收录了网络爬虫频道下的 14 篇文章
-

- Go语言网络爬虫中的基本数据结构
- 为了承载和封装数据,需要先声明一些基本的数据结构。网络爬虫框架中的各个模块都会用到这些数据结构,所以可以说它们是这一程序的基础。在分析网络爬虫框架的需求时,提到过这样几类
- Golang· Go教程 | 3年前 | 网络爬虫· golang 486浏览 收藏
-

- Go语言网络爬虫条目处理管道
- 条目处理管道的接口拥有额外的 ItemProcessors、Send、FailFast 和 SetFailFast 方法,因此其实现类型 myPipeline 的基本结构是这样的://条目处理管道的实现类型type myPipeline struct { //组件基础实例 stub
- Golang· Go教程 | 3年前 | 网络爬虫· golang 440浏览 收藏
-

- Go语言网络爬虫内部基础接口
- 首先要做的是,先为组件通用功能定义一个内部接口,这里把它叫做组件的内部基础接口。内部基础接口及其实现类型存放在了代码包 gopcp.v2/chapter6/webcrawler/module/stub 中,代码包可以在我的网盘
- Golang· Go教程 | 3年前 | 网络爬虫· golang 395浏览 收藏
-

- Go语言网络爬虫下载器接口
- 与 ModuleInternal 接口一样,下载器接口 Downloader 也内嵌了 Module 接口,它额外声明了一个 Download 方法。有了 ModuleInternal 接口及其实现类型,实现下载器时只需关注它的特色功能,其他的都交给内
- Golang· Go教程 | 3年前 | 网络爬虫· golang 386浏览 收藏
-

- Go语言网络爬虫分析器接口
- 分析器的接口包含两个额外的方法 RespParsers 和 Analyze,其中前者会返回当前分析器使用的 HTTP 响应解析函数(以下简称解析函数)的列表因此,分析器的实现类型有用于存储此列表的字段。另外
- Golang· Go教程 | 3年前 | 网络爬虫· golang 372浏览 收藏
-

- Go语言爬取图片小程序
- 在本节中,我们的主要任务是使用网络爬虫框架编写一个可以下载目标网站中链接图片的爬虫程序。在这个过程中,我们会发现网络爬虫框架的一些不足,并继续为之添砖加瓦。这是一种反哺。
- Golang· Go教程 | 3年前 | 网络爬虫· golang 296浏览 收藏
-

- Go语言网络爬虫缓冲池工具的实现
- 缓冲池的基本结构如下://数据缓冲池接口的实现类型type myPool struct { //缓冲器的统一容量 bufferCap uint32 //缓冲器的最大数量 maxBufferNumber uint32 //缓冲器的实际数量 bufferNumber uint32 /
- Golang· Go教程 | 3年前 | 网络爬虫· golang 271浏览 收藏
-

- Go语言网络爬虫缓冲器工具的实现
- 缓冲器的基本结构如下://集冲器接口的实现类型type myBuffer struet { //存放数据的通道 ch chan interface{} //缓冲器的关闭状态:0-未关闭;2-已关闭 closed uint32 //为了消除因关闭缓冲器而产
- Golang· Go教程 | 3年前 | 网络爬虫· golang 176浏览 收藏
-

- Go语言网络爬虫多重读取器的实现
- 相比前面两节中介绍的缓冲器和缓冲池,多重读取器的实现就简单多了。首先是基本结构://多重读取器的实现类型type myMultipleReader struct { data []byte}非常简单和直接,多重读取器只保存要读取
- Golang· Go教程 | 3年前 | 网络爬虫· golang 156浏览 收藏
-

- Go语言网络爬虫组件注册器
- 在讲解下载器接口设计时,我们介绍过组件注册方面的设计和组件注册器接口 Registrar,它声明在 module 包中。根据前面的接口描述,我们会让组件注册器按照类型存储已注册的组件。该接口的声
- Golang· Go教程 | 3年前 | 网络爬虫· golang 154浏览 收藏
-
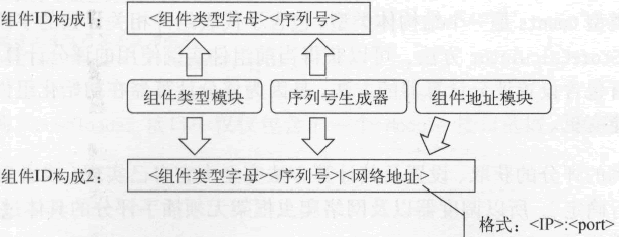
- Go语言网络爬虫的接口设计
- 这里所说的接口是指网络爬虫框架中各个模块的接口。与先前描述的基本数据结构不同,它们的主要职责是定义模块的行为。在定义行为的过程中,我会对它们应有的功能作进一步的审视,同时
- Golang· Go教程 | 3年前 | 网络爬虫· golang 149浏览 收藏


查看更多
课程推荐
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让学生了解MySQL如何与客户端进行通信。此外,课程还将介绍如何优化MySQL的网络通信性能,包括连接池、网络压缩、SSL加密等高级技术。学生将通过实践项目,亲手
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- Golang深入理解GPM模型
- Golang深入理解GPM调度器模型及全场景分析,希望您看完这套视频有所收获;包括调度器的由来和分析、GMP模型简介、以及11个场景总结。
- 474次学习


