面试官:你说说一条查询SQL的执行过程
来源:SegmentFault
时间:2023-01-10 14:58:06 219浏览 收藏
哈喽!今天心血来潮给大家带来了《面试官:你说说一条查询SQL的执行过程》,想必大家应该对数据库都不陌生吧,那么阅读本文就都不会很困难,以下内容主要涉及到MySQL、Java,若是你正在学习数据库,千万别错过这篇文章~希望能帮助到你!
为了理解这个问题,先从Mysql的架构说起,对于Mysql来说,大致可以分为3层架构。
第一层作为客户端和服务端的连接,连接器负责处理和客户端的连接,还有一些权限认证之类。比如客户端通用用户名密码连接到Mysql服务器,还有对于数据库表的执行权限。
第二层是核心层,基本上Mysql大部分的核心功能都在这一层,包括查询缓存、解析器、优化器之类,比如SQL解析、优化、索引选择,到最后生成执行计划。
第三层则是存储引擎了,Mysql通过执行引擎直接调用存储引擎API查询数据库中数据。
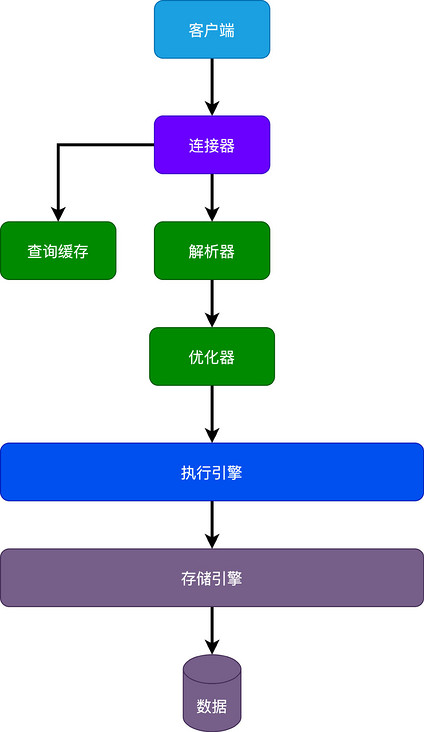
通过Mysql的架构分层,我们首先就可以很清晰的了解到一个SQL的大概的执行过程。
- 首先客户端发送请求到服务端,建立连接。
- 服务端先看下查询缓存是否命中,命中就直接返回,否则继续往下执行。
- 接着来到解析器,进行语法分析,一些系统关键字校验,校验语法是否合规。
- 然后优化器进行SQL优化,比如怎么选择索引之类,然后生成执行计划。
- 最后执行引擎调用存储引擎API查询数据,返回结果。
这就是一个很概括性的SQL执行过程,接下来,具体到每个步骤详细说明一下。
查询缓存
如果你翻看Mysql的官方文档就会知道,查询缓存在5.7.20版本已经被弃用,并且8.0的版本已经删除了。为啥要删除,可能觉得太鸡肋了吧。
我们可以通过命令来查看查询缓存是否可用。
mysql> SHOW VARIABLES LIKE 'have_query_cache'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | have_query_cache | YES | +------------------+-------+
除此之外,查询缓存还有一些核心参数。更具体的说明可以参考官方文档。
query_cache_type:是否打开查询缓存,值为0\1\2,分别对应为OFF\ON\DEMAND,ON的话则代表开启查询缓存,但是可以通过
SELECT SQL_NO_CACHE来手动禁用,DEMAND则代表只缓存以
SELECT SQL_CACHE开头的SQL语句。
query_cache_limit:缓存结果大小限制,如果查询结果超过大小则不会被缓存,默认是1M大小。
query_cache_size:为查询缓存分配的内存大小,他是1024的整数倍。
query_cache_min_res_unit:查询缓存分配内存块的最小单位,默认为4KB。这是查询缓存分配内存的基本单位,即便比如查询的数据只有1个字节,也会按照最小内存单元大小来分配内存空间。
在进行SQL解析之前,系统会判断查询缓存是否打开,如果打开,就拿缓存中的查询和传入的查询比较,如果完全一样,就会从缓存中直接返回。
但是需要特别注意的是,无论大小写、空格还是注释,都会影响缓存的命中结果,也就是说必须完全一样!
比如以下的SQL大小写不同、多了空格都无法命中查询缓存。
select * from user; SELECT * from user; select * from user;
解析器&预处理器
如果查询缓存未命中,就会进入正常的SQL执行环节。
首先就像我们正常的业务开发一样,第一步都是对参数的规则校验,Mysql也一样,解析器会进行词法语法分析,基于语法规则对SQL进行校验。
比如关键字是否使用正确啊,或者说关键字顺序是不是正确,比如说你把
select写成了
selct,
order by写成了
by order。
如果校验OK,那么就生成一颗“解析树”。
接着预处理器就是进一步依据合法规则生成的解析树进行校验,比如表名、列名是否存在等等。
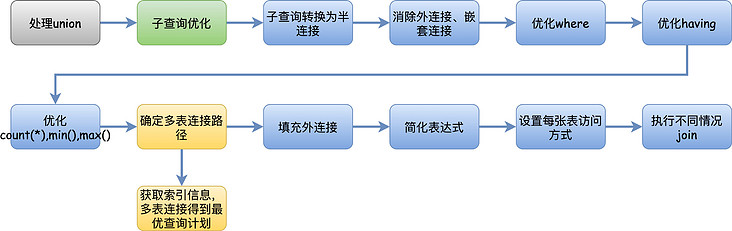
优化器
如果说解析器和预处理器是我们业务逻辑的前置校验环节,优化器就是真正的处理业务逻辑的地方。
一条查询SQL可以有N种执行方式,优化器的最终目标是找到最好的执行计划,交给执行引擎去执行。
但是实际使用中我们经常会发现,Mysql经常有选择错索引的情况,我明明有更快的索引,结果它不用,导致搞出了慢查询。
这是因为Mysql的优化器是基于成本模型的优化器,他只是基于已有的成本计算公式来选择一个成本最低的执行方式,这个执行方式不一定会是最快的,只能说大多数时候,优化器的选择比我们自己的选择更准确。
总的来说,这个优化过程太复杂了,流程大致就是下图所示,更详细的内容可以看《数据库查询优化器的艺术原理解析与SQL性能》这本书(我实在是懒得看了,吐了)。
执行引擎
大部分核心的事情已经被优化器处理完了,最后执行引擎只要根据生成好的执行计划查询数据返回就好了,这一步相对就挺简单了。
执行引擎只需要根据执行计划的指令调用存储引擎的API就可以了。
当然这一步如果可以缓存查询结果,那么就在这个阶段把查询结果缓存下来,然后把结果返回给客户端就可以了。
总结
一图胜千言。
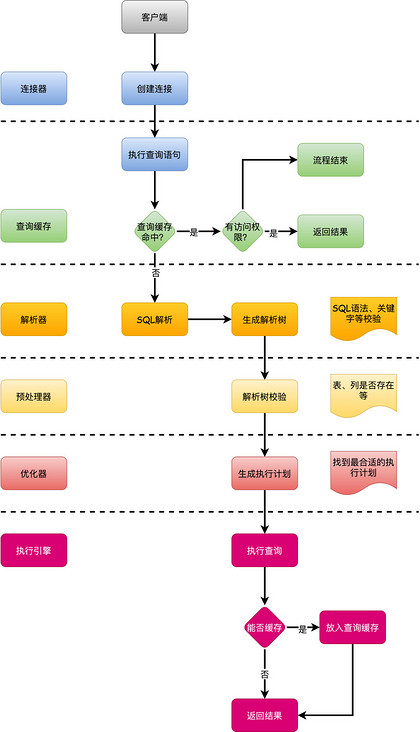
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于数据库的相关知识,也可关注golang学习网公众号。
-
374 收藏
-
499 收藏
-
384 收藏
-
184 收藏
-
265 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 舒服的春天
- 这篇技术贴真及时,太全面了,真优秀,已收藏,关注老哥了!希望老哥能多写数据库相关的文章。
- 2023-07-03 00:33:37
-
- 合适的太阳
- 这篇技术文章真是及时雨啊,作者大大加油!
- 2023-05-13 12:34:51
-
- 悲凉的眼神
- 感谢大佬分享,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢up主分享文章!
- 2023-04-03 13:22:32
-
- 复杂的店员
- 细节满满,码起来,感谢师傅的这篇文章,我会继续支持!
- 2023-01-29 12:23:49
-
- 神勇的导师
- 这篇技术贴出现的刚刚好,老哥加油!
- 2023-01-25 11:55:23
-
- 妩媚的小鸭子
- 这篇技术文章太及时了,好细啊,感谢大佬分享,码住,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-01-22 04:52:13
-
- 重要的鲜花
- 赞 ??,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢up主分享博文!
- 2023-01-16 10:53:34
-
- 还单身的魔镜
- 太全面了,收藏了,感谢师傅的这篇文章,我会继续支持!
- 2023-01-13 17:50:48