MySQL数据清理的需求分析和改进
来源:51cto
时间:2023-01-24 11:07:16 479浏览 收藏
本篇文章向大家介绍《MySQL数据清理的需求分析和改进》,主要包括MySQL、数据清理、需求分析,具有一定的参考价值,需要的朋友可以参考一下。

昨天帮一个朋友看了MySQL数据清理的问题,感觉比较有意思,具体的实施这位朋友还在做,已经差不多了,我就发出来大家一起参考借鉴下。
为了保证信息的敏感,里面的问题描述可能和真实情况不符,但是问题的处理方式是真实的。
首先这位朋友在昨天下午反馈说他有一个表大小是近600G,现在需要清理数据,只保留近几个月的数据。按照这个量级,我发现这个问题应该不是很好解决,得非常谨慎才对。如果是通用的思路和方法,我建议是使用冷热数据分离的方式。大体有下面的几类玩法:
exchange partition,这是亮点的特性,可以把分区数据和表数据交换,效率还不错。
rename table,这是MySQL归档数据的一大利器,在其他商业数据库里很难实现。
但是为了保险起见,我说还是得看看表结构再说。结果看到表结构,我发现这个问题和我预想的完全不一样。
这个表的ibd文件大概是600G,不是分区表,InnoDB存储引擎。字段看起来也不多。需要根据时间字段update_time抽取时间字段来删除数据。
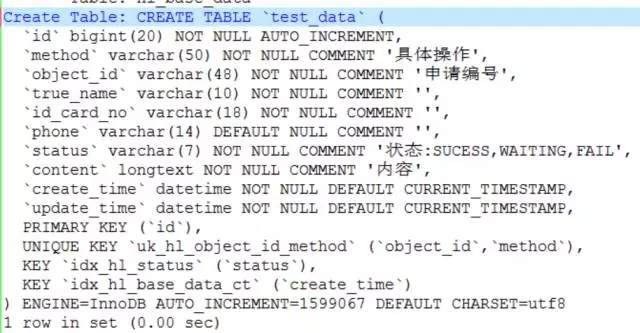
我看了下这个表结构,字段不多,除了索引的设计上有些冗余外,直接看不到其他的问题,但是根据数据的存储情况来看,我发现这个问题有些奇怪。不知道大家发现问题没有。
这个表的主键是基于字段id,而且是主键自增,这样来看,如果要存储600G的数据,表里的数据量至少得是亿级别。但是大家再仔细看看自增列的值,会发现只有150万左右。这个差别也实在太大了。
为了进一步验证,我让朋友查询一下这个表的数据量,早上的时候他发给了我***的数据,一看更加验证了我的猜想。
mysql> select max(Id) from test_data; +---------+ | max(Id) | +---------+ | 1603474 | +---------+ 1 row in set (0.00 sec)
现在的问题很明确,表里的数据不到200万,但是占用的空间近600G,这个存储比例也实在太高了,或者说碎片也实在太多了吧。
按照这个思路来想,自己还有些成就感,发现这么大的一个问题症结,如果数据没有特别的存储,200万的数据其实也不算大,清理起来还是很容易的。
朋友听了下觉得也有道理,从安全的角度来说,只是需要注意一些技巧而已,但是没过多久,他给我反馈,说表里的数据除过碎片,大概也有100多G,可能还有更多。这个问题和我之前的分析还是有一些冲突的。至少差别没有这么大。200万的数据量,基本就在1G以内。但是这里却是100多个G,远远超出我的预期。
mysql> select round(sum(data_length+index_length)/1024/1024) as total_mb, -> round(sum(data_length)/1024/1024) as data_mb, -> round(sum(index_length)/1024/1024) as index_mb -> from information_schema.tables where table_name='hl_base_data'; +----------+---------+----------+ | total_mb | data_mb | index_mb | +----------+---------+----------+ | 139202 | 139156 | 47 | +----------+---------+----------+ 1 row in set (0.00 sec)
这个问题接下来该怎么解释呢。我给这位朋友说,作为DBA,不光要对物理的操作要熟练,还要对数据需要保持敏感。
怎么理解呢,update_time没有索引,id是主键,我们完全可以估算数据的变化情况。
怎么估算呢,如果大家观察仔细,会发现两次提供的信息相差近半天,自增利的值相差是大概4000左右。一天的数据变化基本是1万。
现在距离10月1日已经有24天了,就可以直接估算出数据大概是在1363474附近。
mysql> select current_date-'20171001'; +-------------------------+ | current_date-'20171001' | +-------------------------+ | 24 | +-------------------------+ 1 row in set (0.00 sec)
按照这个思路,我提供了语句给朋友,他一检查,和我初步的估算值差不了太多。
mysql> select id , create_time ,update_time from test_data where id=1363474; +---------+---------------------+---------------------+ | id | create_time | update_time | +---------+---------------------+---------------------+ | 1363474 | 2017-09-29 10:37:29 | 2017-09-29 10:37:29 | +---------+---------------------+---------------------+ 1 row in set (0.07 sec)
简单调整一下,就可以完全按照id来过滤数据来删除数据了,这个过程还是建议做到批量的删除,小步快进 。
前提还是做好备份,然后慢慢自动化完成。
到这里,我们也就讲完了《MySQL数据清理的需求分析和改进》的内容了。个人认为,基础知识的学习和巩固,是为了更好的将其运用到项目中,欢迎关注golang学习网公众号,带你了解更多关于mysql的知识点!
-
374 收藏
-
499 收藏
-
384 收藏
-
184 收藏
-
265 收藏
-
401 收藏
-
312 收藏
-
471 收藏
-
499 收藏
-
382 收藏
-
262 收藏
-
数据库 · MySQL | 4天前 | MySQL · 权限管理 · 备份 · mysqldump · 数据库安全 · 最小权限 mysqldump备份账号 MySQL角色 partial_revokes 备份权限413 收藏
-
278 收藏
-
数据库 · MySQL | 5天前 | MySQL · JSON · 索引 · 数据库 · 查询优化 · 生成列 · json_extract 索引优化 列表筛选 生成列 MySQL JSON JSON索引351 收藏
-
数据库 · MySQL | 6天前 | MySQL · 认证 · MySQL 8.4 · 数据库升级 · caching_sha2_password mysql_native_password 账号认证 MySQL 8.4 升级迁移236 收藏
-
471 收藏
-
数据库 · MySQL | 1星期前 | MySQL · 数据库 · SQL · ON DUPLICATE KEY UPDATE · VALUES · 行别名 · MySQL VALUES() 弃用 ON DUPLICATE KEY UPDATE MySQL 行别名 INSERT AS new MySQL upsert INSERT SELECT117 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 殷勤的小蘑菇
- 这篇技术贴真及时,太全面了,赞 ??,码住,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-03-23 23:51:50
-
- 激情的项链
- 赞 ??,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢up主分享博文!
- 2023-02-23 09:56:07
-
- 标致的毛豆
- 好细啊,已加入收藏夹了,感谢博主的这篇技术文章,我会继续支持!
- 2023-02-20 03:44:59
-
- 高兴的太阳
- 这篇文章真是及时雨啊,作者大大加油!
- 2023-02-16 03:42:54
-
- 受伤的猎豹
- 这篇技术贴真及时,太详细了,感谢大佬分享,已收藏,关注师傅了!希望师傅能多写数据库相关的文章。
- 2023-02-03 17:12:01