存储空间降为 MySQL 的十分之一,TDengine 在货拉拉数据库监控场景的应用
来源:SegmentFault
时间:2023-01-14 11:37:06 300浏览 收藏
IT行业相对于一般传统行业,发展更新速度更快,一旦停止了学习,很快就会被行业所淘汰。所以我们需要踏踏实实的不断学习,精进自己的技术,尤其是初学者。今天golang学习网给大家整理了《存储空间降为 MySQL 的十分之一,TDengine 在货拉拉数据库监控场景的应用》,聊聊MySQL、数据库、tdengine、物联网,我们一起来看看吧!
小 T 导读: 作为一家业务遍及多个国家及地区的物流公司,货拉拉面临的技术环境是非常复杂的,在云时代浪潮下基于混合云快速构建环境搭建系统成为其必然的选择。但是在混合云上如何对基于各家云构建的系统进行有效的管理是个挑战,尤其对处于系统最底层的数据库层面临的问题、业务诉求、各方痛点,是货拉拉 DBA 团队现下所需要重点解决的。

目前 DBA 团队管理的数据存储包括 MySQL、Redis、Elasticsearch、Kafka、MQ、Canal 等,为了保证监控采样的实时性,我们自研的监控系统设置的采样间隔为 10 秒,这样每天都会产生庞大的监控数据,监控指标的数据量达到 20 亿+。前期由于管理实例少,监控数据量也少,所有数据都被存放到了 MySQL 中;之后随着管理实例越来越多,使用 MySQL 来存储规模日益庞大的监控数据越发力不从心,急需进行升级改造。结合实际具体需求,通过对不同时序数据库进行调研,最终我们选择了 TDengine,顺利完成了数据存储监控的升级改造。
一、监控系统开发中遇到的问题
从存储路径来看,每种数据存储都分布在多个区域,每个区域将监控采样数据投递上报到消息总线,然后由消费程序统⼀消费,消费程序会将必要的告警数据更新到告警表,同时将监控原始数据存储到 MySQL。比如,针对 Redis 这款数据存储,监控采样间隔设置 10 秒,那么每天实例采样次数就会达到 3000 万+,监控指标累计 6 亿+,数据量之庞大可见一斑。早期为了将数据存储到 MySQL 中,同时也能很好地支持监控绘图的使用,每⼀次实例监控采样时都会计算出该实例全量监控项采样数据,然后将本次采样的结果作为⼀条记录存储下来。
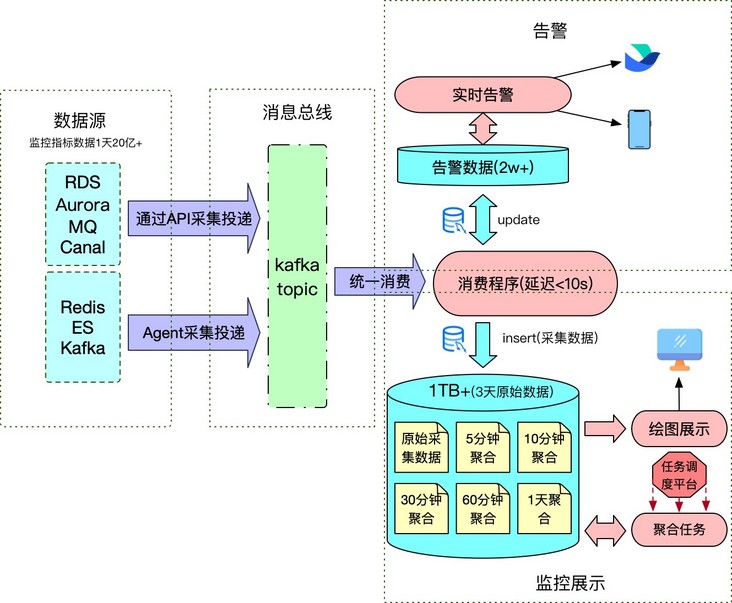
即使通过这样的优化处理,在做时间跨度大的监控绘图时,前端依然会出现延迟卡顿的问题,后端监控数据存储的 MySQL 也压力山大,经常满载,天天被吐槽。因此针对这种时间跨度大的查询,我们专门开发了⼀系列的数据聚合调度任务——按照不同的时间跨度,提前将 10 秒采集间隔的监控数据做好聚合,监控绘图程序再根据不同的时间跨度选取不同的聚合数据表绘图,以此解决长时间跨度监控绘图展示延迟卡顿的问题。
但这仍然治标不治本。为了压缩监控数据存储空间,原始 10 秒间隔的监控数据表只能归档保留 3 天时间的监控数据,但存储大小也将近有 200GB, 加上与之相关的不同时间段的数据聚合表,存储一下子突破 300GB。这还只是 Redis 监控数据的存储大小,加上其它数据存储的监控数据,至少需要 1TB+空间的 MySQL 存储。
数据集合任务管理复杂、后期监控原数据回溯缺失、MySQL 存储空间日益增长带来的隐患,都是亟待解决的问题。
二、时序数据库选型
为了解决 MySQL 监控数据存储的问题,我们把注意力转移到了适合存储监控数据的时序数据库上。市面上各种时序数据库产品琳琅满目,有老牌的,也有后起之秀,经过⼀系列调研选型,我们选择了 TDengine,主要是因为其具备的如下几大优点:
- 采用分布式架构,可支持线性扩展
- 数据存储压缩率超高
- 集群模式支持多副本,无单点故障
- 单机模式性能强悍
- 安装部署维护简单
- SQL⽀持时间维度聚合查询
- 客户端支持 RESTful API
值得一提的是,TDengine 的 SQL 原生语法支持时间维度聚合查询,同时数据存储压缩率⾼存储空间小,这两点直接切中了我们的痛点。落地后实测相同数据的存储空间只有 MySQL 存储空间的十分之⼀甚至更少。 还有⼀个惊喜是,在现有监控数据存储(MySQL)顶不住的情况下,⼀台 8C16GB 的单机版 TDengine 轻松就抗下目前所有监控流量和存储压力, 且运行稳定,基本没有故障。
三、改造过程
TDengine 用于存储监控数据的超级表设计原则就是简单高效,字段⼀般都比较少,每⼀种监控项类型(INT、FLOAT、NCHAR 等)的数据存储都需要单独建立⼀个超级表,超级表⼀般都有关键的 ts、type、value 字段,具体监控项由 type 字段标识,加上必要的 tag 及少量其它字段构成。
之前监控数据存储在 MySQL 的时候,每条数据记录包含了该实例⼀次监控采样的所有监控项(25+)数据。如果采用通用的监控超级表设计原则,就需要改造采样的数据结构,改造方式有两种:
- 改造监控数据投递的数据结构
- 改造消费程序消费逻辑重组数据结构
但消费端有时效性要求,改造难度大,生产端涉及范围大阻力也不小。经过综合考量,最后我们决定采用类似 MySQL 数据存储的表结构来设计超级表,这样的改造对原来系统入侵最少,改造难度系数最低, 改造大致过程如下:
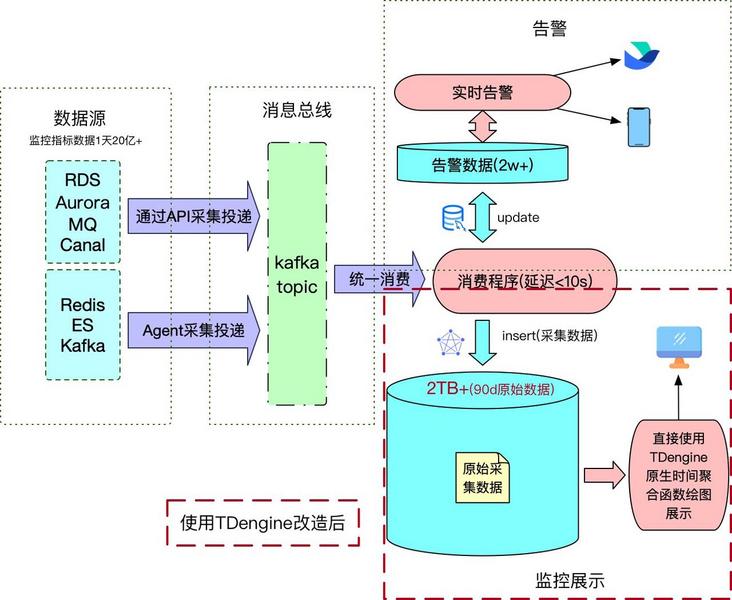
TDengine,每种数据存储的监控数据单独建库存放
taos> create database redis; taos> create database es; ... ... ...
TDengine,建超级表,以 Redis 为例
taos> use redis; taos> create table redis_node_meters (created_at TIMESTAMP, qps INT, . ..) TAGS (region NCHAR(10), cluster_name NCHAR(50), ip NCHAR(20), port INT, role NCHAR(15));
监控数据消费,由于新增的实例节点是不确定的,比如 Redis 的节点资源是由 Agent 自动发现注册后自动进行监控指标采集,这时写入数据并不确定某个子表是否存在,就需要 TDengine 的自动建表语法来创建不存在的子表,若该子表已存在则不会建立新表只会写入数据。
taos > INSERT INTO tablename USING redis_node_meters TAGS ('China', 't est', '127.0.0.3', 9200, 'master') VALUES ('2021-12-02 14:21:14', 6490 , ...)- 绘图展示,绘图程序没有安装客户端驱动,直接使用了 TDengine 提供的 RESTful API,采用 HTTP 的方式进行数据查询。在 SQL 查询上大量使用了 TDengine 提供的时间维度聚合函数 INTERVAL,长时间跨度的数据查询,只需要合理选择聚合间隔,基本都是毫秒级响应, 保障了前端绘图的流畅稳定。
四、改造后的落地效果
将监控的数据存储由 MySQL 改造为 TDengine 后,不仅顶住了监控数据增长所带来的压力,还节约了存储空间,成本压缩到了原来的十分之⼀甚至更低。历史原生监控数据可回溯时间也变得更长,之前存储 3 天原生数据及聚合数据的空间,现在可供原始数据存储 45 天。
此外,改造之后不再需要维护复杂的数据聚合调度任务,大幅降低了监控系统、监控数据管理复杂度,同时前端绘图数据查询也变得更加简洁高效。
五、写在最后
随着对 TDengine 越发深入的了解及经验累积,后续我们也会逐步考虑将货拉拉大监控系统、业务数据(行车轨迹)等时序数据均迁移至 TDengine。为了方便有需要的朋友更好地使用 TDengine,在此也分享一下我们的一些使用经验:
- 由于 TDengine 不支持太复杂的 SQL 查询语法,在设计超级表 tag 的时候需要充分考虑清楚,目前只有 tag 的字段支持函数运算结果的分组(GROUP BY)查询,普通字段是不支持的。
- 子表 tag 的值是可以改变的,但是同⼀个子表 tag 的值是唯⼀的,建议用子表 tag 的组合值来生成子表名。
在本次项目中,TDengine 很好地帮助我们实现了降本增效,是一款值得尝试的时序数据库产品,未来也希望其能够发挥出越来越丰富的功能和特性,也期待我们之后能有更紧密深入的合作。
⬇️点击下方图片查看活动详情,iPhone 13 Pro 等你带回家!
本篇关于《存储空间降为 MySQL 的十分之一,TDengine 在货拉拉数据库监控场景的应用》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于数据库的相关知识,请关注golang学习网公众号!
-
374 收藏
-
398 收藏
-
499 收藏
-
384 收藏
-
184 收藏
-
数据库 · MySQL | 2天前 | MySQL · 权限管理 · 备份 · mysqldump · 数据库安全 · 最小权限 mysqldump备份账号 MySQL角色 partial_revokes 备份权限413 收藏
-
278 收藏
-
数据库 · MySQL | 3天前 | MySQL · JSON · 索引 · 数据库 · 查询优化 · 生成列 · json_extract 索引优化 列表筛选 生成列 MySQL JSON JSON索引351 收藏
-
数据库 · MySQL | 4天前 | MySQL · 认证 · MySQL 8.4 · 数据库升级 · caching_sha2_password mysql_native_password 账号认证 MySQL 8.4 升级迁移236 收藏
-
471 收藏
-
数据库 · MySQL | 6天前 | MySQL · 数据库 · SQL · ON DUPLICATE KEY UPDATE · VALUES · 行别名 · MySQL VALUES() 弃用 ON DUPLICATE KEY UPDATE MySQL 行别名 INSERT AS new MySQL upsert INSERT SELECT117 收藏
-
数据库 · MySQL | 1星期前 | MySQL · 索引 · limit · explain · sql优化 · ORDER BY · mysql order by explain limit 复合索引 filesort279 收藏
-
数据库 · MySQL | 1星期前 | 并发 · MySQL · InnoDB · update · 库存扣减 · innodb MySQL 库存扣减 条件 UPDATE 防超卖 affected rows470 收藏
-
421 收藏
-
189 收藏
-
412 收藏
-
378 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 沉静的睫毛
- 这篇技术贴真及时,很详细,很棒,收藏了,关注作者大大了!希望作者大大能多写数据库相关的文章。
- 2023-03-18 11:08:42
-
- 聪明的花卷
- 细节满满,mark,感谢师傅的这篇技术文章,我会继续支持!
- 2023-03-16 12:23:10
-
- 清脆的柠檬
- 这篇技术文章真是及时雨啊,up主加油!
- 2023-03-11 19:04:37
-
- 阔达的蓝天
- 赞 ??,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢up主分享技术贴!
- 2023-03-10 23:14:43
-
- 心灵美的季节
- 这篇文章真是及时雨啊,太全面了,太给力了,已加入收藏夹了,关注博主了!希望博主能多写数据库相关的文章。
- 2023-01-31 20:12:58
-
- 灵巧的故事
- 这篇文章真是及时雨啊,作者加油!
- 2023-01-28 09:15:21
-
- 勤劳的白猫
- 这篇博文真是及时雨啊,好细啊,受益颇多,已收藏,关注up主了!希望up主能多写数据库相关的文章。
- 2023-01-28 05:42:50
-
- 无心的黑裤
- 受益颇多,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢大佬分享技术贴!
- 2023-01-23 08:59:25
-
- 知性的酸奶
- 太细致了,已收藏,感谢师傅的这篇技术贴,我会继续支持!
- 2023-01-19 05:11:37