Mysql专栏 - 缓冲池补充、数据页、表空间简述
来源:SegmentFault
时间:2023-02-24 20:27:02 368浏览 收藏
本篇文章主要是结合我之前面试的各种经历和实战开发中遇到的问题解决经验整理的,希望这篇《Mysql专栏 - 缓冲池补充、数据页、表空间简述》对你有很大帮助!欢迎收藏,分享给更多的需要的朋友学习~
Mysql专栏 - 缓冲池补充、数据页、表空间简述
概述
- 补充缓冲池的内容,关于后台刷新线程,以及多线程访问buffer pool的锁模式等
- 数据行和数据页的结构,简要的了解简单的内部细节。
- 表空间以及数据区,以及整个mysql表的逻辑结构
缓冲池补充
在介绍具体的内容之前,这里先补充关于缓冲池的一些细节。
后台线程定时刷新冷数据
上一节提到了冷热数据分离,其实冷数据不可能是在缓冲池满的时候才会进行刷新的,而是会在LRU冷数据的尾部随机找几个缓存页刷入磁盘,他会有一个定时任务,每隔一段时间就进行刷新的操作,同时将刷新到磁盘之后的数据页加入到free链表当中。所以LRU的链表会定期把数据刷入到磁盘当中进行处理,并且在缓存没有用完的时候会清空一些无用的缓存页。
flush链表的数据定期刷入缓存
flush的链表存放的是脏页数据,当然它也有一个定时任务,会定期把flash链表的数据刷入到缓冲池当中,并且我们也可以大致认为整个LRU是不断的移动的,flush链表的缓存页页在不断的减少,free list的内容在不断变多。
多线程并发访问是否会加锁
多线程访问的时候会进行加锁,因为读取一个缓冲页涉及 free list, flush list, lru list三个链表的操作,并且还需要对于数据页进行哈希函数的查找操作,所以整个操作过程是肯定要加锁的,虽然看似操作的链表有三个,但是实际上耗费不了多少的性能,因为链表的操作都是一些指针的操作查找操作,所以基本都是一些常数的时间和空间消耗,即使是排队来一个个处理,也是没有多大的影响的。
多个buffer pool并行优化
当mysql的buffer pool大于1g的 时候其实可以配置多个缓冲池,MySQL默认的规则是:如果你给Buffer Pool分配的内存小于1GB,那么最多就只会给你一个Buffer Pool。比如在下面的案例当中如果是一个8G的Mysql服务器,可以做如下的配置:
[server] innodb_buffer_pool_size = 8589934592 innodb_buffer_pool_instances = 4
这样就可以设置4个buffer pool,每一个占用2g大小。实际生产环境使用buffer pool进行调优是十分重要的。
运行过程中可以调整buffer pool大小么?
就目前讲解来看,是无法实现动态的运行时期调整大小的。为什么?因为如果要调整的话需要把整个缓冲区的大小拷贝到新的内存,这个速度实在是太慢了。所以针对这一个问题,mysql引入了chunk的概念。
mysql的chunk机制把buffer pool 拆小
为了实现动态的buffer pool扩展,buffer pool是由很多chunk组成的,他的大小是innodb_buffer_pool_chunk_size参数控制的,默认值就是128MB,也就是说一个chunk就是一个默认的缓冲池的大小,同时缓存页和描述信息也是按照chunk进行分块的,假设有一个2G 的chunk的,它的每一个块是128M,也就是大概有16个chunk进行切割。
有了chunk之后,申请新的内存空间的时候,我们要把之前的缓存复制到新的空间就好办了,直接生成新的到chunk即可。然后把数据搬移到新的chunk即可。
生产环境给多少buffer pool合适?
如果32g的mysql机器要给30g的buffer pool,想想也没有道理!crud的操作基本都是内存的操作,所以性能十分高,对于32g的内存,你的机器起码就得用好几个g的处理,所以首先我们可以分配一半的内存给mysql.或者给个60%左右的内容即可。
Total memory allocated xxxx; Dictionary memory allocated xxx Buffer pool size xxxx Free buffers xxx Database pages xxx Old database pages xxxx Modified db pages xx Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young xxxx, not young xxx xx youngs/s, xx non-youngs/s Pages read xxxx, created xxx, written xxx xx reads/s, xx creates/s, 1xx writes/s Buffer pool hit rate xxx / 1000, young-making rate xxx / 1000 not xx / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: xxxx, unzip_LRU len: xxx I/O sum[xxx]:cur[xx], unzip sum[16xx:cur[0]
下面我们给大家解释一下这里的东西,主要讲解这里跟buffer pool相关的一些东西。
相关解释:
(1)Total memory allocated,这就是说buffer pool最终的总大小是多少 (2)Buffer pool size,这就是说buffer pool一共能容纳多少个缓存页 (3)Free buffers,这就是说free链表中一共有多少个空闲的缓存页是可用的 (4)Database pages和Old database pages,就是说LRU链表中一共有多少个缓存页,以及冷数据区域里的缓存页 数量 (5)Modified db pages,这就是flush链表中的缓存页数量 (6)Pending reads和Pending writes,等待从磁盘上加载进缓存页的数量,还有就是即将从LRU链表中刷入磁盘的数 量、即将从flush链表中刷入磁盘的数量 (7)Pages made young和not young,这就是说已经LRU冷数据区域里访问之后转移到热数据区域的缓存页的数 量,以及在LRU冷数据区域里1s内被访问了没进入热数据区域的缓存页的数量 (8)youngs/s和not youngs/s,这就是说每秒从冷数据区域进入热数据区域的缓存页的数量,以及每秒在冷数据区 域里被访问了但是不能进入热数据区域的缓存页的数量 (9)Pages read xxxx, created xxx, written xxx,xx reads/s, xx creates/s, 1xx writes/s,这里就是说已经读取、 创建和写入了多少个缓存页,以及每秒钟读取、创建和写入的缓存页数量 (10)Buffer pool hit rate xxx / 1000,这就是说每1000次访问,有多少次是直接命中了buffer pool里的缓存的 (11)young-making rate xxx / 1000 not xx / 1000,每1000次访问,有多少次访问让缓存页从冷数据区域移动到 了热数据区域,以及没移动的缓存页数量 (12)LRU len:这就是LRU链表里的缓存页的数量 (13)I/O sum:最近50s读取磁盘页的总数 (14)I/O cur:现在正在读取磁盘页的数量
数据行和数据页的结构
在了解这些概念之前,我们需要先了解下面这些问题:
为什么mysql不能直接更新磁盘?
因为一个请求直接对于磁盘文件读写,虽然技术上没问题,但是性能会极差。磁盘的读写性能非常的差,所以不可能更新磁盘文件读取磁盘的。
为什么要引入数据页的概念?
一个数据肯定不是加载一条就读取一次磁盘文件的,就好比你烧柴不可能每次只拿一根,烧完再去拿一根,一般都是直接拿一捆柴拿然后拿到了一个个丢进去,这样就快了,数据页也是如此,之前说过一个数据页占16kb,所以肯定是加载很多行到数据页的内部。
数据行
数据行在磁盘里面怎么放?
之前都是讨论数据怎么在缓存页放,现在我们回过头来看下数据行在数据页里面要怎么放。这里其实涉及一个叫做行格式的概念,一个表可以指定一个行是以什么样的格式进行存储,比如下面的方式指定行格式:
CREATE TABLE customer ( name VARCHAR(10) NOT NULL, address VARCHAR(20), gender CHAR(1), job VARCHAR(30), school VARCHAR(50) ) ROW_FORMAT=COMPACT;
对于行的存储格式,在mysql当中是如下存储的:
变长字段的长度列表,null值列表,数据头,column01的值,column02的值,column0n的值......
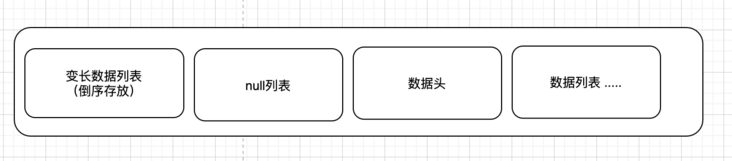
变长数据是如何存放的?
根据上面的行格式定义,相信也可以猜出来一部分,假设我们有一个字段是varchar(5)内容是abcd, 有一个字段是varchar(10)内容是 bcd,实际上存储则是按照下面这种格式存储,但是如果你是char(1)则不需要额外的一个变长字段长度的参数,直接放到对应的字段里面即可:
| Ox03 | ox04 | null | 数据头 | abc | Bcd |
|---|
需要注意的是这里的变长长度参数是逆序存储的,是逆序存储的。
为什么一行数据的null不能直接存储?
null值是以二进制的方式进行存储的,并且变长参数的字段实际上只存储有值的数据,如果数据是没有值为一个null也不需要存储变长字段的长度参数。null值按照bit位存储的,并且在对应的null "坑位"放一个1 或者 0,1表示是null, 0表示不是null。
举个例子,4个字段里面2个为null,2个不是则是1010 ,但是实际存储的时候也是逆序的,也是逆序的是 0101
另外存储的时候不是4个bit位置,而是使用8个bit的倍数(8的倍数,有点像java的对象头的补充数据位的操作.),如果不足8个则需要补0,所以最后的结果如下:
0x09 0x04 00000101 头信息 column1=value1 column2=value2 ... columnN=valueN,
那要如何存储?
其实就按照紧凑的方式存储成为一行的数据,这样紧凑的方式不仅可以节省空间,并且可以使得操作内存成为一种类似数组的顺序访问的操作。
40个bit位的数据头:(索引的时候才解读,伞兵,掠过)
在上面的结构图中,每一行数据的存储还需要一个40位的bit数据头,并且用来描述这个数据,这里我们先简单了解数据头的结构,在后续的内容会再次进行解释:
- 首先1和2都是预留,第一个bit位和第二个都是预留的位置,没有任何的含义。
- 用一个bit位的delete_mask来标记这个行是否已经被删除了(第三位)。所以其实不管你怎么设计其实mysql内部的删除都是一个假删除
- 下一个bit位置使用1位min_rec_mask(第四位),b+树当中的每一层的非叶子节点的最小值的标记
- 下一个bit位置为 4个bitn_owned(第五位),具体的作用暂时不进行介绍。
- 下一个为13个bit位的heap_no,记录在堆里的位置,关于堆也会放到索引里面介绍。
- 下一个是3bit的record_type 行数据类型:0普通类型,1b+树的叶子节点,2最小值数据,3最大值数据
- 最后是16个bit的next_record,这个是指向下一条数据的指针
每一行数据真实的物理存储结构:
在真实的磁盘文件中,存储的内容还有不同,那就是关于数据的内容,上面我们介绍了如何存储一行数据。
0x09 0x04 00000101 0000000000000000000010000000000000011001 jack m xx_school
然而实际上略微有些差别,在实际的磁盘存储的过程是按照 字符集编码进行存储的,一行数据实际上下面这样滴:
0x09 0x04 00000101 0000000000000000000010000000000000011001 616161 636320 6262626262
dataFile.setStartPosition(25347) dataFile.setEndPosition(28890) dataFile.write(cachePage)
在伪代码里面读取一个数据页首先需要的是开始和结束的时间位,通过表空间找到对应的段,然后找到对应的数据区,根据分区找到对应的数据页,然后页的内部数据行如下的方式进行展示:
因为一个数据页的大小其实是固定的,所以一个数据页固定就是可能在一个磁盘文件里占据了某个开始位置到结束位置的一段数据,此时你写回去的时候也是一样的,选择好固定的一段位置的数据,直接把缓存页的数据写回去,就覆盖掉了原来的那个数据页了,就如上面的伪代码示意
本篇关于《Mysql专栏 - 缓冲池补充、数据页、表空间简述》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于数据库的相关知识,请关注golang学习网公众号!
-
374 收藏
-
398 收藏
-
499 收藏
-
384 收藏
-
184 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习