Mysql数据库分库分表全面瓦解
来源:脚本之家
时间:2023-01-01 14:27:41 219浏览 收藏
怎么入门数据库编程?需要学习哪些知识点?这是新手们刚接触编程时常见的问题;下面golang学习网就来给大家整理分享一些知识点,希望能够给初学者一些帮助。本篇文章就来介绍《Mysql数据库分库分表全面瓦解》,涉及到MySQL数据库、分库分表,有需要的可以收藏一下
1 为什么要分库分表
物理服务机的CPU、内存、存储设备、连接数等资源有限,某个时段大量连接同时执行操作,会导致数据库在处理上遇到性能瓶颈。为了解决这个问题,行业先驱门充分发扬了分而治之的思想,对大库表进行分割,然后实施更好的控制和管理,同时使用多台机器的CPU、内存、存储,提供更好的性能。而分治有两种实现方式:垂直拆分和水平拆分。
2 垂直拆分(Scale Up 纵向扩展)
垂直拆分分为垂直分库和垂直分表,主要按功能模块拆分,以解决各个库或者各个表之间的资源竞争。比如分为订单库、商品库、用户库...这种方式,多个数据库之间的表结构是不同的。
2.1 垂直分库
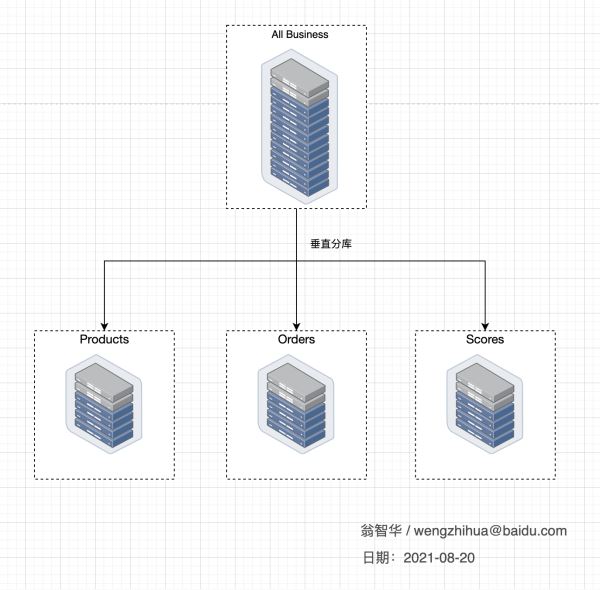
先说说垂直分库。垂直分库其实是一种简单逻辑分割。比如我们的数据库中有商品表Products、还有对订单表Orders,还有积分表Scores。接下来我们就可以创建三个数据库,一个数据库存放商品,一个数据库存放订单,一个数据库存放积分。
垂直分库有一个优点,他能够根据业务场景进行孵化,比如某一单一场景只用到某2-3张表,基本上应用和数据库可以拆分出来做成相应的服务。拆分方式如下图所示:
2.2 垂直分表
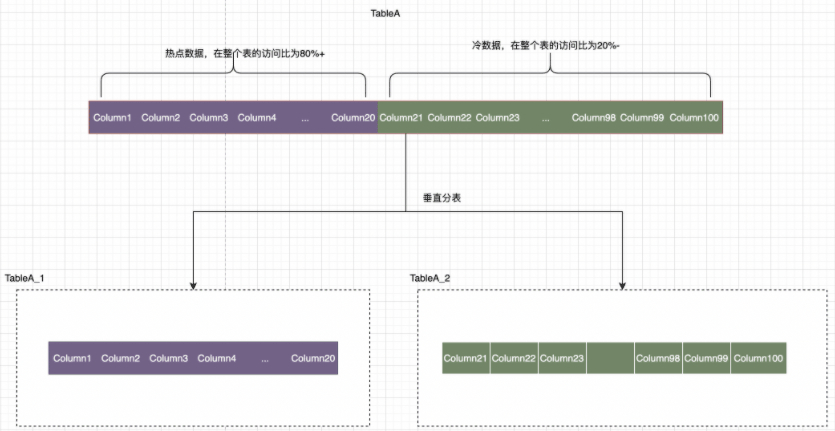
再来说说垂直分表,比较适用于那种字段比较多的表,假设我们一张表有100个字段,我们分析了一下当前业务执行的SQL语句,有20个字段是经常使用的,而另外80个字段使用比较少。
这样我们就可以把20个字段放在主表里面,我们再创建一个辅助表,存放另外80个字段。当然主表和辅助表都是有主键的,他们通过主键进行关联合并,就可以组合成100个字段的表。拆分方式如下图所示。
除了这种访问频率的冷热拆分之外,还可以按照字段类型结构来拆分,比如大文本字段单独放在一个表中,与基础字段隔离,提高基础字段的访问效率。
也可以将字段按照功能用途来拆分,比如采购的物料表可以按照基本属性、销售属性、采购属性、生产制造属性、财务会计属性等用途垂直拆分。
总体来说:垂直拆分有以下优点:
- 跟随业务进行分割,类似微服务的分治理念,方便解耦之后的管理及扩展。
- 高并发的场景下,垂直拆分使用多台服务器的CPU、I/O、内存能提升性能,同时对单机数据库连接数、一些资源限制也得到了提升,能实现冷热数据的分离。
垂直拆分的缺点:
- 部分业务表无法join,应用层需要很大的改造,只能通过聚合的方式来实现。增加了开发的难度。
- 单表数据量膨胀的问题依然没有得到有效的解决。分布式事务也是一个难题。
3 水平拆分(Scale Out 横向扩展)
水平拆分又分为库内分表和分库分表,来解决单表中数据量增长出现的压力,这些数据库中的表结构完全相同。
3.1 库内分表
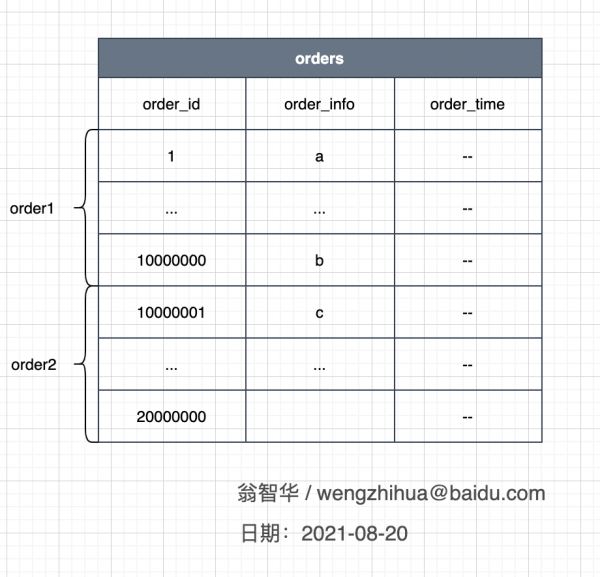
先说说库内分表。假设当我们的Orders表达到了5000万行记录的时候,非常影响数据库的读写效率,怎么办呢?
我们可以考虑按照订单编号的order_id进行rang分区,就是把订单编号在1-1000万的放在order1表中,将编号在1000万-2000万的放在order2中,以此类推,每个表中存放1000万数据。
关于水平分表的时机,业内的标准不是很统一,阿里的Java 开发手册的标准是当单表行数超过 500万行或者单表容量超过 2 GB时,才推荐进行分库分表。百度的则是1000 W行的进行分表,这个是百度的DBA经过测试推算出的结果。
但是这边忽略了单表的字段数和字段类型,如果字段数很多,超过50列,对性能影响也是不小的,我们曾经有个业务,表字段是随着业务的增长而自动扩增的,到了后期,字段越来越多,查询性能也越来越慢。
所以个人觉得不必拘泥于500W 还是1000W,开发人员在使用过程中,如果压测发现因为数据基数变大而导致执行效率慢下来,就可以开始考虑分表了。
3.2 库内分表的实现策略
目前在MySql中支持四种表分区的方式,分别为HASH、RANGE、LIST及KEY,当然在其它的类型数据库中,分区的实现方式略有不同,但是分区的思想原理是相同,具体如下:
3.2.1 HASH(哈希)
HASH分区主要用来确保数据在预先确定数目的分区中平均分布,而在RANGE和LIST分区中,必须明确指定一个给定的列值或列值集合应该保存在哪个分区中,而在HASH分区中,MySQL自动完成这些工作,
你所要做的只是基于将要被哈希的列值指定一个列值或表达式,以及指定被分区的表将要被分割成的分区数量。 示例如下:
1 drop table if EXISTS `t_userinfo`; 2 CREATE TABLE `t_userinfo` ( 3 `id` int(10) unsigned NOT NULL, 4 `personcode` varchar(20) DEFAULT NULL, 5 `personname` varchar(100) DEFAULT NULL, 6 `depcode` varchar(100) DEFAULT NULL, 7 `depname` varchar(500) DEFAULT NULL, 8 `gwcode` int(11) DEFAULT NULL, 9 `gwname` varchar(200) DEFAULT NULL, 10 `gravalue` varchar(20) DEFAULT NULL, 11 `createtime` DateTime NOT NULL 12 ) ENGINE=InnoDB DEFAULT CHARSET=utf8 13 PARTITION BY HASH(YEAR(createtime)) 14 PARTITIONS 10;
上面的例子,使用HASH函数对createtime日期进行HASH运算,并根据这个日期来分区数据,这里共分为10个分区。
建表语句上添加一个“PARTITION BY HASH (expr)”子句,其中“expr”是一个返回整数的表达式,它可以是字段类型为MySQL 整型的一列的名字,也可以是返回非负数的表达式。
另外,可能需要在后面再添加一个“PARTITIONS num”子句,其中num 是一个非负的整数,它表示表将要被分割成分区的数量。
3.2.2 RANGE(范围)
基于属于一个给定连续区间的列值,把多行分配给同一个分区,这些区间要连续且不能相互重叠,使用VALUES LESS THAN操作符来进行定义。示例如下:
1 drop table if EXISTS `t_userinfo`; 2 CREATE TABLE `t_userinfo` ( 3 `id` int(10) unsigned NOT NULL, 4 `personcode` varchar(20) DEFAULT NULL, 5 `personname` varchar(100) DEFAULT NULL, 6 `depcode` varchar(100) DEFAULT NULL, 7 `depname` varchar(500) DEFAULT NULL, 8 `gwcode` int(11) DEFAULT NULL, 9 `gwname` varchar(200) DEFAULT NULL, 10 `gravalue` varchar(20) DEFAULT NULL, 11 `createtime` DateTime NOT NULL 12 ) ENGINE=InnoDB DEFAULT CHARSET=utf8 13 PARTITION BY RANGE(gwcode) ( 14 PARTITION P0 VALUES LESS THAN(101) , 15 PARTITION P1 VALUES LESS THAN(201) , 16 PARTITION P2 VALUES LESS THAN(301) , 17 PARTITION P3 VALUES LESS THAN MAXVALUE 18 );
上面的示例,使用了范围RANGE函数对岗位编号进行分区,共分为4个分区,
岗位编号为1~100 的对应在分区P0中,101~200的编号在分区P1中,依次类推即可。那么类别编号大于300,可以使用MAXVALUE来将大于300的数据统一存放在分区P3中即可。
3.2.3 LIST(预定义列表)
类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择分区的。LIST分区通过使用“PARTITION BY LIST(expr)”来实现,其中“expr” 是某列值或一个基于某个列值、并返回一个整数值的表达式,
然后通过“VALUES IN (value_list)”的方式来定义每个分区,其中“value_list”是一个通过逗号分隔的整数列表。 示例如下:
1 drop table if EXISTS `t_userinfo`; 2 CREATE TABLE `t_userinfo` ( 3 `id` int(10) unsigned NOT NULL, 4 `personcode` varchar(20) DEFAULT NULL, 5 `personname` varchar(100) DEFAULT NULL, 6 `depcode` varchar(100) DEFAULT NULL, 7 `depname` varchar(500) DEFAULT NULL, 8 `gwcode` int(11) DEFAULT NULL, 9 `gwname` varchar(200) DEFAULT NULL, 10 `gravalue` varchar(20) DEFAULT NULL, 11 `createtime` DateTime NOT NULL 12 ) ENGINE=InnoDB DEFAULT CHARSET=utf8 13 PARTITION BY LIST(`gwcode`) ( 14 PARTITION P0 VALUES IN (46,77,89) , 15 PARTITION P1 VALUES IN (106,125,177) , 16 PARTITION P2 VALUES IN (205,219,289) , 17 PARTITION P3 VALUES IN (302,317,458,509,610) 18 );
上面的例子,使用了列表匹配LIST函数对员工岗位编号进行分区,共分为4个分区,编号为46,77,89的对应在分区P0中,106,125,177类别在分区P1中,依次类推即可。
不同于RANGE的是,LIST分区的数据必须匹配列表中的岗位编号才能进行分区,所以这种方式只是适合比较区间值确定并少量的情况。
3.2.4 KEY(键值)
类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。 示例如下:
1 drop table if EXISTS `t_userinfo`; 2 CREATE TABLE `t_userinfo` ( 3 `id` int(10) unsigned NOT NULL, 4 `personcode` varchar(20) DEFAULT NULL, 5 `personname` varchar(100) DEFAULT NULL, 6 `depcode` varchar(100) DEFAULT NULL, 7 `depname` varchar(500) DEFAULT NULL, 8 `gwcode` int(11) DEFAULT NULL, 9 `gwname` varchar(200) DEFAULT NULL, 10 `gravalue` varchar(20) DEFAULT NULL, 11 `createtime` DateTime NOT NULL 12 ) ENGINE=InnoDB DEFAULT CHARSET=utf8 13 PARTITION BY KEY(gwcode) 14 PARTITIONS 10;
注意:此种分区算法目前使用的比较少,使用服务器提供的哈希函数有不确定性,对于后期数据统计、整理存在会更复杂,所以我们更倾向于使用由我们定义表达式的Hash,大家知道其存在和怎么使用即可。
3.2.5 Composite(复合模式)
Composite是上面几种模式的组合使用,比如你在Range的基础上,再进行Hash 哈希分区。
3.3 分库分表
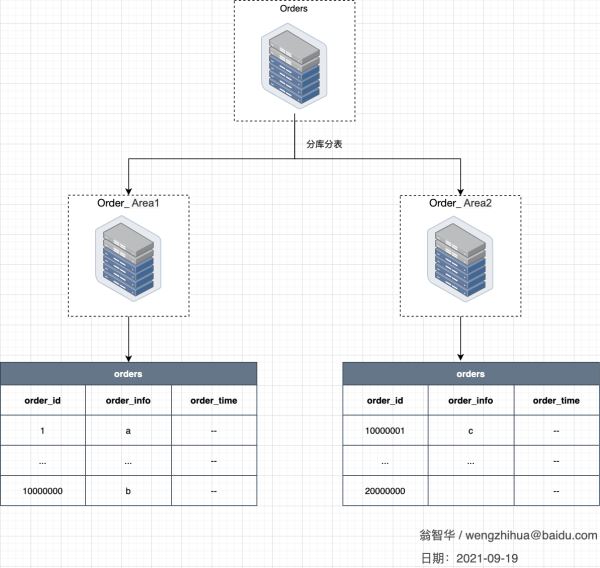
库内分表解决了单表数据量过大的瓶颈问题,但使用还是同一主机的CPU、IO、内存,另外单库的连接数也有限制,并不能完全的降低系统的压力。
此时,我们就要考虑另外一种技术叫分库分表。分库分表在库内分表的基础上,将分的表挪动到不同的主机和数据库上。可以充分的使用其他主机的CPU、内存和IO资源。 拆分方式进一步演进到下面:
4 分库分表存在的问题
4.1 事务问题
在执行分库分表之后,由于数据存储到了不同的库上,数据库事务管理出现了困难。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
4.2 跨库跨表的join问题
在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上,这时,表的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表,结果原本一次查询能够完成的业务,可能需要多次查询才能完成。
4.3 额外的数据管理负担和数据运算压力
额外的数据管理负担,最显而易见的就是数据的定位问题和数据的增删改查的重复执行问题,这些都可以通过应用程序解决,但必然引起额外的逻辑运算,例如,对于一个记录用户成绩的用户数据表userTable,业务要求查出成绩最好的100位,在进行分表之前,
只需一个order by语句就可以搞定,但是在进行分表之后,将需要n个order by语句,分别查出每一个分表的前100名用户数据,然后再对这些数据进行合并计算,才能得出结果。
本篇关于《Mysql数据库分库分表全面瓦解》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于数据库的相关知识,请关注golang学习网公众号!
-
162 收藏
-
188 收藏
-
182 收藏
-
185 收藏
-
470 收藏
-
数据库 · MySQL | 2天前 | MySQL · 权限管理 · 备份 · mysqldump · 数据库安全 · 最小权限 mysqldump备份账号 MySQL角色 partial_revokes 备份权限413 收藏
-
278 收藏
-
数据库 · MySQL | 3天前 | MySQL · JSON · 索引 · 数据库 · 查询优化 · 生成列 · json_extract 索引优化 列表筛选 生成列 MySQL JSON JSON索引351 收藏
-
数据库 · MySQL | 4天前 | MySQL · 认证 · MySQL 8.4 · 数据库升级 · caching_sha2_password mysql_native_password 账号认证 MySQL 8.4 升级迁移236 收藏
-
471 收藏
-
数据库 · MySQL | 6天前 | MySQL · 数据库 · SQL · ON DUPLICATE KEY UPDATE · VALUES · 行别名 · MySQL VALUES() 弃用 ON DUPLICATE KEY UPDATE MySQL 行别名 INSERT AS new MySQL upsert INSERT SELECT117 收藏
-
数据库 · MySQL | 6天前 | MySQL · 索引 · limit · explain · sql优化 · ORDER BY · mysql order by explain limit 复合索引 filesort279 收藏
-
数据库 · MySQL | 1星期前 | 并发 · MySQL · InnoDB · update · 库存扣减 · innodb MySQL 库存扣减 条件 UPDATE 防超卖 affected rows470 收藏
-
421 收藏
-
189 收藏
-
412 收藏
-
378 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习