精读《15 大 LOD 表达式 - 下》
来源:SegmentFault
时间:2023-02-16 15:37:09 143浏览 收藏
在IT行业这个发展更新速度很快的行业,只有不停止的学习,才不会被行业所淘汰。如果你是数据库学习者,那么本文《精读《15 大 LOD 表达式 - 下》》就很适合你!本篇内容主要包括精读《15 大 LOD 表达式 - 下》,希望对大家的知识积累有所帮助,助力实战开发!
接着上一篇 精读《15 大 LOD 表达式 - 上》 ,这次继续总结 Top 15 LOD Expressions 这篇文章的 9~15 场景。
9. 某时间段内最后一天的值
如何实现股票平均每日收盘价与当月最后一天收盘价的对比趋势图?
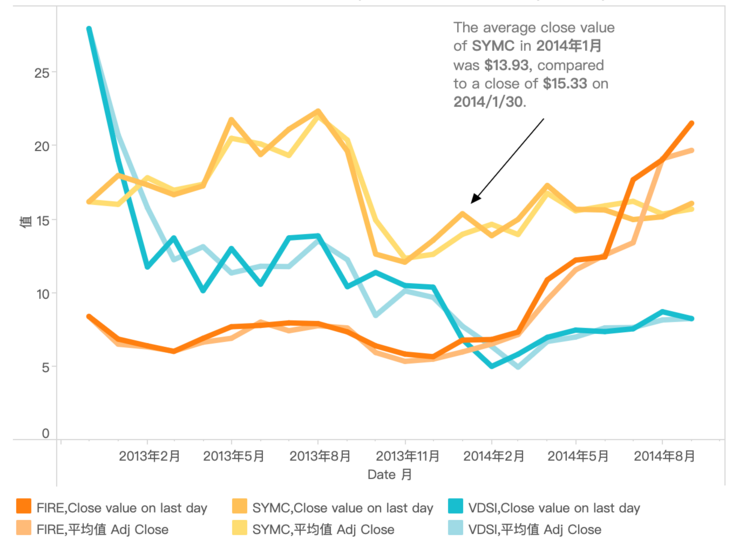
如图所示,要对比的并非是某个时间段,而是当月最后一天的收盘价,因此必须要借助 LOD 表达式。
设想原表如下:
| Date | Ticker | Adj Close |
|---|---|---|
| 29/08/2013 | SYMC | $1 |
| 28/08/2013 | SYMC | $2 |
| 27/08/2013 | SYMC | $3 |
我们按照月进行聚合作为横轴,求
avg([Adj Close])作为纵轴即可。但计算对比我们需要一个 Max Date 字段如下:
| Date | Ticker | Adj Close | Max, Date |
|---|---|---|---|
| 29/08/2013 | SYMC | $1 | 29/08/2013 |
| 28/08/2013 | SYMC | $2 | 29/08/2013 |
| 27/08/2013 | SYMC | $3 | 29/08/2013 |
如果我们使用
max(Date)表达式,在聚合后结果是可以看到 Max Date 的:
| Month of Date | Ticker | Avg, Adj Close | Max, Date |
|---|---|---|---|
| 08/2013 | SYMC | $2 | 29/08/2013 |
原因是,
max(Date)是一个聚合表达式,只能在 group by 聚合 sql 下生效。但如果我们要计算最后一天的收盘价,就要执行
sum([Close value on last day],表达式如下:
[Close value on last day] = if [Max Date] = [Date] then [Adj Close] else 0 end。
但问题是,这个表达式计算的明细级别是以天为粒度的,我们
max(Date)在天粒度下是算不出来的:
| Date | Ticker | Adj Close | Max, Date |
|---|---|---|---|
| 29/08/2013 | SYMC | $1 | |
| 28/08/2013 | SYMC | $2 | |
| 27/08/2013 | SYMC | $3 |
原因就是上面说过的,聚合表达式不能在非聚合的明细级别中出现。因此我们利用
{ include : max([Date]) } 表达式就能轻松实现下面的效果了:| Date | Ticker | Adj Close | { include : max([Date]) } |
|---|---|---|---|
| 29/08/2013 | SYMC | $1 | 29/08/2013 |
| 28/08/2013 | SYMC | $2 | 29/08/2013 |
| 27/08/2013 | SYMC | $3 | 29/08/2013 |
{ include : max([Date]) } 表达式没有给定 include 参数,意味着永远以当前视图的明细级别计算,因此这个字段下推到明细表做计算时,也可以出现在明细表的每一行。接着按照上面的思路组装表达式即可。拓展一下,如果横轴我们按年进行聚合,那么对比值就是每年最后一天的收盘价。原因是
{ include : max([Date]) } 会以当前年这个粒度计算 max([Date]),自然是当年的最后一天,然后下推到明细表,整整一年 365 行数据中,
[Close value on last day]大概是这样:
| Date | Ticker | Adj Close | [Close value on last day] |
|---|---|---|---|
| 31/12/2013 | SYMC | $1 | $1 |
| 30/12/2013 | SYMC | $2 | $1 |
| ... | ... | ... | ... |
| 03/01/2013 | SYMC | $7 | $1 |
| 02/01/2013 | SYMC | $8 | $1 |
| 01/01/2013 | SYMC | $9 | $1 |
接着对比值按照
sum([Close value on last day])聚合即可。
10. 复购阵列
如下图所示,希望查看客户第一次购买到第二次购买间隔季度的复购阵列:
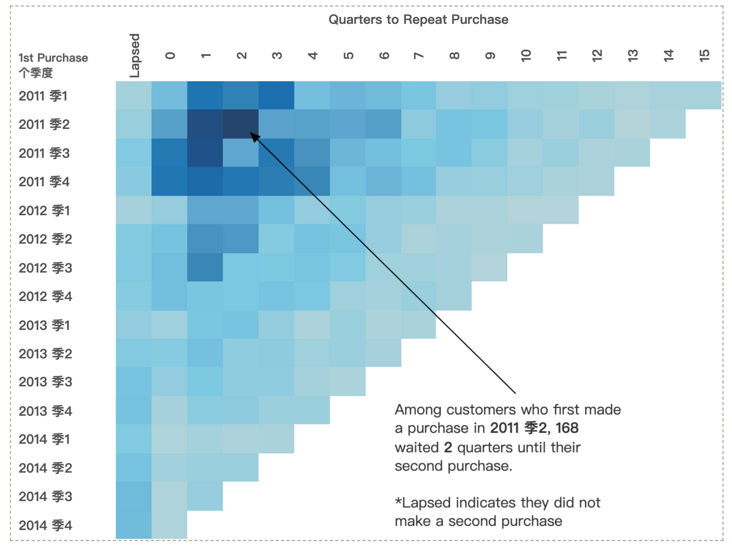
关键在于如何求第一次与第二次购买的季度时间差。首先可以通过
[1st purchase] = { fixed [customer id] : min([order date]) } 计算每位客户首次购买时间。如何计算第二次购买时间?这里有个小技巧。首先利用
[repeat purchase] = iif([order date] > [1st purchase], [order date], null)得到一个新列,首次购买的那一行值为 null,我们可以利用
min函数计算时忽略 null 的特性,得到第二次购买时间:
[2nd purchase] = { fixed [customer id] : min([repeat purchase]) }。最后利用
datediff函数得到间隔的季度数:
[quarters repeat to purchase] = datediff('quarter', [1st prechase], [2nd purchase])。11. 范围平均值差异百分比
如下图所示,我们希望将趋势图的每个点,与选定区域(图中两个虚线范围内)的均值做一个差异百分比,并生成一个新的折线图放在上方。
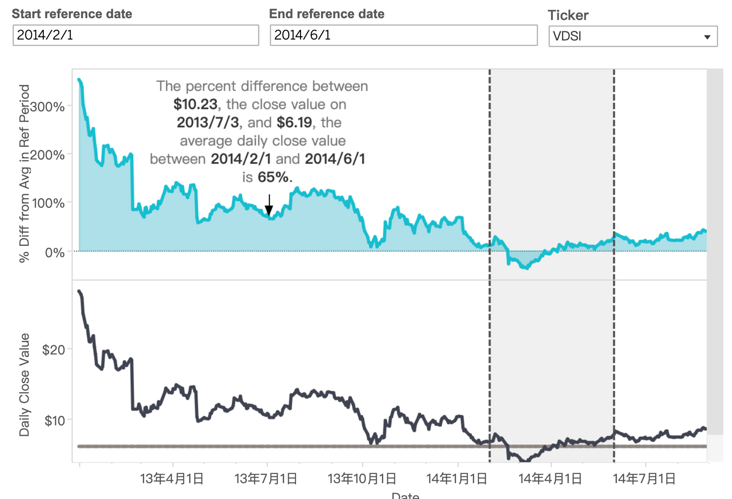
重点是上面折线图 y 轴字段,差异百分比如何表示。首先我们要生成一个只包含指定区间的收盘值:
[Close value in reference period] = IF [Date] >= [Start reference date] AND [Date] ,这段表达式只在日期在制定区间内时,才返回[Adj close],也就是只包含这个区间内的值。第二步,计算制定区间的平均值,这个用 FIX 表达式即可:
[Average daily close value between ref date] = { fixed [Ticker] : AVG([Close value in reference period]) }。第三步,计算百分比差异:
[percent different from ref period] = ([Adj close] - [Average daily close value between ref date]) / [Average daily close value between ref date]。最后就是用
[percent different from ref period]这个字段绘制上面的图形了。12. 相对周期过滤
如果我们想对比两个周期数据差异,可能会遇到数据不全导致的错误。比如今年 3 月份数据只产出到 6 号,但却和去年 3 月整月的数据进行对比,显然是不合理的。我们可以利用 LOD 表达式解决这个问题:
相对周期过滤的重点是,不能直接用日期进行对比,因为今年数据总是比去年大。比如因为今年最新数据到 11.11 号,那么去年 11.11 号之后的数据都要被过滤掉。
首先找到最新数据是哪一天,利用不包含条件的 FIX 表达式即可:
[max date] = { max([date]) }。然后利用 datepart 函数计算当前日期是今年的第几天:
[day of year of max date] = datepart('dayofyear', [max date]),[day of year of order date] = datepart('dayofyear', [order date])。所以
[day of year of max date]就是一个卡点,任何超过今年这么多天的数据都要过滤掉。因此我们创建一个过滤条件:[period filter] = [day of year of order date] 。把
[period filter]字段作为筛选条件即可。13. 用户登陆频率
如何绘制一个用户每个月登陆频率?
要计算这个指标,得用用户总活跃时间除以总登陆次数。
首先计算总活跃时间:利用 FIX 表达式计算用户最早、最晚的登陆时间:
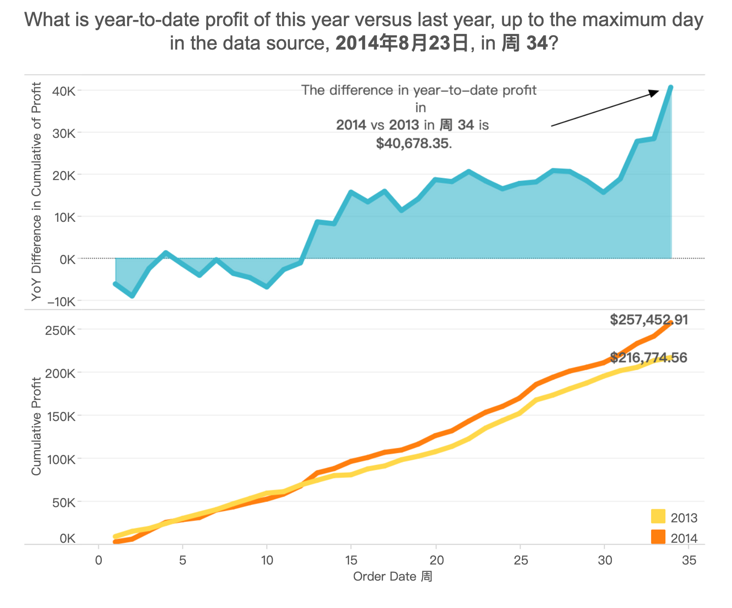
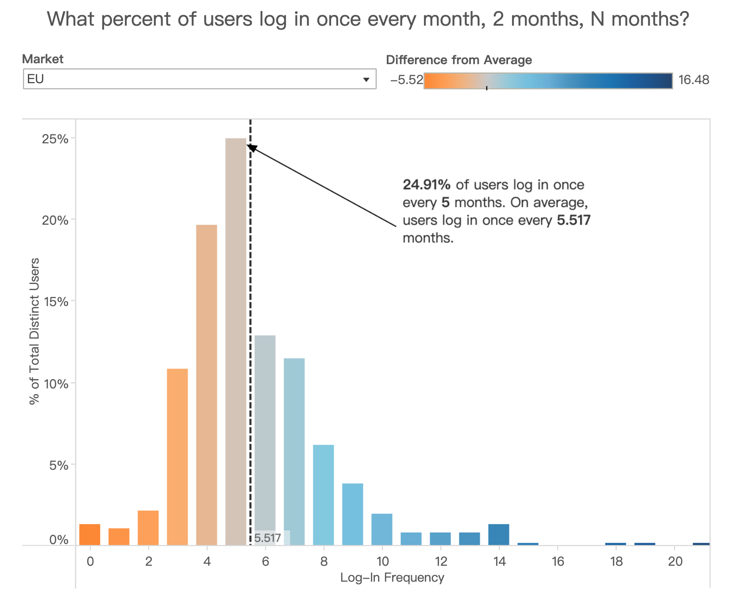
[first login] = { fixed [user id] : min([log in date]) }[last login] = { fixed [user id] : max([log in date]) }
计算其中月份 diff,就是用户活跃月数:
[total months user is active] = datediff("month", [first login], [last login])总登录次数比较简单,也是固定用户 ID 后,对登陆日期计数即可:
[numbers of logins per user] = { fixed [user id] : count([login date]) }最后,我们用两者相除,得到用户登陆频率:
[login frequency] = [total months user is active] / [numbers of logins per user]
制作图表就很简单了,把
[login frequency]移到横轴,count distinct 用户 ID 作为纵轴即可。
14. 比例笔刷
这个是 LOD 最常见的场景,比如求各品类销量占此品类总销量的贡献占比?
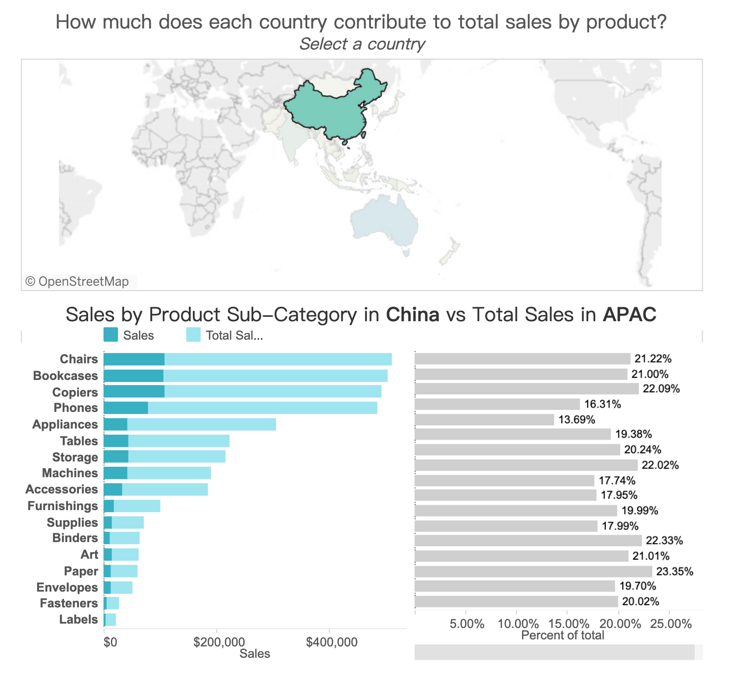
sum(sales) / sum({ fixed [category] : sum(sales) }) 即可。当前详细级别是 category + country,我们固定品类,就可以得到各品类在所有国家的累积销量。
15. 按客户群划分的年度购买频率
如何证明老客户忠诚度更高?
我们可以如下图,按照客户群(2011 年、2012 年客户)作为图例,观察他们每年购买频次分布。
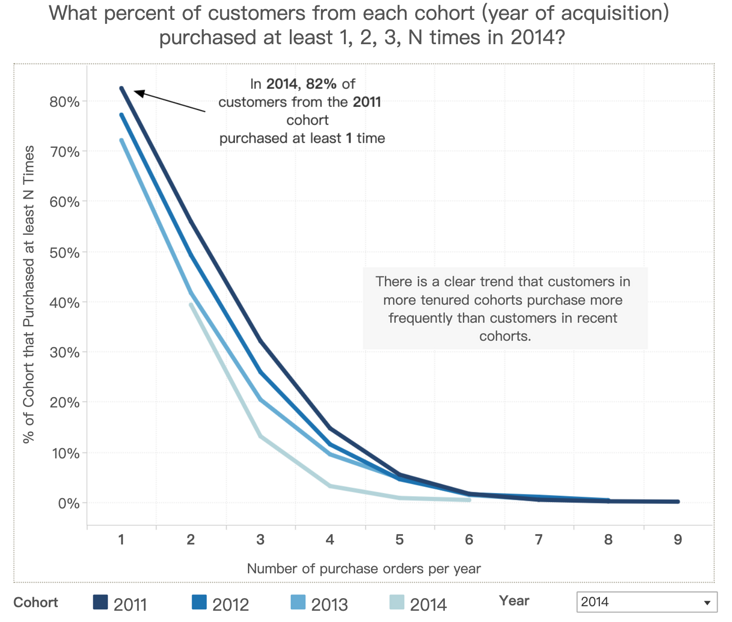
如上图所示,我们发现顾客注册时间越早,各购买频次的比例都更高,所以证明了老顾客忠诚度更高这一结论。注意这里看的是至少购买 N 次,所以每条线相比才具有说服力。如果是购买 N 次,则可能老顾客购买 1 次较少,购买 10 次较多,难以直接对比。
首先我们生成图例字段,即按最早照购买年份划分顾客群:
[Cohort] = { fixed [customer id] : min(Year([order date])) }然后就和我们第一个例子类似,计算每个订单数量下,有多少顾客。唯一的区别是,我们不仅按照顾客 ID group,还要进一步对最早购买日期做拆分,即:
{ fixed [customer id], [Cohort] : count([order id]) }。上面的字段作为 X 轴,Y 轴和第一个例子类似:
count(customer id),但我们想查看的是至少购买 N 次,也就是这个购买次数是累计值,即至少购买 9 次 = 购买 9 次 + 购买 10 次 + ... 购买 MAX 次。所以是一种 DESC 的
windowsum,整体表达式应该类似
[Running Total] = WINDOW_SUM(count(customer id)), 0, LAST())。
最后,因为实际 Y 轴计算的是占比,所以用刚才计算的至少购买 N 次指标除以各 Cohort 下总购买次数,即
[Running Total] / sum({ fixed [Cohort] : count([customer id]) })。总结
上面的几个例子,都是基于 fixed、include、exclude 这几个基本 LOD 用法的叠加。但从实际例子来看,我们会发现真正的难点不在与 LOD 表达式的语法,而在于我们如何精确理解需求,拆解成合理的计算步骤,并在需要运行 LOD 的计算步骤正确的使用。
LOD 表达式看上去很神奇,似乎可以和数据 “神奇” 的贴合在一起,我们要理解到 LOD 背后就是表之间的 join,而不同明细级别就表示不同的 group by 规则这一背后原理,就能比较好的理解为什么 LOD 表达式能这么运作了。
讨论地址是:精读《15 大 LOD 表达式 - 下》· Issue #370 · dt-fe/weekly
如果你想参与讨论,请 点击这里,每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。
关注 前端精读微信公众号

版权声明:自由转载-非商用-非衍生-保持署名(创意共享 3.0 许可证)
今天关于《精读《15 大 LOD 表达式 - 下》》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于mysql的内容请关注golang学习网公众号!
-
374 收藏
-
398 收藏
-
499 收藏
-
384 收藏
-
184 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 帅气的小土豆
- 这篇文章真及时,太详细了,受益颇多,mark,关注博主了!希望博主能多写数据库相关的文章。
- 2023-06-11 04:34:44
-
- 和谐的山水
- 受益颇多,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢师傅分享技术文章!
- 2023-05-27 04:43:38
-
- 坚定的故事
- 太细致了,已加入收藏夹了,感谢博主的这篇文章,我会继续支持!
- 2023-05-10 09:49:33