.Net/C#分库分表高性能O(1)瀑布流分页
来源:SegmentFault
时间:2023-02-24 08:02:15 451浏览 收藏
本篇文章主要是结合我之前面试的各种经历和实战开发中遇到的问题解决经验整理的,希望这篇《.Net/C#分库分表高性能O(1)瀑布流分页》对你有很大帮助!欢迎收藏,分享给更多的需要的朋友学习~
框架介绍
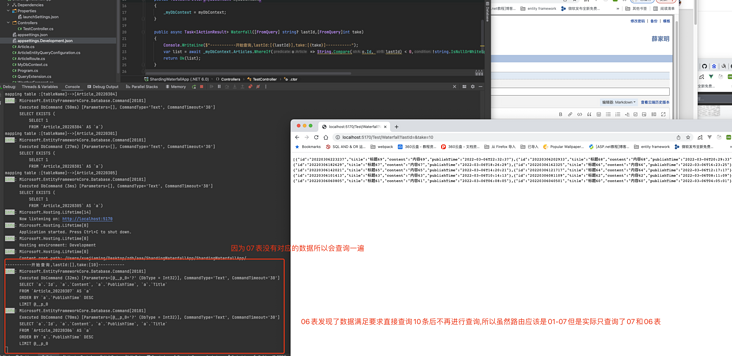
因为07表是没有的所以这次查询会查询07和06表,之后我们进行下一次分页传入上次id
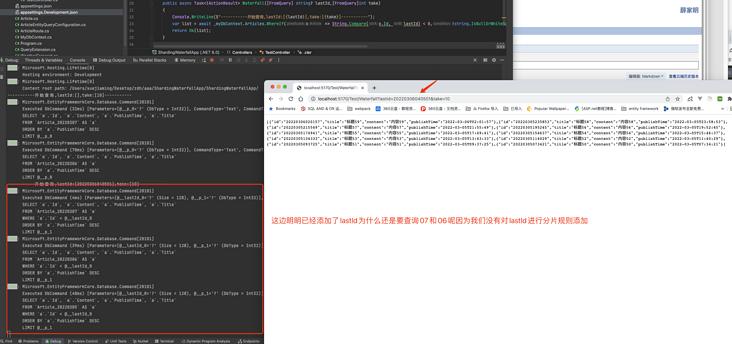
因为没有对
public class ArticleRoute:AbstractSimpleShardingDayKeyDateTimeVirtualTableRoute
{
public override void Configure(EntityMetadataTableBuilder builder)
{
builder.ShardingProperty(o => o.PublishTime);
builder.ShardingExtraProperty(o => o.Id);
}
public override bool AutoCreateTableByTime()
{
return true;
}
public override DateTime GetBeginTime()
{
return new DateTime(2022, 3, 1);
}
public override IEntityQueryConfiguration CreateEntityQueryConfiguration()
{
return new ArticleEntityQueryConfiguration();
}
public override Expression> GetExtraRouteFilter(object shardingKey, ShardingOperatorEnum shardingOperator, string shardingPropertyName)
{
switch (shardingPropertyName)
{
case nameof(Article.Id): return GetArticleIdRouteFilter(shardingKey, shardingOperator);
}
return base.GetExtraRouteFilter(shardingKey, shardingOperator, shardingPropertyName);
}
///
/// 文章id的路由
///
///
///
/// > GetArticleIdRouteFilter(object shardingKey,
ShardingOperatorEnum shardingOperator)
{
//将分表字段转成订单编号
var id = shardingKey?.ToString() ?? string.Empty;
//判断订单编号是否是我们符合的格式
if (!CheckArticleId(id, out var orderTime))
{
//如果格式不一样就直接返回false那么本次查询因为是and链接的所以本次查询不会经过任何路由,可以有效的防止恶意攻击
return tail => false;
}
//当前时间的tail
var currentTail = TimeFormatToTail(orderTime);
//因为是按月分表所以获取下个月的时间判断id是否是在临界点创建的
//var nextMonthFirstDay = ShardingCoreHelper.GetNextMonthFirstDay(DateTime.Now);//这个是错误的
var nextMonthFirstDay = ShardingCoreHelper.GetNextMonthFirstDay(orderTime);
if (orderTime.AddSeconds(10) > nextMonthFirstDay)
{
var nextTail = TimeFormatToTail(nextMonthFirstDay);
return DoArticleIdFilter(shardingOperator, orderTime, currentTail, nextTail);
}
//因为是按月分表所以获取这个月月初的时间判断id是否是在临界点创建的
//if (orderTime.AddSeconds(-10) > DoArticleIdFilter(ShardingOperatorEnum shardingOperator, DateTime shardingKey, string minTail, string maxTail)
{
switch (shardingOperator)
{
case ShardingOperatorEnum.GreaterThan:
case ShardingOperatorEnum.GreaterThanOrEqual:
{
return tail => String.Compare(tail, minTail, StringComparison.Ordinal) >= 0;
}
case ShardingOperatorEnum.LessThan:
{
var currentMonth = ShardingCoreHelper.GetCurrentMonthFirstDay(shardingKey);
//处于临界值 o=>o.time String.Compare(tail, maxTail, StringComparison.Ordinal) String.Compare(tail, maxTail, StringComparison.Ordinal) String.Compare(tail, maxTail, StringComparison.Ordinal) tail == minTail;
}
else
{
return tail => tail == minTail || tail == maxTail;
}
}
default:
{
return tail => true;
}
}
}
private bool CheckArticleId(string orderNo, out DateTime orderTime)
{
//yyyyMMddHHmmss
if (orderNo.Length == 14)
{
if (DateTime.TryParseExact(orderNo, "yyyyMMddHHmmss", CultureInfo.InvariantCulture,
DateTimeStyles.None, out var parseDateTime))
{
orderTime = parseDateTime;
return true;
}
}
orderTime = DateTime.MinValue;
return false;
}
} 完整路由:针对Id进行多字段分片并且支持大于小于排序
以上是多字段分片的优化,详情博客可以点击这边 .Net下你不得不看的分表分库解决方案-多字段分片
然后我们继续查询看看结果
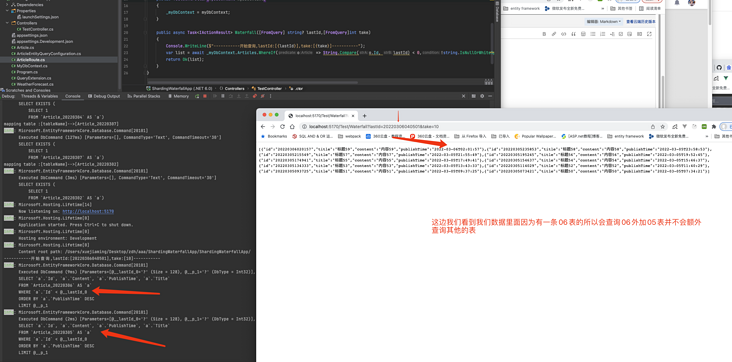
第三页也是如此
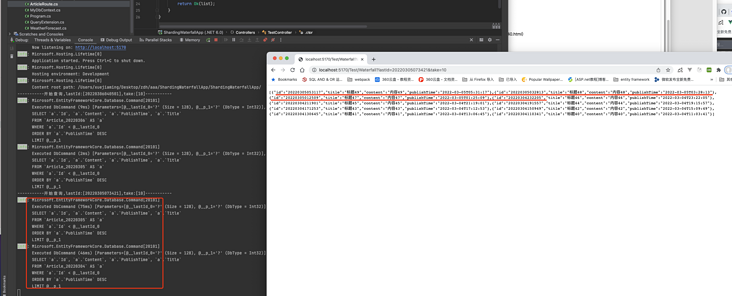
demo
总结
当前框架虽然是一个很年轻的框架,但是我相信我对其在分片领域的性能优化应该在.net现有的所有框架下找不出第二个,并且框架整个也支持union all聚合,可以满足列入group+first的特殊语句的查询,又有很高的性能,一个不但是全自动分片而且还是高性能框架拥有非常多的特性性能,目标是榨干客户端分片的最后一点性能。
MAKE DOTNET GREAT AGAIN
最后的最后
身位一个dotnet程序员我相信在之前我们的分片选择方案除了
mycat和
shardingsphere-proxy外没有一个很好的分片选择,但是我相信通过
ShardingCore的原理解析,你不但可以了解到大数据下分片的知识点,更加可以参与到其中或者自行实现一个,我相信只有了解了分片的原理dotnet才会有更好的人才和未来,我们不但需要优雅的封装,更需要原理的是对原理了解。
我相信未来dotnet的生态会慢慢起来配上这近乎完美的语法
您的支持是开源作者能坚持下去的最大动力
- Github ShardingCore
Gitee ShardingCore
QQ群:771630778
个人QQ:326308290(欢迎技术支持提供您宝贵的意见)
个人邮箱:326308290@qq.com
终于介绍完啦!小伙伴们,这篇关于《.Net/C#分库分表高性能O(1)瀑布流分页》的介绍应该让你收获多多了吧!欢迎大家收藏或分享给更多需要学习的朋友吧~golang学习网公众号也会发布数据库相关知识,快来关注吧!
声明:本文转载于:SegmentFault 如有侵犯,请联系study_golang@163.com删除
相关阅读
更多>
-
374 收藏
-
398 收藏
-
499 收藏
-
384 收藏
-
240 收藏
最新阅读
更多>
课程推荐
更多>
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习