准确度。 Yi-34B-Chat 和 Yi-6B-Chat 大规模语言模型的引入为 Yi-VL 提供了强大的语言理解和生成能力。该部分模型借助先进的自然语言处理技术,能够帮助 Yi-VL 深入理解复杂的语言结构,并生成连贯、相关的文本输出。
第一阶段:零一万物使用 1 亿张的「图像 - 文本」配对数据集训练 ViT 和 Projection 模块。在这一阶段,图像分辨率被设定为 224x224,以增强 ViT 在特定架构中的知识获取能力,同时实现与大型语言模型的高效对齐。 第二阶段:零一万物将 ViT 的图像分辨率提升至 448x448,这一提升让模型更加擅长识别复杂的视觉细节。此阶段使用了约 2500 万「图像 - 文本」对。 第三阶段:零一万物开放整个模型的参数进行训练,目标是提高模型在多模态聊天互动中的表现。训练数据涵盖了多样化的数据源,共约 100 万「图像 - 文本」对,确保了数据的广泛性和平衡性。
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于科技周边的相关知识,也可关注golang学习网公众号。
声明:本文转载于:机器之心 如有侵犯,请联系study_golang@163.com删除

相关阅读
更多>
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
最新阅读
更多>
-
445 收藏
-
301 收藏
-
297 收藏
-
331 收藏
-
226 收藏
-
293 收藏
-
412 收藏
-
411 收藏
-
371 收藏
-
168 收藏
-
368 收藏
-
447 收藏
课程推荐
更多>
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习