无效回表谁的锅?存储引擎:这事儿不赖我
来源:SegmentFault
时间:2023-01-16 21:04:43 263浏览 收藏
来到golang学习网的大家,相信都是编程学习爱好者,希望在这里学习数据库相关编程知识。下面本篇文章就来带大家聊聊《无效回表谁的锅?存储引擎:这事儿不赖我》,介绍一下MySQL、Java、后端、程序员,希望对大家的知识积累有所帮助,助力实战开发!
明确场景
要回答这个问题,我们一般分几步来走:
1.确认问题,对齐Sql语句;
2.解答问题本身,也就是时间复杂度分析;
3.针对本身提出这个场景,可能出现的性能瓶颈进行分析;
4.针对瓶颈,提出多种优化手段。
接下来我们就按照这个思路来一步步深入。
对齐Sql语句
通常而言,面试官抛出一个问题,不见得就是一个非常完善、非常准确的描述,他其实是希望你能提出问题,通过沟通对齐,这也是工作中必备的能力。
首先问面试官,目前表的结构大概是怎样,索引的建设,又是怎样的,假设通过沟通,我们得到如下简化过的表t_player:
只在score字段上建了二级索引,大小是从小到大。这里要找第k个,其实就是偏移k-1:
select * from t_player order by
时间复杂度分析
这个问题的核心就是查找语句的时间复杂度是多少?
这道题实际是有一定引导性的,故意说索引,就是想让你往树分支上引,我们都知道,走索引,按数值本身查找一个数据,那二级索引的时间复杂度,肯定是O(logN)。
但这题不一样,是找第k个,比如第100个,我们其实是不知道树的分支结构具体是怎样的,也就是说我们不知道左子树有多少个节点,右子树有多少个节点。
进一步而言,我们没法确定走哪条路,树的分支结构不可行。
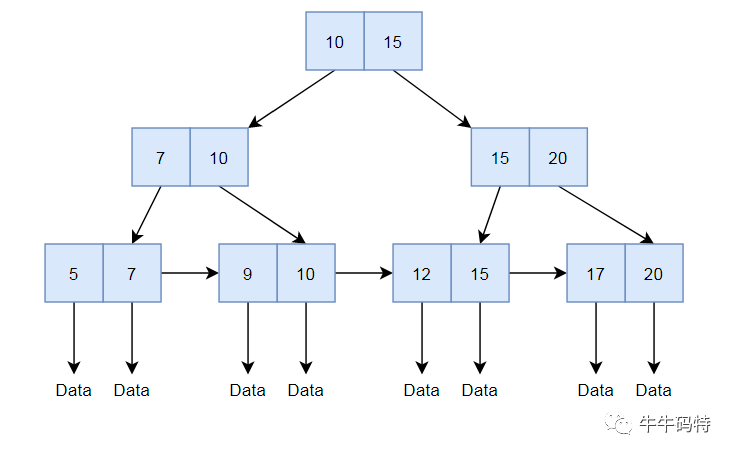
所以这里其实是考察B+树的理解,B+树除了分支,底层还有一个双链表,直接走双链表查询,反而是更快的了。
时间复杂读O(N),我们反过来想,其实这道题就是考你B+树数据结构,如果直接问你B+树结构,大多数有准备的同学,都能回答清楚,但是通过一个实际问题来问你,只有真正理解其作用,才能快速答出。
这就完了吗?当然没有,这只是一个起手式,下一步,面试官肯定会问你这个操作的性能如何,当然你也可以主动谈起。
offet慢问题
如果offset大于10000,这个数据查询就会非常的慢。为什么会慢呢,一般都会答因为遍历,时间复杂度是O(N)。
但实际如果你测试一下,你会发现这条语句会慢得离谱,这绝不是所谓遍历能导致的。
更深层次的原因在于,对于前10000个不需要的数据,MySQL每次也要回表去查找,这就导致了10000次随机IO,当然慢成狗。
优化方案
如果有开发经验的同学,会很容易想到从业务形态上去优化,这里就不卖关子了,这种场景通常有三种解决方案。
1.业务上绕过
将limit、offset,改为next,也就是将第x页,改为下一页,这样就
可以通过树分支查找。
举个例子,百度的搜索界面,就是典型的分页面。

而现在移动互联网时代,用得更多的就是上一页、下一页这样的翻页逻辑,微博、抖音都是这样的逻辑。
--- 记录score为prev_score
使用这种模式,可以利用树索引直接找到目标,也绕过了无效回表问题,在Offset超过一万的情况下,性能通常都能提高两个量级以上。
当然,这种适合给分页做优化,如果回到我们题目本身来说,那查找第k大的数,就需要循环“下一页”下去,损耗反而更大。
2.硬碰硬
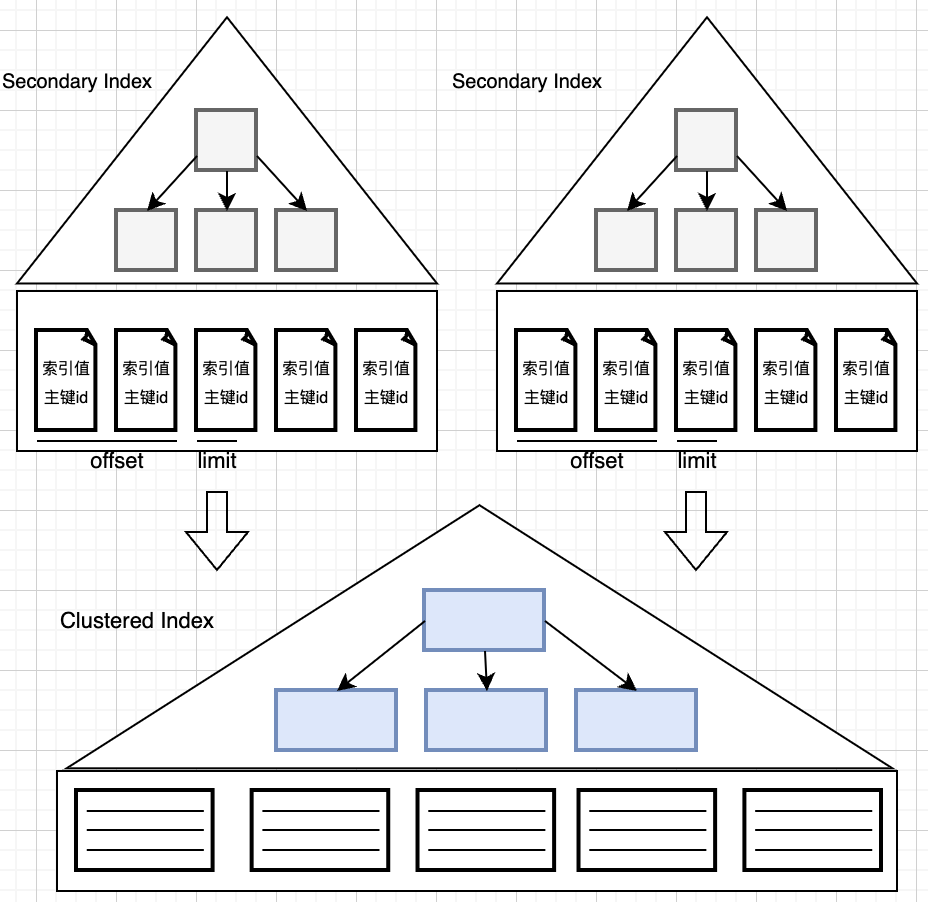
上面分析了,对无用数据还回表查询,导致大量随机IO,是性能的核心瓶颈,那我们对症下药,能否不回表呢?
当然可以,我们可以进行索引覆盖。
索引覆盖是说当二级索引查询的数据都在二级索引本身,比如索引Key或主键ID,那么就不必再去查聚簇索引。
那你可能会问,在我们的场景,还有其它需要查询的信息,比如名字,并不在二级索引上啊。
是的,但我们可以通过sql的拆分,来达到目的,思路如下:
select * from t_player id in
这句话是说,先从条件查询中,查找数据对应的数据库唯一id值,因为主键在辅助索引上就有,所以不用回归到聚簇索引的磁盘上拉取。
如此以来,offset部分均不需要去反查聚蔟索引,只有limit出来的10个主键id会去查询聚簇索引,这样只会1次IO。在业务确实需要用分页的情况下,使用该方案可以大幅度提高性能,通常能满足性能要求。有同学可能担心本身走B+树的双指针会是瓶颈,牛哥也做了测试:一张500w的表,offset 10000,要是没索引覆盖,处理时间甚至可以达到十秒级,有了的话,能降低到十毫秒级,有质的飞跃。ps:具体时耗和数据库性能等因素有关,以上数据只是参考。
3.预判边界值
这其实也是根据业务场景的做法,能通过业务预判边界,这种方式并不是通用解决方案,但因为《高性能MySQL》中提到了,也一并列出来。
深层次灵魂发问
为什么MySQL不直接丢掉无用数据,还要傻乎乎地回表?
也许你曾经听过一个词,叫索引下推,在MySQL5.6之后,MySQL通过索引下推提升了性能。
这个问题也类似,答案是Offset未曾下推!我们先review下查找流程:
1.存储引擎通过二级索引查找,获取主键值;2.进行回表操作,将完整记录返回给上层;3.上层判断是否需要该记录,需要则返回给客户端,不需要则跳过该记录;4.存储引擎接着查找下一条;
5.重复第二步。
从流程其实我们能看出,存储引擎层是没有Offset信息的。
牛哥和咱们训练营导师虎哥也讨论过这个问题,虎哥的解释还是比较到位的:
MySQL不做的原因,无非两点:
1.限制场景太多,给多个引擎做有点得不偿失;
2.更核心的,分层设计理念,这件事本身是Sql层的,本就不该存储引擎做。
野生db
那我们现在来看看所谓的野生db的情况:
野生db1号:阿里云

野生db 2号:腾讯云

另外,腾讯云还描述了适用场景:

下推之后阿里云测试了性能,Q3即我们二级索引order by ... limit回表的场景,可以看到从25s降低到了329ms左右,相差75.82倍。
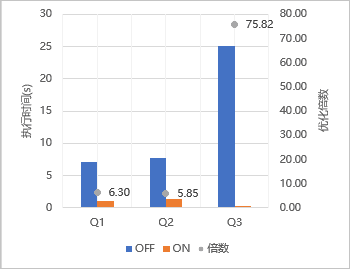
可以发现阿里腾讯两大云厂商MySQL自研版本都做了下推,那MySQL从技术上自然也能。
有大佬针对这个问题还给MySQL提了bug。https://bugs.mysql.com/bug.ph...
还带了修复方案:
https://bugs.mysql.com/file.p...
当然mysql有自己的设计理念和坚持,可能以后也不会采纳。
而将阿里云、腾讯云这些称为野生db,其实也只是调侃的说法。
实际上他们都遵循实用原则,是非常优秀的团队,自研产品的决策灵活性本身也更高一些。
这倒不是非要分个孰优孰劣,大家搞清楚前因后果即可。
补丁分析
虽然我们已经将前因后果弄得很清楚,但相信还是会有同学好奇,上面的大佬做的补丁,到底是怎样的。牛哥和虎哥,也做了一些分析。
核心要素就是在引擎层增加了这么一个函数,可以下推索引。
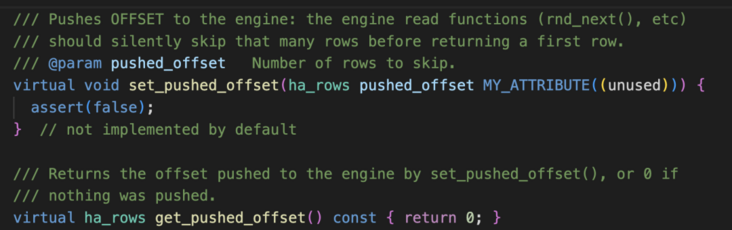
这个函数有几层,最核心的其实在这里:
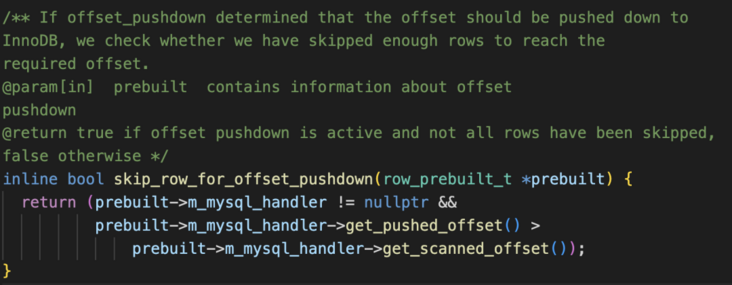
其实就是offset判断,如果offset比现在的遍历偏移还大,就跳过。
Sql层会调用引擎层这个函数,当然调用之前会有个判断。
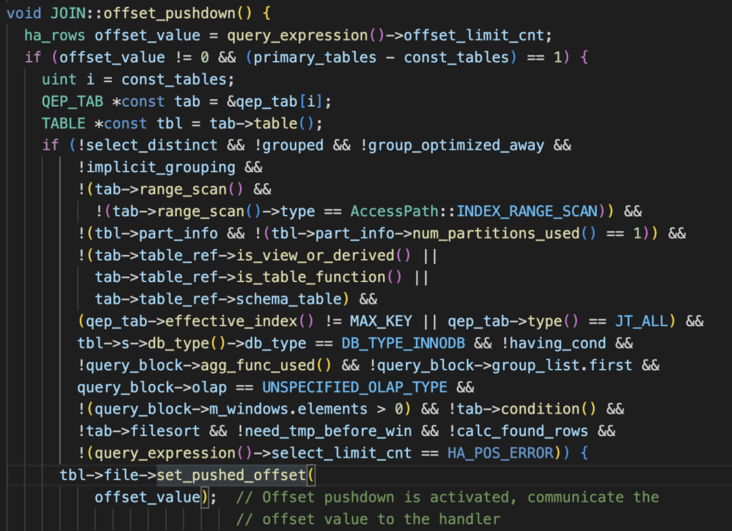
很复杂是吧,没事,咱们看注解:
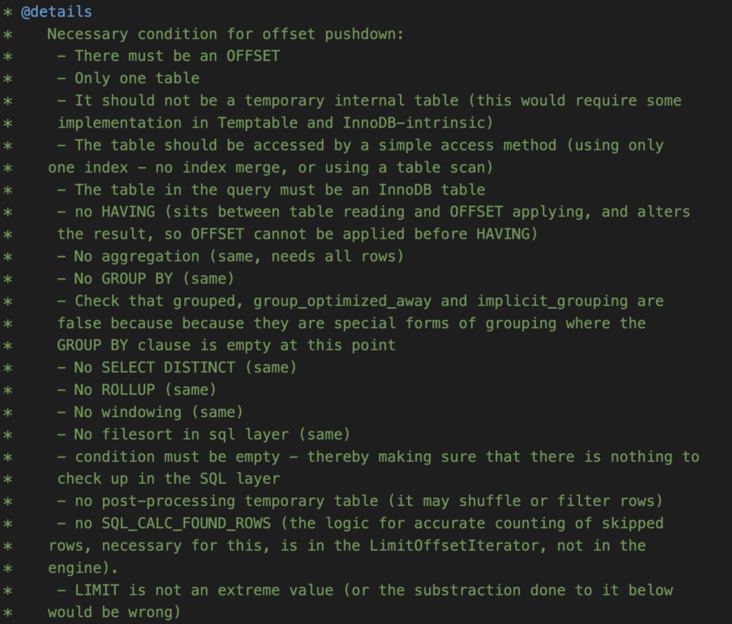
其实就是限制了很多情况,比如group by,having这种推了也不顶用的,就不推了。
Review一下
可以看到,看起来很简单的一个问题,其实牵涉到的知识很广:
首先时间复杂度是多少?考察B+树结构;
Offset为什么慢?考察对底层行为一定程度的掌握;
几种解决方案?考察技术视野和解决问题的能力;
深层次行为原因?考察MySQL分层架构,及对开源社区的关注。
如果你只是背八股文,而不去深入探索其中的原理,那面试官随便问几个问题,就能看出你其实基础是不扎实的。
这里不是说八股文不好,而是不能觉得面试就是考八股文,这其实是一个很大的误区。
今天关于《无效回表谁的锅?存储引擎:这事儿不赖我》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于mysql的内容请关注golang学习网公众号!
-
374 收藏
-
499 收藏
-
384 收藏
-
184 收藏
-
265 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 威武的春天
- 这篇文章真是及时雨啊,很详细,很有用,mark,关注师傅了!希望师傅能多写数据库相关的文章。
- 2023-04-16 19:52:27
-
- 无聊的画笔
- 感谢大佬分享,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢楼主分享博文!
- 2023-02-26 04:17:07