常见的距离度量用于K最近邻算法中的机器学习算法
来源:网易伏羲
时间:2024-01-30 15:05:12 427浏览 收藏
本篇文章给大家分享《常见的距离度量用于K最近邻算法中的机器学习算法》,覆盖了科技周边的常见基础知识,其实一个语言的全部知识点一篇文章是不可能说完的,但希望通过这些问题,让读者对自己的掌握程度有一定的认识(B 数),从而弥补自己的不足,更好的掌握它。
k最近邻算法是一种用于分类和识别的基于实例或基于内存的机器学习算法。它的原理是通过找到给定查询点的最近邻数据来进行分类。由于该算法严重依赖已存储的训练数据,它可以被看作是一个非参数化的学习方法。
k最近邻算法适用于处理分类或回归问题。对于分类问题,它使用离散值进行处理,而对于回归问题,它使用连续值进行处理。在进行分类之前,必须定义距离,常见的距离度量方法有多种选择。
欧几里得距离
这是常用的距离度量,适用于实值向量。公式测量查询点与另一点之间的直线距离。
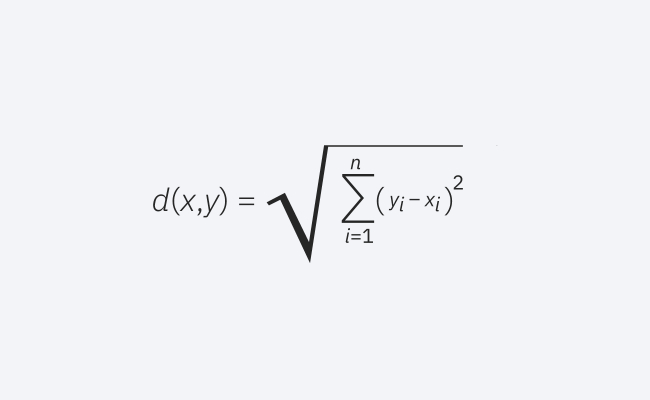
欧几里得距离公式
曼哈顿距离
这也是一种流行的距离度量,它测量两点之间的绝对值。

曼哈顿距离公式
闵可夫斯基距离
此距离度量是欧几里德和曼哈顿距离度量的广义形式。

闵可夫斯基距离公式
汉明距离
该技术通常与布尔或字符串向量一起使用,识别向量不匹配的点。因此,它也被称为重叠度量。

汉明距离公式
确定k最近邻算法距离的意义
为了确定哪些数据点最接近给定查询点,需要计算查询点与其他数据点之间的距离。这些距离度量有助于形成决策边界,将查询点划分为不同的区域。
本篇关于《常见的距离度量用于K最近邻算法中的机器学习算法》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于科技周边的相关知识,请关注golang学习网公众号!
声明:本文转载于:网易伏羲 如有侵犯,请联系study_golang@163.com删除

相关阅读
更多>
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
最新阅读
更多>
-
331 收藏
-
238 收藏
-
263 收藏
-
174 收藏
-
166 收藏
-
333 收藏
-
146 收藏
-
329 收藏
-
177 收藏
-
192 收藏
-
191 收藏
-
292 收藏
课程推荐
更多>
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习