从零开始学Mysql - 字符集和编码(下)
来源:SegmentFault
时间:2023-01-21 12:40:21 106浏览 收藏
哈喽!今天心血来潮给大家带来了《从零开始学Mysql - 字符集和编码(下)》,想必大家应该对数据库都不陌生吧,那么阅读本文就都不会很困难,以下内容主要涉及到MySQL,若是你正在学习数据库,千万别错过这篇文章~希望能帮助到你!
从零开始学Mysql - 字符集和编码(下)
引言
这个系列的文章是根据《MySQL是怎样运行的:从根儿上理解MySQL》这本书的个人笔记总结专栏,这里十分推荐大家精读一下这本书,也是目前市面上个人所知的讲述Mysql原理的为数不多的好书之一,好了废话不多说我们下面进入正题。
上篇:从零开始学Mysql - 字符集和编码(上)
由于这个系列涉及的知识点还是挺多的,这里先根据文章的知识点汇总了一份个人思维导图:幕布地址
回顾上篇
因为上一篇和本篇编写的间隔时间比较久,这里我们先来回顾一下上一篇讲了什么内容:
在Mysql数据中,字符串的大小比较本质上是通过下面两种方式进行比较,简而言之字符串的大小比较是依赖字符集和比较规则来进行比较的。
- 将字符统一转为大写或者小写再进行二进制的比较
- 或者大小写进行不同大小的编码规则编码
简述和掌握几个比较常用的字符集:
- ASCII 字符集:收录128个字符,
- ISO 8859-1 字符集:在ASCII 字符集基础上进行扩展,共256个字符,字符集叫做latin1,也是Mysql5.7之前默认的字符集(Mysql8.0之后默认字符集为utf8mb4)
- GB2312:首先需要注意的是不仅仅只有“汉字”哦,比较特殊的是采用了变长编码规则,变长编码规则值得是根据字符串的内容进行不同的字符集进行编码,比如'啊A'中‘啊’使用两个字节编码,'A'因为可以使用ASCII 字符集表示所以可以只使用一个字节进行编码
- GBK 字符集:对于GB2312进行字符集的扩展,其他和GB2312编码规则一致
- UTF8字符集:UTF-8规定按照1-4个字节的变长编码方式进行编码,最后UTF8和gbk一样也兼容了ASCII的字符集
提示:这里有一个思考题目那就UTF-8mb3和UTF8-mb4的字符集有什么区别?这里也隐藏了一个历史遗留问题带来的坑,如果主要使用Mysql数据库这个坑有必要仔细了解一下,在上篇的文章最后给出答案,这里不再赘述。
- 查看字符集命令:
shell> echo $LC_ALL zh_CN.UTF-8 shell> echo $LC_CTYPE shell> echo $LANG
这三个变量的优先级是:
CREATE TABLE `test` ( `id` int NOT NULL AUTO_INCREMENT COMMENT '主键', `name` varchar(255) DEFAULT NULL COMMENT '名称', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 COMMENT='测试字符集和编码';
接着我们插入一条数据:
INSERT INTO `test`.`test` (`id`, `name`) VALUES (1, '我');
最后我们可以随便执行一条sql语句进行测试,这当然不会出现任何问题,但是这里我们可以玩一点花样,比如把字符集和编码改成下面的形式,这时候你会发现你还是可以照常插入中文也可以插入任何数据,这是为什么?其实看一下Navicat对应的DLL建表语句就可以看出端倪。
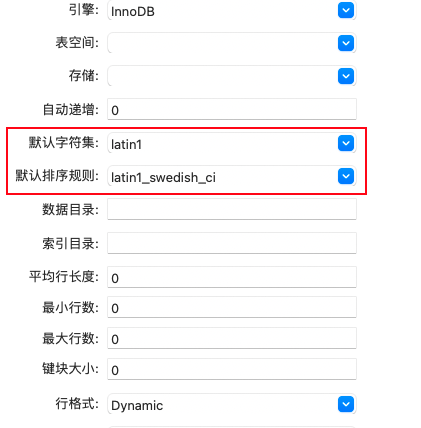
-- DDL建表语句 CREATE TABLE `test` ( `id` int NOT NULL AUTO_INCREMENT COMMENT '主键', `name` varchar(255) CHARACTER SET gbk COLLATE gbk_chinese_ci DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=latin1 COMMENT='测试字符集和编码';
可以看到如果你胡乱修改表的字符集,列的字符集会根据存储的内容选择兼容的方案,比如这里使用了gbk的编码格式进行处理。但是如果你通过下面的语句修改列的字符集,就会发现这条语句无法执行通过。
ALTER TABLE test MODIFY name VARCHAR(255) CHARACTER SET latin1 COLLATE latin1_swedish_ci; -- 报错:1366 - Incorrect string value: '\xCE\xD2\xCA\xC7' for column 'name' at row 1, Time: 0.004000s
通过上面的案例,我们可以看到navicat“偷偷”在细节做了很多操作,如果不是为了了解底层这种处理当然很方便,但是如果我们想要知道字符集的处理流程,就不得不脱离可视化工具使用命令行来操作了。
下面我们就使用命令行来看一下如何进行操作。其实关于字符集和编码的转化规则很简单,只要一个命令就可以了解,从结果可以看到居然涉及到9个变量,而且有的看起来比较相似,比如client和connection的区别是什么?另外可以从下面的内容也可以看到字符集的存储位置,由于个人使用了macos做实验,所以存储的位置就是
mysql> show variables like 'character_%'; +--------------------------+-------------------------------------------------------+ | Variable_name | Value | +--------------------------+-------------------------------------------------------+ | character_set_client | utf8mb4 | | character_set_connection | utf8mb4 | | character_set_database | utf8mb4 | | character_set_filesystem | binary | | character_set_results | utf8mb4 | | character_set_server | utf8mb4 | | character_set_system | utf8mb3 | | character_sets_dir | /usr/local/mysql-8.0.26-macos11-arm64/share/charsets/ | +--------------------------+-------------------------------------------------------+ 8 rows in set (0.00 sec)
一个请求的处理流程还是比较繁琐的,为了简化介绍我们通过画图来进行解释,我们可以直接看下图:
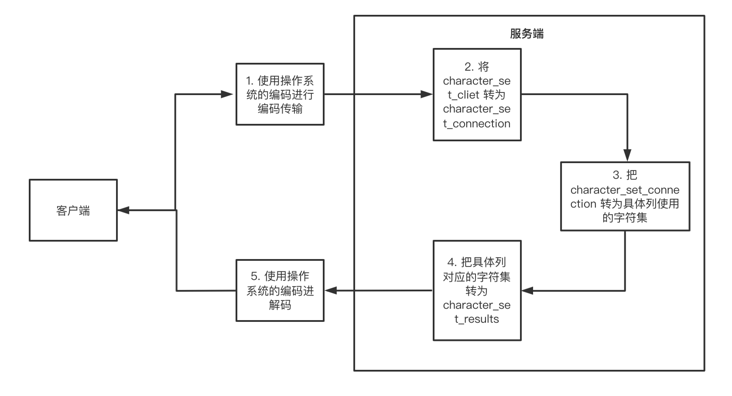
这里需要注意关于character_set_client,character_set_connection,character_set_results三个参数,这三个参数都是Session级别的,意味着每一个客户端的连接都维护了自己的一份字符集,这也是为什么设置character_set_client这一个参数的意义,另外如果Mysql不支持当前操作系统的字符集,就会把客户端的字符集设置为Mysql默认的字符集,我们可以通过下面的示例图了解到客户端的字符集转化的。
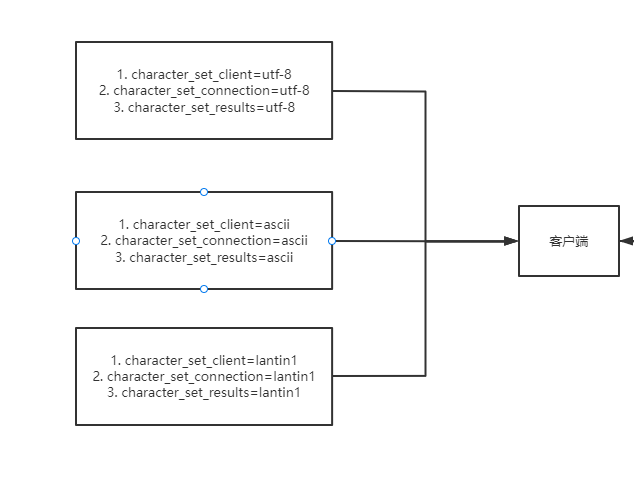
提示:Mysql5.7(包含)以及之前的版本中使用latin1作为默认字符集,Mysql8.0之后默认字符集为utf8mb4。
从上面的这个图中我们可以基本了解到下面的信息:
- 如果character_set_results 转化后的字符集和操作系统的字符集不同,那就很可能出现乱码的可能。
- 不管客户端使用的是什么样形式的编码,最终都会转化为character_set_connection,虽然character_set_connection看上去没什么用但是如果character_set_connection和character_set_client字符集不一致,有可能由于无法编码导致Mysql出现警告。
- 如果客户端使用的字符集和服务端所使用的character_set_client 字符集不一致的话,就很可能出现服务器无法理解客户端请求的情况
- 一个请求的字符集转化会在客户端和服务端交互的时候完成两次,在服务器内部完成三次的转化操作,看上去十分繁琐,所以记住三个关键参数即可。
下面我们来实验一下上面出现可能乱码的情况:
首先是最直观的也是在windows的操作系统中使用mysql最容易产生的问题,那就是我们有可能会把查询的结果内容出现乱码的情况。这里我们根据上面实验提到的表进行测试,直接通过修改results的字符集就可以看到效果:
mysql> set character_set_results=latin1; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'character_%'; +--------------------------+-------------------------------------------------------+ | Variable_name | Value | +--------------------------+-------------------------------------------------------+ | character_set_client | utf8mb4 | | character_set_connection | utf8mb4 | | character_set_database | utf8mb3 | | character_set_filesystem | binary | | character_set_results | latin1 //被修改 | | character_set_server | utf8mb4 | | character_set_system | utf8mb3 | | character_sets_dir | /usr/local/mysql-8.0.26-macos11-arm64/share/charsets/ | +--------------------------+-------------------------------------------------------+ 8 rows in set (0.00 sec) mysql> select * from test; +----+------+ | id | name | +----+------+ | 1 | ?? | | 2 | ? | +----+------+ 2 rows in set (0.00 sec)
接下来 我们来尝试一下如果character_set_client和character_set_connection不一样会有什么问题,
mysql> show variables like 'character_%'; +--------------------------+-------------------------------------------------------+ | Variable_name | Value | +--------------------------+-------------------------------------------------------+ | character_set_client | latin1 | | character_set_connection | ascii | | character_set_database | utf8mb3 | | character_set_filesystem | binary | | character_set_results | latin1 | | character_set_server | utf8mb4 | | character_set_system | utf8mb3 | | character_sets_dir | /usr/local/mysql-8.0.26-macos11-arm64/share/charsets/ | +--------------------------+-------------------------------------------------------+ 8 rows in set (0.01 sec) mysql> set character_set_client=utf8mb4; Query OK, 0 rows affected (0.00 sec) mysql> select * from test; +----+------+ | id | name | +----+------+ | 1 | ?? | | 2 | ? | +----+------+ 2 rows in set (0.00 sec) mysql> select * from test where name= '我'; Empty set, 1 warning (0.01 sec) //==========注意关键点在这=========== mysql> show warnings; +---------+------+------------------------------------------------------------+ | Level | Code | Message | +---------+------+------------------------------------------------------------+ | Warning | 1300 | Cannot convert string '\xE6\x88\x91' from utf8mb4 to ascii | +---------+------+------------------------------------------------------------+ 1 row in set (0.00 sec)
我们把client设置为latin1,把connection设置为ascii,从报错可以看到虽然我们进行基本查询的时候没啥问题,但是一旦向服务器传输字符集设置有汉字就会出现报错了,所以在设置mysql的这三个参数的配置的时候,一定要把他们配置为同一个字符集,否则这个错误可能并不是那么容易发现。(当然这个案例还是很容易发现问题)
最后我们来试一下如何让服务端无法理解客户端的请求,其实也比较简单,就是让服务端采用的字符集范围比客户端使用的字符集范围小就可以了,比如把客户端设置为uft8,服务端设置为ascii,下面我们同样进行试验,为了不让代码过多,这里省去了修改字符集的其他命令后直接查看结果,这串英文告诉我们的是这两个字符集无法比较,也就出现前面说的服务端无法理解客户端请求的情况下:
mysql> select * from test where name ='我'; ERROR 1267 (HY000): Illegal mix of collations (gbk_chinese_ci,IMPLICIT) and (ascii_general_ci,COERCIBLE) for operation '='
将上面的内容实验完成之后,这时候我们会想要怎么把字符集修改回来,可以发现我们基本上主要使用的字符集也就 character_set_client、character_set_connection、character_set_results,这三个字符集兜兜转转一个个改实在是麻烦,Mysql也考虑到了这个问题,所以同样提供了一个快捷操作的命令:
SET character_set_client = 字符集名; SET character_set_connection = 字符集名; SET character_set_results = 字符集名; // 等同于 set name 字符集
在个人事迹操作的时候发生了一个比较有意思的事,在设置字符集的时候mysql给了提示说后续会在设置utf8字符集的时候默认把字符集改为;utf8mb4。
mysql> set names utf8; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> show warnings; +---------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Level | Code | Message | +---------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Warning | 3719 | 'utf8' is currently an alias for the character set UTF8MB3, but will be an alias for UTF8MB4 in a future release. Please consider using UTF8MB4 in order to be unambiguous. | +---------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) mysql> set character_set_client=utf8 -> ; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> show warnings; +---------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Level | Code | Message | +---------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Warning | 3719 | 'utf8' is currently an alias for the character set UTF8MB3, but will be an alias for UTF8MB4 in a future release. Please consider using UTF8MB4 in order to be unambiguous. | +---------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) 另外还有一种方法是在配置文件里面进行配置,当然这是针对整个服务端启动的配置参数了,一般还是建议显示配置一下,以免不必要的麻烦:
[client] default-character-set=utf8
啰嗦了这么多内容,其实可以一句话进行总结:我们通常都把 character_set_client、character_set_connection、character_set_results 这三个系统变量设置成和客户端使用的字符集一致的情况,这样减少了很多无谓的字符集转换。就是这么简单,只要这样设置就没有那么多奇怪的字符集和比较规则的问题。
比较规则的影响
说完了字符集下面说说比较规则,,之前说过字符集影响了字符串的的内容显示,那么比较规则则是影响了字符的比较操作,而比较这一操作则影响了字符串的比较和排序操作,为了说明对于比较规则的影响,这里我们同样用一个简单的案例来理解并进行介绍:
补充:比较规则的设计要比字符集的设置要直观一些,分为三个变量 collation_connection,collation_database,collation_server,见名知义,可以分为连连接级别,数据库级别和server服务器级别,关于比较规则使用规律在 从零开始学Mysql - 字符集和编码(上) 进行了讨论,这里就不展开了:
mysql> show variables like 'collation_%';
+----------------------+--------------------+
| Variable_name | Value |
+----------------------+--------------------+
| collation_connection | utf8_general_ci |
| collation_database | utf8_general_ci |
| collation_server | utf8mb4_0900_ai_ci |
+----------------------+--------------------+ 根据前文的表我们先插入几条随机数据:
INSERT INTO `test`.`test` (`id`, `name`) VALUES (1, '我是'); INSERT INTO `test`.`test` (`id`, `name`) VALUES (2, '我'); INSERT INTO `test`.`test` (`id`, `name`) VALUES (3, '我'); INSERT INTO `test`.`test` (`id`, `name`) VALUES (4, 'ABCD'); INSERT INTO `test`.`test` (`id`, `name`) VALUES (5, 'A'); INSERT INTO `test`.`test` (`id`, `name`) VALUES (6, 'a'); INSERT INTO `test`.`test` (`id`, `name`) VALUES (7, 'B'); INSERT INTO `test`.`test` (`id`, `name`) VALUES (8, 'c');
接着我们按照名称的顺序查询一下排序,这里在执行之前可以先查看一下当前的比较规则:
mysql> show variables like 'collation_%'; +----------------------+--------------------+ | Variable_name | Value | +----------------------+--------------------+ | collation_connection | utf8_general_ci | | collation_database | utf8_general_ci | | collation_server | utf8mb4_0900_ai_ci | +----------------------+--------------------+ 8 rows in set (0.01 sec) > select * from test order by name desc; 1 我是 2 我 3 我 8 c 7 B 4 ABCD 5 A 6 a
最后我们可以尝试把字符集改为其他的字符集再看一下排序的结果,可以看到排序的结果发生了改变:
备注: gbk_bin 是直接比较字符的编码,所以是区分大小写的
ALTER TABLE test MODIFY name VARCHAR(255) COLLATE gbk_bin; 1 我是 2 我 3 我 8 c 6 a 7 B 4 ABCD 5 A
这一点还是比较好理解的,不同的字符集比较规则是不一样的,但是如果是下面的比较操作,Mysql又是如何区分的呢?
select 'a' = 'A'
这个结果倒是对还是错,其实要看两个参数,第一个参数是:character_set_connection,他负责规定客户端传输到服务端实际需要转化的字符集,另一个参数是collaction_connection,他负责设置当前字符集的比较规则,所以可以通过改变这两个值改变上面的查询结果,这里也可以根据上面的实验尝试修改,这里就不进行演示,所以这个结果有可能是1,也有可能是0(这不是废话么!)。
另外还有一种情况是如果character_set_connection的字符集是gbk,而某一个表的数据列使用的字符集和比较规则是utf8的,这时候要以谁为准?这里也有一个硬性规定:默认以Mysql列所指定的字符集的规则为主,这也意味着如果以utf8进行比较,会先进行一次转化把gbk转为utf8之后在进行比较,当然一般也没人闲着没事某个列的字符集,这里仅仅作为一个小知识即可,记不住也没关系,等实际踩坑的时候在数据列和系统的字符集上留个心眼就好了。
总结
最后再总结一波,通过本文我们了解到一个字符串本身是通过字符集进行编码的,使用的是本文主要了解了一个请求是如何经过mysql处理的,他的处理过程如下:
- 请求先通过客户端的字符集转为character_set_client的字符集解码,然后通过将字符串通过 character_set_connection 的格式进行编码。
- 如果character_set_client和character_set_connection一致,则进行下一步操作,否则的话会尝试将请求中的字符串从 character_set_connection的字符集转换为具体操作的列 使用的字符集,如果转为操作列的字符集操作还是失败,则可能会拒绝处理的情况。
- 把某列的字符集转为character_set_results的字符集编码结果,同时发送给客户端,如果此时客户端和results的编码集不一致,那么就会出现乱码的情况。
- 客户端最终使用操作系统的字符集解析收到的结果集字节串。
而对于比较规则细节比较少,只要记住比较规则会影响内容的排序即可,如果某一次查询的排序结果和预期不符合,那么这时候可以从排序规则入手看一下是否可以通过排序规则调整可以更好的符合预期结果。
写在最后
Mysql的数据关于字符集的内容细节还是比较多的,个人也认为字符集的转化确实有点绕,所以这一块的知识点需要多回顾才行。
今天关于《从零开始学Mysql - 字符集和编码(下)》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!
-
374 收藏
-
499 收藏
-
384 收藏
-
184 收藏
-
265 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 等待的大侠
- 太细致了,收藏了,感谢大佬的这篇文章,我会继续支持!
- 2023-06-20 17:37:01
-
- 狂野的砖头
- 这篇文章真是及时雨啊,太详细了,受益颇多,码住,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-05-21 19:54:51
-
- 冷傲的钢笔
- 很棒,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢大佬分享文章内容!
- 2023-05-09 14:27:24
-
- 虚幻的樱桃
- 这篇技术文章出现的刚刚好,太全面了,很有用,mark,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-05-05 02:06:53
-
- 瘦瘦的香菇
- 真优秀,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢博主分享文章内容!
- 2023-04-19 10:30:51
-
- 鲤鱼龙猫
- 很详细,收藏了,感谢大佬的这篇技术贴,我会继续支持!
- 2023-04-04 21:20:45
-
- 美好的帆布鞋
- 这篇文章内容出现的刚刚好,好细啊,感谢大佬分享,码起来,关注作者了!希望作者能多写数据库相关的文章。
- 2023-02-27 12:32:40
-
- 朴实的棒球
- 真优秀,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢作者大大分享文章!
- 2023-02-23 08:38:25
-
- 玩命的钢笔
- 很棒,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢博主分享文章内容!
- 2023-02-22 06:44:45
-
- 雪白的雪糕
- 这篇技术贴出现的刚刚好,太详细了,很有用,收藏了,关注作者大大了!希望作者大大能多写数据库相关的文章。
- 2023-02-21 08:20:59
-
- 矮小的大雁
- 细节满满,mark,感谢楼主的这篇文章,我会继续支持!
- 2023-01-25 08:41:13