构建面向特征工程的数据生态 ——拥抱开源生态,OpenMLDB全面打通MLOps生态工具链
来源:SegmentFault
时间:2023-01-22 17:46:31 442浏览 收藏
知识点掌握了,还需要不断练习才能熟练运用。下面golang学习网给大家带来一个数据库开发实战,手把手教大家学习《构建面向特征工程的数据生态 ——拥抱开源生态,OpenMLDB全面打通MLOps生态工具链》,在实现功能的过程中也带大家重新温习相关知识点,温故而知新,回头看看说不定又有不一样的感悟!
引言:随着业务的发展,模型应用场景的增加,AI 工程化落地成为了不少企业面对的切实挑战。近几年,应对这个痛点的新概念——MLOps 逐渐成为了机器学习领域的热门话题。OpenMLDB 提供FeatureOps 全栈解决方案,积极打通 MLOps工具链,建立起一个标准化的模型开发、部署与运维流程,降低开发者落地 AI 的门槛,使得企业组织能够更好地利用机器学习的能力来促进业务增长。
关于OpenMLDB
OpenMLDB 是一个开源机器学习数据库,致力于闭环解决 AI 工程化落地的数据治理难题。自2021 年 6 月开源以来,OpenMLDB 优先开源了特征数据治理能力,依托 SQL 的开发能力,为企业提供全栈功能的、低门槛特征数据计算和管理平台。
OpenMLDB 包含 Feature Store 的全部功能,并且提供更为完整的 FeatureOps 全栈方案。除了提供特征存储功能,还具有基于 SQL 的低门槛数据库开发体验、面向特征计算优化的 OpenMLDB Spark 发行版,针对实时特征计算优化的索引结构,特征上线服务、企业级运维和管理等功能,让特征工程开发回归于本质——专注于高质量的特征计算脚本开发,不再被工程化效率落地所羁绊。 MLOps完整生命周期
在机器学习解决方案的开发、测试、部署、支持过程中,分工合作的多学科专家或团队会在协作中遇到许多沟通难题和技术障碍,这些痛难点不仅延长了产品工程化落地的时间,还增加了成本、减少了价值空间。
为了消除这些障碍,MLOps这一概念应运而生,并在近几年承接了广泛的关注和极大的期待,MLOps旨在统一 ML 系统开发(dev)和 ML 系统部署(ops),以标准化过程生产高性能模型的持续交付,达到更快试验和开发模型、更快将模型部署到生产环境、保证质量的目的。
在MLOps 运作的闭环流程中,MLOps常被分为离线开发和线上服务两个部分,对应着机器学习相关开发中,模型训练和模型上线的两个部分。当我们把这离线开发和线上服务放置在企业级的生产场景当中,它们又可以进一步地拆解为 DataOps、FeatureOps 和 ModelOps 三个环节。
- 在离线开发中,DataOps 承担数据采集、存储的工作,FeatureOps 进行特征的储存、共享和离线特征计算,ModelOps 负责模型训练以及超参数调优
- 在线上服务时,DataOps 承担在线推理、结果数据回流的工作,FeatureOps 进行实时特征计算与特征服务 ,ModelOps 负责实时数据流接入以及处理实时请求
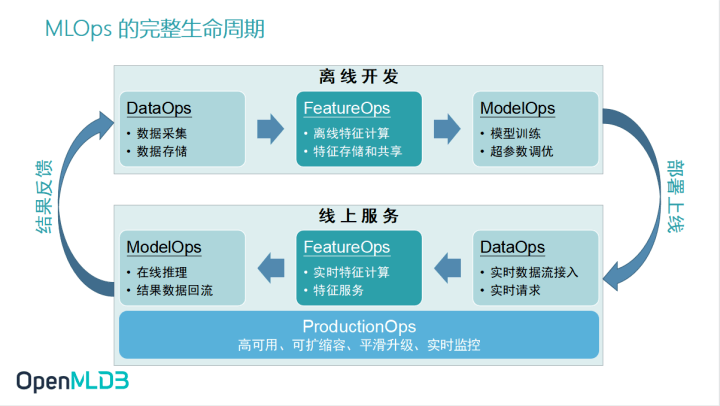
为满足企业级生产需求,ProductionOps作为企业人工智能工程化落地中的另外一个关键环节,值得引起开发者的关注和重视。在生产环境之下,企业会非常看重高可用、可扩缩容、平滑升级、实时监控等等企业级核心需求。所以 ProductionOps 也是 OpenMLDB 作为 FeatureOps 优化升级过程中备受关注的一环。
OpenMLDB 面向 MLOps 的生态工具链
将OpenMLDB投射到包含DataOps、FeatureOps 和 ModelOps三大板块的MLOps中,可以看到OpenMLDB占据着其中FeatureOps的位置,主要是承担特征计算的职能。
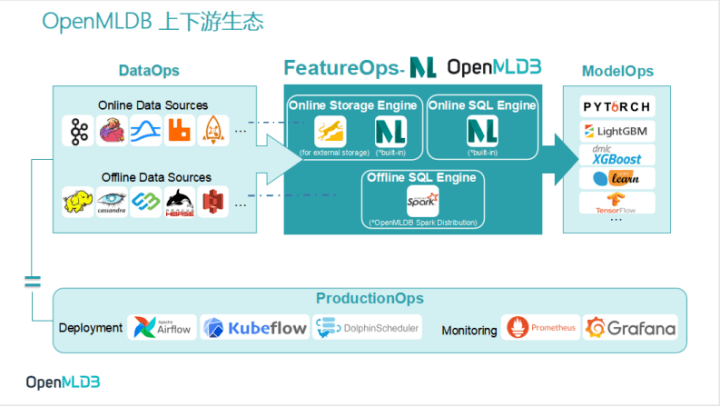
1、OpenMLDB内部框架
OpenMLDB的内部架构可简单分为在线引擎和离线引擎两部分,分别支持在线特征计算和离线特征计算。
- 在线引擎:分为在线执行引擎和在线储存引擎。
在线执行引擎,即 Online SQL Engine,是 OpenMLDB 的自研引擎,被用于高性能的 SQL 计算。 在线存储引擎,出于储存最新实时数据的需要,OpenMLDB 在 SQL 执行层面创建了一个 Storage engine,于默认情况下会有 in memory storage(build in)。Storage engine 可以被理解为一个非常高效的、专门面向时序数据库进行优化的一个内存数据库。
(Tips:除自研的在线存储引擎外,OpenMLDB 也支持磁盘数据,即将上新的 OpenMLDB v 0.5.0的版本将提供两种不同的 Storage Engine。对性能要求高,可以选择 in memory storage engine;更重视成本,那么可以使用基于磁盘的存储,如 RocksDB。)
- 离线引擎:即Offline SQL Engine。是基于原版Spark做了合理的优化升级,可以更高效地应用于离线特征计算。
2、OpenMLDB 上游生态——DataOps(即 Data sources)
DataOps 是 OpenMLDB 的数据获取源,即生态上游。在 Online data sources 板块,OpenMLDB社区于前不久发布了 OpenMLDB Pulsar connector, 支持 Pulsar 数据的接入。
OpenMLDB Pulsar Connector 下载地址
https://github.com/4paradigm/... 未来新发布的版本中,OpenMLDB Kafka connector 也将与大家见面,为用户增加数据接入的多种选择,提供便利。在 Offline data sources板块,OpenMLDB 现支持 HDFS、S3 数据的直接接入,未来也会扩展更多的数据源。
3、OpenMLDB下游生态——ModelOps
ModelOps是OpenMLDB的下游模型生态。下游模型通过一些标准输出格式,就能直接接入。在5月初即将发布的v0.5.0版本中,OpenMLDB将整合模型特征功能,通过输出标准的 LIBSVM 或者 CSV 的格式,可直接供 PyTorch 等计算框架使用。
4、OpenMLDB部署生态——ProductionOps
ProductionOps层面的部署编排也在OpenMLDB的规划当中。目前,OpenMLDB 已经和 Airflow 和 Kubeflow 进行了对接,有望在近期完成与 Airflow 的合作内容。监控方面,OpenMLDB 已经和 Prometheus 和 Grafana 做了对接。
结语:
作为国内首个开源机器学习数据库,OpenMLDB始终坚持研发创新,全面提升产品性能和易用性;作为生产级 FeatureOps 全栈解决方案的提供者,OpenMLDB一直积极构建MLOps生态工具链,不断加强开源上下游合作共建。 获取更多OpenMLDB产品及生态内容,欢迎关注社区的官网、Github主页、知乎账号,也可扫描下方二维码直接加入社区技术交流微信群。
OpenMLDB - 生产级特征开发全栈解决方案
GitHub - 4paradigm/OpenMLDB: OpenMLDB is an open-source machine learning database that provides a full-stack FeatureOps solution for production.
4PD开发者社区 - 知乎

终于介绍完啦!小伙伴们,这篇关于《构建面向特征工程的数据生态 ——拥抱开源生态,OpenMLDB全面打通MLOps生态工具链》的介绍应该让你收获多多了吧!欢迎大家收藏或分享给更多需要学习的朋友吧~golang学习网公众号也会发布数据库相关知识,快来关注吧!
-
374 收藏
-
398 收藏
-
499 收藏
-
384 收藏
-
184 收藏
-
数据库 · MySQL | 20小时前 | MySQL · JSON · 索引 · 数据库 · 查询优化 · 生成列 · json_extract 索引优化 列表筛选 生成列 MySQL JSON JSON索引351 收藏
-
数据库 · MySQL | 1天前 | MySQL · 认证 · MySQL 8.4 · 数据库升级 · caching_sha2_password mysql_native_password 账号认证 MySQL 8.4 升级迁移236 收藏
-
471 收藏
-
数据库 · MySQL | 3天前 | MySQL · 数据库 · SQL · ON DUPLICATE KEY UPDATE · VALUES · 行别名 · MySQL VALUES() 弃用 ON DUPLICATE KEY UPDATE MySQL 行别名 INSERT AS new MySQL upsert INSERT SELECT117 收藏
-
数据库 · MySQL | 4天前 | MySQL · 索引 · limit · explain · sql优化 · ORDER BY · mysql order by explain limit 复合索引 filesort279 收藏
-
数据库 · MySQL | 5天前 | 并发 · MySQL · InnoDB · update · 库存扣减 · innodb MySQL 库存扣减 条件 UPDATE 防超卖 affected rows470 收藏
-
421 收藏
-
189 收藏
-
412 收藏
-
378 收藏
-
334 收藏
-
259 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 重要的芹菜
- 很有用,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢作者大大分享博文!
- 2023-02-20 02:55:58
-
- 细腻的大山
- 很详细,已收藏,感谢up主的这篇文章内容,我会继续支持!
- 2023-02-10 23:50:39
-
- 耍酷的八宝粥
- 这篇技术贴出现的刚刚好,细节满满,很棒,收藏了,关注师傅了!希望师傅能多写数据库相关的文章。
- 2023-02-04 19:24:37