利用go实现mysql批量测试数据生成-TDG
来源:SegmentFault
时间:2023-02-20 11:47:09 259浏览 收藏
来到golang学习网的大家,相信都是编程学习爱好者,希望在这里学习数据库相关编程知识。下面本篇文章就来带大家聊聊《利用go实现mysql批量测试数据生成-TDG》,介绍一下MySQL、go、批量插入,希望对大家的知识积累有所帮助,助力实战开发!
利用go实现mysql批量测试数据生成-TDG
组件代码:https://gitee.com/dn-jinmin/tdg
下载
insert into table_name (col1,col2)values(data1, data2)
如果存在一份 xxx.sql 的文件可以通过
source xxx.sql
还可以采用mysql中的
load data xxx xxx.txt
针对mysql如何快速批量生成测试数据需要解决的几个问题
- 如何快速生成?
- 如何针对表生成
- 需要针对不同字段要求生成数据
- 可自定义对不同的表去生成
这是针对mysql如何高效的生成测试数据必须要考虑并要解决的问题,我的思考过程...(因为篇幅太长此处省略....N..字)
tdg实现思路
首先在整体的思路上是基于sql,通过insert的方式写入的策略实现的;利用insert语句批量新增的方式;如下格式
insert into table_name (col1,col2) values(data1, data2),(data1,data2)
tdg对于SQL的生成分为三块
1. SQL开始与table_name
insert into table_name
2. 字段列
(col1, col2)
3. 写入数据
values(data1, data2),(data1, data2)
tdg则就是针对SQL的生成与拼接组装最终构建一条批量新增的insert语句,将生成的数据写入到mysql中;
03. 具体实现
在整体的实现中可以分为四个节点:初始化、数据生成规则、SQL生成、SQL写入
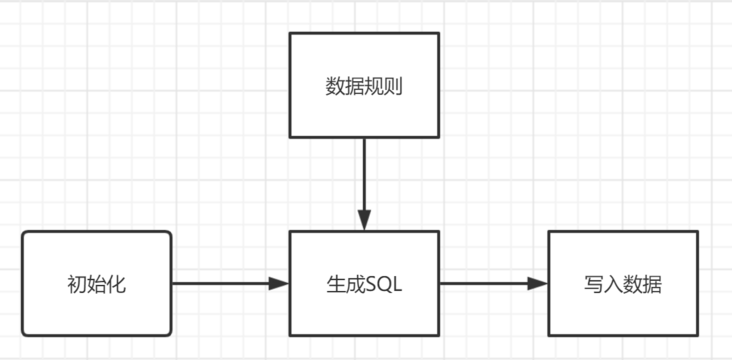
数据生成规则
这里我们先了解一下规则是如何实现的,因为考虑到在mysql中对于字段我们会因为数据的特点会有对应的要求,比如id可以是int也可以是string、order会有属于它自己的要求方式,phone,date,name等等会存在多种类型的数据要求;
因此规则的设计主要是根据列的应用所对应的类型设计会包含如下的规则
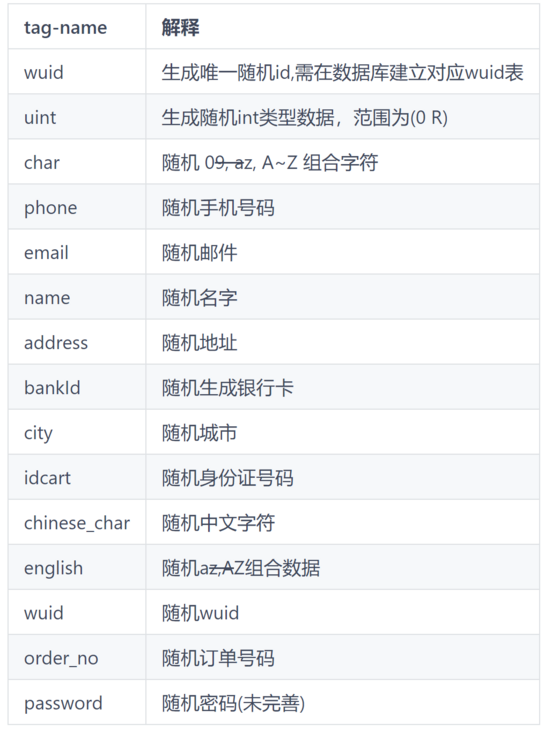
这些规则会在初始化的时候加载;整体的设计上是定义一个统一的规则接口在
type Column struct {
// 字段标签,确定字段生成方式
Tag string `json:"tag"`
// 字段固定长度
Len int `json:"len"`
// 长度范围,可变长度
FixedLen interface{} `json:"fixed_len"`
// 字段最大值
Max int `json:"max"`
// 字段最小值
Min int `json:"min"`
// 其它参数
Params interface{} `json:"params"`
// 默认值
Default struct {
Value interface{} `json:"value"`
Frequency int `json:"frequency"`
} `json:"default"`
// 指定随机内容
Content []interface{} `json:"content"`
}
type Tag interface {
Name() string
Handler(column *Column) string
Desc() string
}Name() 代表是规则的标签名称,Hander具体的随机方法,Desc打印输出的描述;考虑到规则的丰富性定义一个统一的column结构体作为hander的参数,而不同规则可以根据column中的参数设置进行随机生成想要的结果; 如下为示例,
type Char struct{}
func (*Char) Name() string {
return "char"
}
func (*Char) Handler(column *Column) string {
var ret strings.Builder
chLen := column.Len
// 固定长度, 固定长度优先级大于可变长度
if column.FixedLen != nil {
chLen = column.PrepareFixedLen()
}
ret.Grow(chLen)
// 可变长度
for i := 0; i 所有的规则统一定义在
type Field map[string]Tag
func NewField(cap int) Field {
return make(map[string]Tag, cap)
}
func (field Field) Register(tag string, option Tag)
func (field Field) TagRandField(column *Column, sql *strings.Builder)规则也可以自定义哟只需要实现上面的接口,然后再利用filed的Register方法注册就好了
初始化:
在tdg中存在Table结构体代表是某一个表
type Table struct {
TableName string `json:"table_name"`
Columns map[string]*Column `json:"columns"`
Debug bool `json:"debug"`
Count int `json:"count"`
Status int `json:"status"`
columns []string
sqlPrefix *[]byte
}加载table.json配置,在配置中会定义关于MySQL的连接、table的表名、字段及整体tdg对数据生成的策略
{
"tdg": {
"data_one_init_max_memory": 104857600,
"build_sql_worker_num": 5,
"insert_sql_worker_num": 10,
"build_batches_count": 2000,
// ..
},
"mysql": {
"addr": "",
"user" : "",
"pass" : "",
"charset" : "",
"dbname": "",
"table_prefix": ""
},
"tables": {
"member": {
"status": 0,
"table_name": "member",
"count": 10,
"columns": {
"username": {
"tag": "name",
"fixed_len": "6|14"
},
//..
}
},
"member_info": {
"table_name": "member_info",
"count": 1,
"status": 0,
"columns": {
//..
}
}
}
}同时也会加载一些自定义的规则,加载后的数据信息会存最终存在build中,通过build驱动
type Build struct {
oneInitMaxMemory int
insertSqlWorkerNum int
buildSqlWorkerNum int
buildBatchesCount int
mysqlDsn string
cfg *Config
tables map[string]*Table
field Field
db *gorm.DB
wg sync.WaitGroup
}在初识的时候会对所有准备新增的表把前缀
func (b *Build) Run() {
b.buildSqlWorkerPool(sqlCh, buildTaskCh)
b.insertSqlWorkerPool(sqlCh, ctx)
for _, table := range b.tables {
go func(table *Table, ctx *Context) {
// 数据表是否写入
if table.Status == -1 {
return
}
task := &buildTask{
table: table,
quantity: b.buildBatchesCount,
sqlPrefix: table.prepareColumn(),
}
degree, feel := deg(table.Count, b.buildBatchesCount)
ctx.addDegree(degree) // 统计次数
for i := 0; i 0 && i == degree -1 {
task.quantity = feel
}
buildTaskCh 在流程的设计上是会对每个表分任务的方式去生成,一次生成多少的SQL并进行写入;通过deg计算任务,而任务信息就是buildTask通过通道buildTaskCh发送任务
同时在run中还会创建好对应insertSql与getSql的工作者数量
在getSql中会根据标签调用不同的规则生成,随机的数值并进行SQL的拼接
func (b *Build) getSql(quantity int, sqlPrefix *[]byte,table *Table, sqlCh chan *strings.Builder) {
// ..
for i := 0; i 在生成完SQL之后把结果发送到sqlch通道中;insertSql则读取并利用gorm写入
func (b *Build) insert(sql *strings.Builder, ctx *Context) {
if !b.cfg.NoWrite {
if err := b.db.Exec(sql.String()).Error; err != nil {
if b.cfg.Debug {
ctx.errs = append(ctx.errs, err)
}
if !b.cfg.TDG.SkipErr {
ctx.Cancel()
return
}
}
}
ctx.complete++
if ctx.complete == ctx.degree {
ctx.Cancel()
}
}基本实现如上
04. 总结
tdg中对于如下问题的解决
- 如何快速生成?(利用并发编程worker工作模式、构建多个getSQL与insertSql配合工作,细节可以看具体代码哟)
- 如何针对表生成(通过配置table.json指定,并且还需要指定生成的规则)
- 需要针对不同字段要求生成数据(通过定义规则的生成结构体及固定传参来提高生成规则的丰富度)
- 可自定义对不同的表去生成(同样也是table.json中可以指定,并且还可以支持多个表一起)
如果有哪儿存在问题的欢迎指点
终于介绍完啦!小伙伴们,这篇关于《利用go实现mysql批量测试数据生成-TDG》的介绍应该让你收获多多了吧!欢迎大家收藏或分享给更多需要学习的朋友吧~golang学习网公众号也会发布数据库相关知识,快来关注吧!
-
数据库 · MySQL | 9小时前 | MySQL · 数据库 · SQL · ON DUPLICATE KEY UPDATE · VALUES · 行别名 · MySQL VALUES() 弃用 ON DUPLICATE KEY UPDATE MySQL 行别名 INSERT AS new MySQL upsert INSERT SELECT117 收藏
-
数据库 · MySQL | 1天前 | MySQL · 索引 · limit · explain · sql优化 · ORDER BY · mysql order by explain limit 复合索引 filesort279 收藏
-
数据库 · MySQL | 2天前 | 并发 · MySQL · InnoDB · update · 库存扣减 · innodb MySQL 库存扣减 条件 UPDATE 防超卖 affected rows470 收藏
-
421 收藏
-
189 收藏
-
412 收藏
-
378 收藏
-
334 收藏
-
259 收藏
-
468 收藏
-
数据库 · MySQL | 2星期前 | MySQL · InnoDB · 性能排查 · 故障复盘 · 长事务 · mysql PURGE 长事务 Undo history list length 写入延迟242 收藏
-
486 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 虚幻的汉堡
- 这篇技术贴出现的刚刚好,太全面了,很好,码住,关注作者了!希望作者能多写数据库相关的文章。
- 2023-06-18 02:46:09