mysql面试题
来源:SegmentFault
时间:2023-01-17 13:38:28 157浏览 收藏
亲爱的编程学习爱好者,如果你点开了这篇文章,说明你对《mysql面试题》很感兴趣。本篇文章就来给大家详细解析一下,主要介绍一下MySQL,希望所有认真读完的童鞋们,都有实质性的提高。
一、为什么用自增列作为主键
1、如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择主键作为聚集索引。
如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引。
如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)。
2、如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置(主键插入性能最高,因为是顺序的),当一页写满,就会自动开辟一个新的页
3、如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置
此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
二、为什么在字段上添加索引能提高查询效率
1、添加索引的字段的值,是存放在索引构建的b+tree的叶子节点上,并经过排序存放;
2、如有相关查询进来,会通过索引创建的b+tree获取数据所在的数据页(b+tree与二分查找法配合,只需几次io消耗就可以找到对应的数据页);
3、找到数据页后,将页加载到buffer pool中,再内存中从数据页中获取具体数据;
三、B+树索引和哈希索引的区别
B+树是一个平衡的多叉树结构,从根节点到每个叶子节点的高度差值不超过1,而且同层级的节点间有指针相互链接,是有序的,如下图:
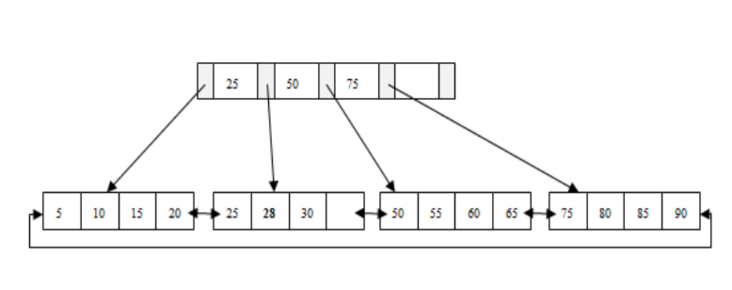
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可,是无序的,如下图所示:
四、哈希索引的优势:
等值查询,哈希索引具有绝对优势(前提是:没有大量重复键值,如果大量重复键值时,哈希索引的效率很低,因为存在所谓的哈希碰撞问题。);MySQL中在缓冲池中会开启自适应哈希索引。
五、说说你对MySQL聚集索引的理解
1、聚集索引的选择:
会优先选择显示创建的主键作为聚集索引;
如果没有则选择第一个创建的非空唯一索引作为聚集索引;
如都没有则系统会创建一个实例级别的rowid作为聚集索引。
2、聚集索引的特点:
聚集索引的键值顺序决定了表数据行的物理顺序;
叶子节点上存放的是整行数据;
一张表只能创建一个聚集索引。
六、说说MySQL如何优化普通索引的写操作
如一个普通索引的插入操作,对于非聚集索引叶子节点的插入不再是顺序的了,这时就需要离散地访问非聚集索引页,由于随机读取的存在而导致了插入操作性能下降。
MySQL通过insert buffer(插入缓冲)这个特性,来优化普通索引的写入操作。
对于非聚集索引的插入操作,不是每一次直接插入到索引页中,而是先判断插入的非聚集索引页是否在缓冲池中,若在,则直接插入;若不在,则先放入到一个Insert Buffer对象中。然后再以一定的频率和情况进行Insert Buffer和辅助索引页子节点的merge(合并)操作,这时通常能将多个插入合并到一个操作中(因为在一个索引页中),这就大大提高了对于非聚集索引插入的性能。
七、说说前缀索引使用的注意事项
建前缀索引时,最重要的是定义好长度,把握好度,即可节省内存使用,又可以减少额外的查询成本;前缀索引会对覆盖索引产生影响
八、说说索引影响着哪些方面
索引关乎着MySQL性能,影响着方方面面;
最主要的有这几点:提升读性能;减少锁等待和死锁;主从复制中sql线程利用索引进行回放,减少主从延迟。
九、什么情况下应不建或少建索引
首先大家要知道索引的用处:索引就是用来从大量数据中获取少部分数据
1、经常更新的字段
2、重复值比较高的字段
3、不经常查询的字段
4、如果表中记录数特别特别少,就不建议在表中字段上创建索引;但是如果达到万级别以上,还是建议创建索引
十、如何限制某ip段下的某个ip用户不允许登录
利用用户ip精确匹配的特点;假如原先用户ergou@'192.168.58.%',重新创建一个用户,如ergou@'192.168.58.51',并重新设置密码;这样就会用户通过用户ergou登录,就会匹配到ergou@'192.168.58.51'。
十一、delete与truncate区别
1、delete是逻辑删除,按行删除数据,效率低,支持回滚;但是大家要知道delete只是做了一个删除的标记,具体的删除是由purge线程完成删除,这才会释放空间
2.truncate是物理删除,释放空间,速度快,不支持回滚
十二、生产中为什么建议字段使用not null约束
1、从性能来说,空值会存放在b+tree的左边,造成索引性能下降
2、空值需要更多的存储空间,多1个字节(null列上建立索引后)
3、造成统计结果的不准确,count(*)会统计允许为null的字段,count(某字段)不含null值
十三、什么情况下使用不到索引
1、where条件:
列进行计算:
explain select * from orders where o_custkey=o_custkey+1;
列使用函数:
explain select * from orders where o_custkey=ceil(o_custkey);
列进行隐式转换:
explain select * from emp where ename=007;
2、联合索引:用到范围查询,只能用到部分索引
3、联表查询:
关联条件字符集不同,不走索引
关联条件的列类型不同,不走索引
4、其他情况:
。select * from emp;
。查询结果集大于数据量的30%,不走索引
explain select * from emp where empno > 7000;
。索引本身失效
。like '%s'
explain select * from emp where ename like '%s';
。not in(111,9999) 普通索引,如果是主键索引,会被优化为范围查询,可以利用索引
explain select * from emp where empno not in(111, 9999);
。!=
explain select * from emp where empno != 9999;
十六、四种隔离级别
读未提交(read-uncommitted)RU,产生脏读
读已提交(read-committed)RC,不会产生脏读,产生不可重复读;
可重复读(repeatable-read)RR,不会产生脏读,不会产生不可重复读;会产生幻读(但是innodb默认会阻止产生幻读,通过锁实现);
可串行化(serializeable),不会产生脏读,不会产生不可重复读;不会产生幻读;完美符合事务,但性能最低
十七、MVVC
MySQL InnoDB存储引擎,实现的是基于多版本的并发控制协议——MVCC (Multi-Version Concurrency Control)
MVCC最大的好处:读不加锁,读写不冲突。在读多写少的OLTP应用中,读写不冲突是非常重要的,极大的增加了系统的并发性能,现阶段几乎所有的RDBMS,都支持了MVCC。
MVCC由数据页中的事务id、回滚指针+undo日志,read view构成
十八、事务两阶段提交
阶段1:写redo log,事务处于prepare
阶段2:写binlog,事务处于commit
写binlog成功有xid事件,会将xid写入redo log
十九、binlog与redo log区别
①redo log是innodb存储引擎独有的,binlog是不区分存储引擎
②记录内容不同,redo log是物理逻辑日志,记录页的变化过程;binlog是逻辑日志,记录事务具体操作的内容
③写入时间不同,先写入redo log,再写入binlog
④redo log是循环使用文件,binlog每次新增一个文件
二十、如何快速将一张大表迁移到其他数据库实例
二十一、事务是如何实现的
二十二、MySQL在RR隔离级别下如何阻止幻读
二十三、生产如何尽量避免死锁
二十四、不同隔离级别下、不同索引下innodb行锁的粒度是什么样的
二十五、mysqldump备份原理
二十六、innodb存储引擎行锁冲突问题
二十七、MySQL在备份时,怎么做到一致性备份
二十八、主从复制原理
二十九、主从复制架构的瓶颈
三十、如何减少主从复制延迟
三十一、过滤复制会产生哪些问题
三十二、主从复制中断如何处理
三十三、1062或者1032错误,如何解决
三十四、如何将数据库回档到任意的一天
三十五、说说5.7和8.0在主从复制方面的改进
三十六、DML变慢的原因
今天关于《mysql面试题》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于mysql的内容请关注golang学习网公众号!
-
374 收藏
-
499 收藏
-
384 收藏
-
184 收藏
-
265 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 结实的水蜜桃
- 这篇文章真及时,师傅加油!
- 2023-03-31 00:03:26
-
- 俊逸的枕头
- 这篇文章内容真是及时雨啊,太全面了,很有用,收藏了,关注作者了!希望作者能多写数据库相关的文章。
- 2023-03-17 04:29:46
-
- 快乐的小鸽子
- 真优秀,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢作者大大分享文章内容!
- 2023-02-28 06:48:34
-
- 单身的故事
- 这篇文章太及时了,好细啊,感谢大佬分享,已收藏,关注作者了!希望作者能多写数据库相关的文章。
- 2023-02-16 12:21:16
-
- 着急的酸奶
- 很有用,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢博主分享文章内容!
- 2023-02-04 16:16:17
-
- 苗条的小鸽子
- 太给力了,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢作者分享文章内容!
- 2023-02-02 16:37:43
-
- 可靠的大米
- 这篇技术贴真是及时雨啊,楼主加油!
- 2023-01-31 03:59:21
-
- 唠叨的河马
- 细节满满,已加入收藏夹了,感谢作者的这篇文章内容,我会继续支持!
- 2023-01-27 13:18:18
-
- 健壮的丝袜
- 细节满满,收藏了,感谢老哥的这篇博文,我会继续支持!
- 2023-01-24 18:52:34
-
- 娇气的老师
- 这篇文章太及时了,细节满满,很好,已收藏,关注师傅了!希望师傅能多写数据库相关的文章。
- 2023-01-24 07:53:03
-
- 时尚的铅笔
- 这篇技术文章出现的刚刚好,细节满满,赞 ??,mark,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-01-20 22:53:31