【整理汇总】Clickhouse的常见问题(附解决方法)
来源:SegmentFault
时间:2023-02-18 09:19:49 450浏览 收藏
本篇文章主要是结合我之前面试的各种经历和实战开发中遇到的问题解决经验整理的,希望这篇《【整理汇总】Clickhouse的常见问题(附解决方法)》对你有很大帮助!欢迎收藏,分享给更多的需要的朋友学习~
常见问题
偶尔出现 CLOSE_WAIT 情况
CLOSE_WAIT 占用的是网络端口资源,一台机器可以有6万多个端口,如果偶尔有 CLOSE_WAIT 的情况,也不用太着急 ,只要 CLOSE_WAIT 不是迅速持续地增加,一般来说该情况也会在数小时后被系统回收掉。
频繁出现 CLOSE_WAIT 情况
如果系统有大量CLOSE_WAIT,主要表现是在有句柄操作时会报"too many open files" 的问题,这时候服务不可访问,甚至 SSH 都连不上。 但"too many open files" 的问题也有可能是打开的文件句柄太多导致,即 ClickHouse 写入太频繁或者查询的时候经常要查大量的历史数据。
出现"too many parts" 情况
"too many parts" 一般是 ClickHouse 写入太频繁,导致 Parts 没有及时合并引起的,也有可能有大查询导致磁盘 IO 被占用而受影响。
出现"too many simultaneous queries" 情况
"too many simultaneous queries" 表面上来看是查询并发引起的,但通常情况下也有可能是因为有 大查询占用了大量的磁盘,导致很多查询请求堆积而超过了阈值引发的。
ClickHouse 里的并发请求都是存在 processes 表中,所有待执行与正在执行的请求均在该表中,当请求执行完之后便会被清除。出现"too many simultaneous queries" 错误时,便是根据这张表中求求的数量和 config.xml 的 max_concurrent_queries参数来对比的,如果 processes 中的数量超过了 max_concurrent_queries,就会报 "too many simultaneous queries",该现象可以理解为一种限流的保护机制。如果一个请求执行花了很长时间,它在processes表中待的时间就很长,如果很多请求均出现这样的情况,那么 processes 中的记录就有可能超过 max_concurrent_queries。
Clickhouse 的 CPU 使用率与 CPU Load 飙升
大查询引起
包括Join查询、未带分区的查询、表结构定义没有使用好分区和主键、实际数据量过大、并发查询、Bug等;
ClickHouse 副本同步引起
故障描述
Clickhouse 节点意外挂掉重启后 CPU Load 值持续飙升(超过 CPU 核数)无法恢复,节点不能正常提供服务,同步数据处于卡死状态;
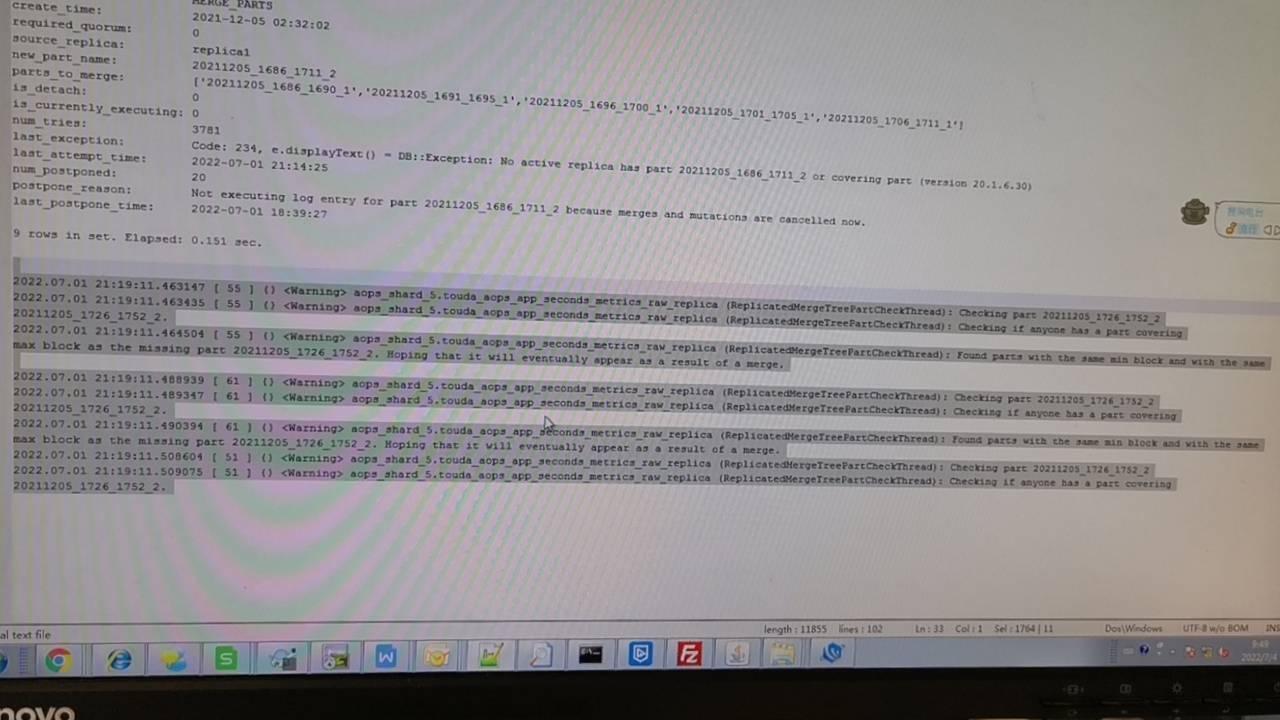
查询集群中每个节点的 system.replication_queue,存在异常 MERGE_PARTS 类型任务,日志中有 "No active replica has part ... or covering part" 报错信息。
处理办法
问题出现的原因为 Clickhouse V20 有相关 Bug。当一些副本中有 Parts 丢失,此时副本同步队列中有异常任务时则会导致副本之前的同步出现死锁现象,具体处理步骤如下:
在集群中每个节点上,通过 clickhouse-clinet 连接后, 查询 system.replication_queue 表,看有无异常任务;
SELECT * FROM system.replication_queue WHERE create_time如果节点存在上述异常任务,执行下面的 SQL 查出 zookeeper 上的 Path;
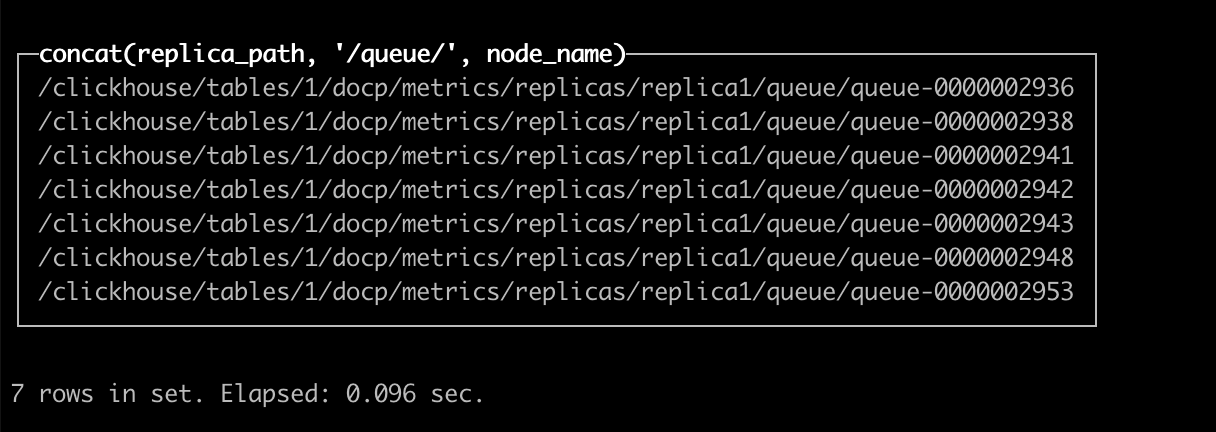
SELECT replica_path || '/queue/' || node_name FROM system.replication_queue JOIN system.replicas USING (database, table) WHERE create_time类似:
在 shell 中执行下面的命令,将队列中异常任务的 path 输出到 clickhouse_exception.log 文件中;
clickhouse-client --query "SELECT replica_path || '/queue/' || node_name FROM system.replication_queue JOIN system.replicas USING (database, table) WHERE create_time clickhouse_exception.log在 ClickHouse 集群对应的 Zookeeper 节点上,访问 ./zookeeper-shell.sh 127.0.0.1:2181,连接 zookeeper 后,按 clickhouse_exception.log 中记录的 path, 逐一执行删除 path 的操作。需注意,该操作非常危险,一定要确认 rmr 后面的路径与clickhouse_exception.log 中的路径一样。参考示例如下:
rmr /clickhouse/tables/1/docp/metrics/replicas/replica1/queue/queue-0000003433当异常的 Path 删除完成后,在当前 ClickHouse 节点的 Clickhouse-client 中执行
SYSTEM RESTART REPLICAS命令,使副本同步任务重启;按上述步骤对其他节点进行处理,并再次检查已经处理过的节点。
解决思路
首先需分析故障情况是否为近期出现,如果是,则需查看近期是否有其他变更;
如果近期未有其他变更,则需要查看机器的 CPU 、网络、内存、磁盘等负载情况。程序在超负荷状态下会出现各种问题,因此,首先要将负荷降到正常状态再来排查问题;
机器负载异常,要从两方面分析。一方面有可能是程序异常引起了高负载,另一方面也有可能是高负载引起了程序异常,如果不好判断,则用排除法,可以卸载一些功能来看负载的变化;
如果当前故障为历史问题,则需回到问题初次显现的时间点来分析。
总结
程序是运行在OS 和硬件上的,程序和 OS 息息相关,程序的一些问题会反馈到 OS 的指标上,OS 上的指标也能看出来程序运行的一些问题,所以只有掌握如何看机器负载,对相关指标有清晰的认识才能更好的做好排障工作。通常下面这样情况均需要引起重视:
CPU Load5 及 Load10 超过 CPU 核数;
机器的空闲内存超过90%;
CPU 平均使用率超过90%;
磁盘使用率超过90%,磁盘 util 持续超过90%;
网络上传下载速率超过带宽的80%。
开源项目推荐
云智慧已开源数据可视化编排平台 FlyFish 。通过配置数据模型为用户提供上百种可视化图形组件,零编码即可实现符合自己业务需求的炫酷可视化大屏。 同时,飞鱼也提供了灵活的拓展能力,支持组件开发、自定义函数与全局事件等配置, 面向复杂需求场景能够保证高效开发与交付。
如果喜欢我们的项目,请不要忘记点击下方代码仓库地址,在 GitHub / Gitee 仓库上点个 Star,我们需要您的鼓励与支持。此外,即刻参与 FlyFish 项目贡献成为 FlyFish Contributor 的同时更有万元现金等你来拿。
GitHub 地址: https://github.com/CloudWise-OpenSource/FlyFish
Gitee 地址: https://gitee.com/CloudWise/f...
微信扫描识别下方二维码,备注【飞鱼】加入 AIOps 社区飞鱼开发者交流群,与 FlyFish 项目 PMC 面对面交流~
文中关于mysql的知识介绍,希望对你的学习有所帮助!若是受益匪浅,那就动动鼠标收藏这篇《【整理汇总】Clickhouse的常见问题(附解决方法)》文章吧,也可关注golang学习网公众号了解相关技术文章。

-
374 收藏
-
398 收藏
-
499 收藏
-
384 收藏
-
184 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 甜蜜的羊
- 这篇技术文章太及时了,细节满满,受益颇多,码起来,关注楼主了!希望楼主能多写数据库相关的文章。
- 2023-06-03 23:18:43
-
- 甜蜜的水壶
- 太细致了,收藏了,感谢大佬的这篇文章内容,我会继续支持!
- 2023-05-30 11:22:29
-
- 爱撒娇的吐司
- 这篇技术文章真是及时雨啊,太详细了,真优秀,已加入收藏夹了,关注师傅了!希望师傅能多写数据库相关的文章。
- 2023-04-02 19:48:02
-
- 哭泣的铅笔
- 细节满满,收藏了,感谢老哥的这篇技术文章,我会继续支持!
- 2023-03-06 13:32:17
-
- 冷静的画板
- 写的不错,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢博主分享技术文章!
- 2023-02-24 18:12:51
-
- 凶狠的日记本
- 感谢大佬分享,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢老哥分享文章内容!
- 2023-02-22 08:14:25