MySQL 数据库集群-PXC 方案(二)
来源:SegmentFault
时间:2023-01-19 21:58:54 466浏览 收藏
哈喽!今天心血来潮给大家带来了《MySQL 数据库集群-PXC 方案(二)》,想必大家应该对数据库都不陌生吧,那么阅读本文就都不会很困难,以下内容主要涉及到MySQL、高可用、负载均衡、MySQL集群、keepalived,若是你正在学习数据库,千万别错过这篇文章~希望能帮助到你!
MySQL 数据库集群-PXC 方案(二)
集群状态信息
PXC 集群信息可以分为队列信息、复制信息、流控信息、事务信息、状态信息。这些信息可以通过 SQL 查询到。每种信息的详细意义可以在官网查看。
show status like '%wsrep%';
复制信息

举例说明几个重要的信息:
| 状态 | 描述 |
|---|---|
| wsrep_replicated | 被其他节点复制的次数 |
| wsrep_replicated_bytes | 被其他节点复制的数据次数 |
| wsrep_received | 从其他节点处收到的写入请求总数 |
| wsrep_received_bytes | 从其他节点处收到的写入数据总数 |
| wsrep_last_applied | 同步应用次数 |
| wsrep_last_committed | 事务提交次数 |
队列信息
队列是一种很好的缓存机制,如果 PXC 正在满负荷工作,没有线程去执行数据的同步,同步请求会缓存到队列中,然后空闲线程从队列中取出任务,执行同步的请求,有了队列 PXC 就能用少量的线程应对瞬时大量的同步请求。
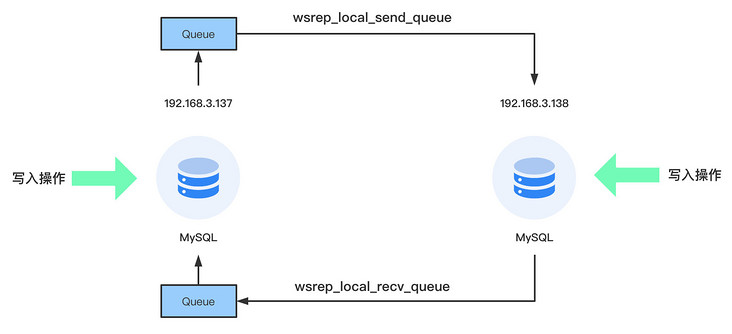
| 状态 | 描述 |
|---|---|
| wsrep_local_send_queue | 发送队列的长度(瞬时同步的请求数量) |
| wsrep_local_send_queue_max | 发送队列的最大长度 |
| wsrep_local_send_queue_min | 发送队列的最小长度 |
| wsrep_local_send_queue_avg | 发送队列的平均长度 |
| wsrep_local_recv_queue | 接收队列的长度 |
| wsrep_local_recv_queue_max | 接收队列的最大长度 |
| wsrep_local_recv_queue_min | 接收队列的最小长度 |
| wsrep_local_recv_queue_avg | 接收队列的平均长度 |
当发送队列的
wsrep_slave_threads=16
节点与集群的状态信息

| 状态 | 说明 |
|---|---|
| wsrep_local_state_comment | 节点状态 |
| wsrep_cluster_status | 集群状态(Primary:正常状态、Non-Primary:出现了脑裂请求、Disconnected:不能提供服务,出现宕机) |
| wsrep_connected | 节点是否连接到集群 |
| wsrep_ready | 集群是否正常工作 |
| wsrep_cluster_size | 节点数量 |
| wsrep_desync_count | 延时节点数量 |
| wsrep_incoming_addresses | 集群节点 IP 地址 |
事务相关信息
| 状态 | 说明 |
|---|---|
| wsrep_cert_deps_distance | 事务执行并发数 |
| wsrep_apply_oooe | 接收队列中事务的占比 |
| wsrep_apply_oool | 接收队列中事务乱序执行的频率 |
| wsrep_apply_window | 接收队列中事务的平均数量 |
| wsrep_commit_oooe | 发送队列中事务的占比 |
| wsrep_commit_oool | 无任何意义,不存在本地的乱序提交 |
| wsrep_commit_window | 发送队列中事务的平均数量 |
PXC 节点的安全下线操作
节点用什么命令启动,就用对应的关闭命令去关闭。
- 主节点的管理命令(第一个启动的 PXC 节点)
systemctl start mysql@bootstrap.service systemctl stop mysql@bootstrap.service systemctl restart mysql@bootstrap.service
- 非主节点的管理命令(非第一个启动的 PXC 节点)
service mysql start service mysql stop service mysql restart
- 如果最后关闭的 PXC 节点是安全退出的,那么下次启动要最先启动这个节点,而且要以主节点启动。
- 如果最后关闭的 PXC 节点不是安全退出的,那么要先修改
yum install -y java-1.8.0-openjdk-devel.x86_64
配置 JAVA_HOME 环境变量
ls -lrt /etc/alternatives/java vim /etc/profile source /etc/profile

export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.272.b10-1.el7_9.x86_64/
输入 java -version 如下图就完成配置。

准备工作(三)
下载 mycat
上传 MyCat 压缩包到虚拟机,并解压。
开放防火墙 8066 和 9066 端口:
firewall-cmd --zone=public --add-port=8066/tcp --permanent firewall-cmd --zone=public --add-port=9066/tcp --permanent firewall-cmd --reload
关闭 SELINUX
vim /etc/selinux/config
把 SELINUX 属性值设置成 disabled,之后保存。重启。
reboot
修改 MyCat 的 bin 目录中所有.sh 文件的权限:
chmod -R 777 ./*.sh
MyCat 启动与关闭
启动MyCat: ./mycat start 查看启动状态: ./mycat status 停止: ./mycat stop 重启: ./mycat restart
准备工作(四)
修改配置文件:
修改 server.xml 文件,设置 MyCat 帐户和虚拟逻辑库
0 1 0 0 2 false 0 0 1 64k 1k 0 384m false Abc_123456 test 修改 schema.xml 文件,设置数据库连接和虚拟数据表
select user() select user() 修改 rule.xml 文件,把 mod-long 的 count 值修改成 2
2 重启 MyCat。
测试
在两个分片中都创建 t_user 表:
CREATE TABLE t_user( id INT UNSIGNED PRIMARY KEY, username VARCHAR(200) NOT NULL, password VARCHAR(2000) NOT NULL, tel CHAR(11) NOT NULL, locked TINYINT(1) UNSIGNED NOT NULL DEFAULT 0, INDEX idx_username(username) USING BTREE, UNIQUE INDEX unq_username(username) USING BTREE );远程连接 mycat。
向 t_user 表写入数据,感受数据的切分。
USE test; select * from t_user; #第一条记录被切分到第二个分片 INSERT INTO t_user(id,username,password,tel,locked) VALUES(1,"Jack",HEX(AES_ENCRYPT('123456','HelloWorld')),'1333222111',false); #第二条记录被切分到第一个分片 INSERT INTO t_user(id,username,password,tel,locked) VALUES(2,"Rose",HEX(AES_ENCRYPT('123456','HelloWorld')),'1335555111',false);可以查看对应的库中都是没有问题的。


数据切分
切分算法 适用场合 备注 主键求模切分 数据增长缓慢,难于增加分片 有明确主键值 枚举值切分 归类存储数据,适用于大多数业务 主键范围切分 数据快速增长,容易增加分片 有明确主键值 日期切分 数据快速增长,容易增加分片 主键求模切分
上面的示例中,使用的就是主键求模切分,其特点如下:
- 主键求模切分适合用在初始数据很大,但是数据增长不快的场景。例如,地图产品、行政数据、企业数据等。
- 主键求模切分的弊端在于扩展新分片难度大,迁移的数据太多。
- 如果需要扩展分片数量,建议扩展后的分片数量是原有分片的 2n 倍。例如,原本是两个分片,扩展后是四个分片。
主键范围切分
- 主键范围切分适合用在数据快速增长的场景。
- 容易增加分片,需要有明确的主键列。
日期切分
- 日期切分适合用在数据快速增长的场景。
- 容易增加分片,需要有明确的日期列。
枚举值切分
- 枚举值切分适合用在归类存储数据的场景,适合大多数业务。
- 枚举值切分按照某个字段的值(数字)与
sharding_id customer-hash-int customer-hash-int.txt 在
101=0 102=0 103=0 104=1 105=1 106=1
配置
进入 MyCat 中执行热加载语句,该语句的作用可以使 Mycat 不用重启就能应用新的配置:
reload @@config_all;
在两个分片中分别执行如下建表语句:
USE test; CREATE TABLE t_customer( id INT UNSIGNED PRIMARY KEY, username VARCHAR(200) NOT NULL, sharding_id INT NOT NULL );之后我们在 MyCat 中进行查询看看:
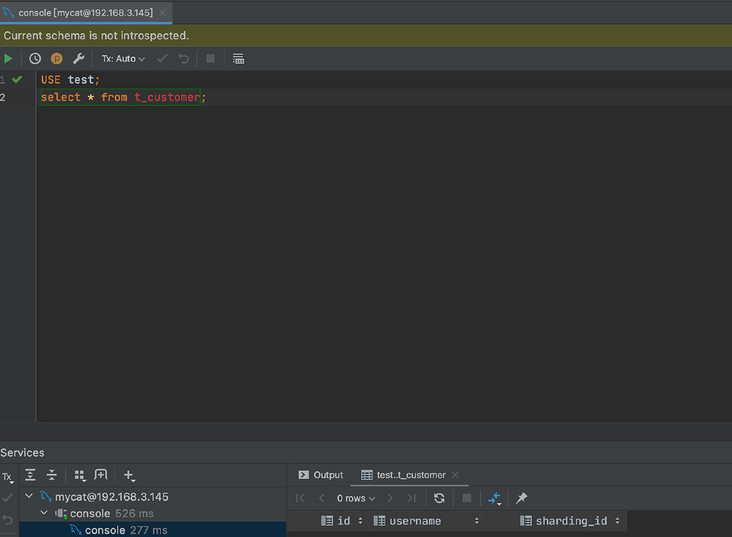
也是 ok 的。
接着我们增加一条数据:
insert into t_customer(id,username,sharding_id) values (1,'Michelle',101); insert into t_customer(id,username,sharding_id) values (2,'Jack',102);
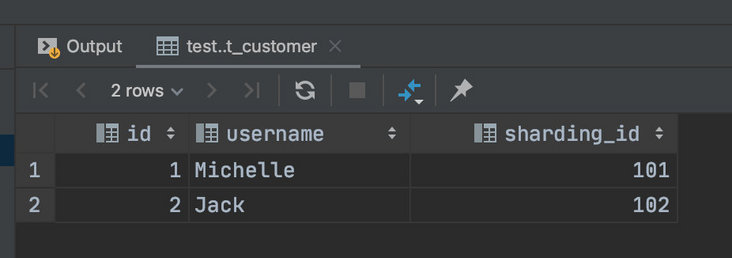
查看第一个分片可以看到数据已经切分过来了
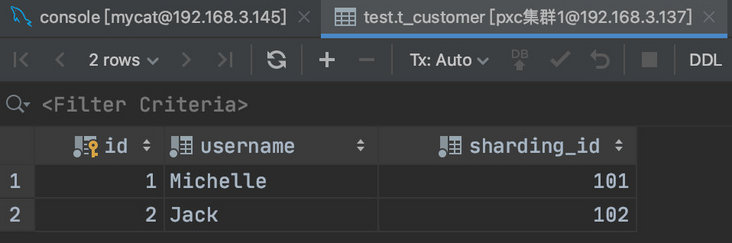
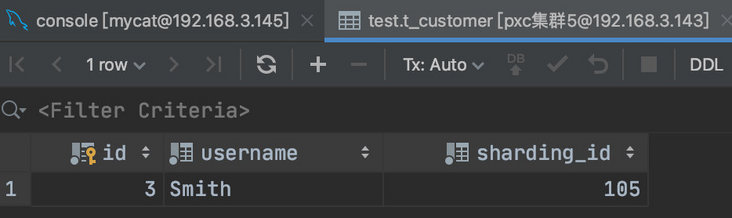
如果我们再增加一条 SQL:
insert into t_customer(id,username,sharding_id) values (3,'Smith',105);
很显然,数据被分到了第二个分片中。
父子表
当有关联的数据存储在不同的分片时,就会遇到表连接的问题,在 MyCat 中是不允许跨分片做表连接查询的。为了解决跨分片表连接的问题,MyCat 提出了父子表这种解决方案。
父子表规定父表可以有任意的切分算法,但与之关联的子表不允许有切分算法,即子表的数据总是与父表的数据存储在一个分片中。父表不管使用什么切分算法,子表总是跟随着父表存储。
例如,用户表与订单表是有关联关系的,我们可以将用户表作为父表,订单表作为子表。当 A 用户被存储至分片 1 中,那么 A 用户产生的订单数据也会跟随着存储在分片 1 中,这样在查询 A 用户的订单数据时就不需要跨分片了。如下图所示:

配置父子表
在
进入 MyCat 中执行热加载语句,该语句的作用可以使 Mycat 不用重启就能应用新的配置:
reload @@config_all;
在两个分片中执行建表 SQL:
USE test; CREATE TABLE t_orders( id INT UNSIGNED PRIMARY KEY, customer_id INT NOT NULL, datetime TIMESTAMP DEFAULT CURRENT_TIMESTAMP );执行成功后,我们插入些数据测试:
USE test; insert into t_orders(id,customer_id) values (1,1); insert into t_orders(id,customer_id) values (2,1); insert into t_orders(id,customer_id) values (3,1); insert into t_orders(id,customer_id) values (4,2); insert into t_orders(id,customer_id) values (5,3);
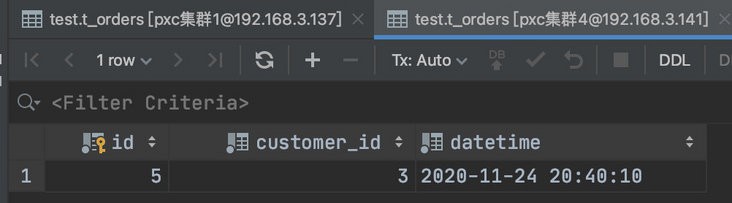
我们在第一个分片中增加了两个用户 id 为 1 、2 的,在第二个分片中增加了一个用户 id 为 3 的。
所以第一个分片会有 4 条记录,而第二个分片中有一条。
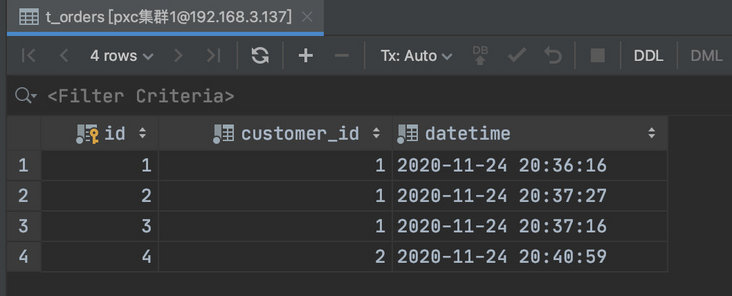
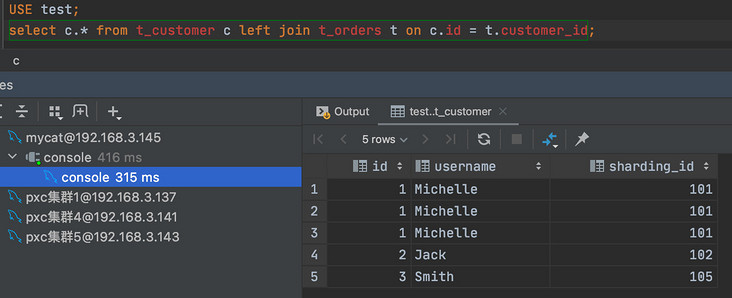
由于父子表的数据都是存储在同一个分片,所以在 MyCat 上进行关联查询也是没有问题的:
组建双机热备的高可用 MyCat 集群
在之前的示例中,我们可以看到对后端数据库集群的读写操作都是在 MyCat 上进行的。MyCat 作为一个负责接收客户端请求,并将请求转发到后端数据库集群的中间件,不可避免的需要具备高可用性。否则,如果 MyCat 出现单点故障,那么整个数据库集群也就无法使用了,这对整个系统的影响是十分巨大的。
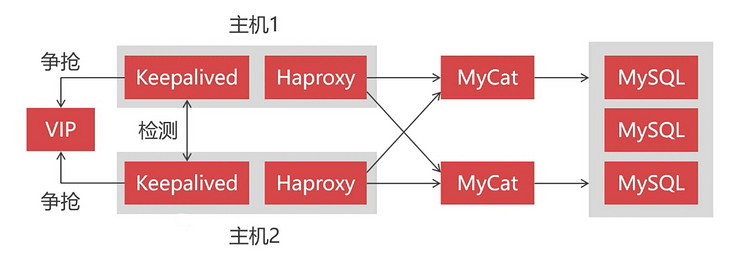
所以我们现在将要演示如何去构建一个高可用的 MyCat 集群,为了搭建 MyCat 高可用集群,除了要有两个以上的 MyCat 节点外,还需要引入 Haproxy 和 Keepalived 组件。
其中 Haproxy 作为负载均衡组件,位于最前端接收客户端的请求并将请求分发到各个 MyCat 节点上,用于保证 MyCat 的高可用。而 Keepalived 则用于实现双机热备,因为 Haproxy 也需要高可用,当一个 Haproxy 宕机时,另一个备用的 Haproxy 能够马上接替。也就说同一时间下只会有一个 Haproxy 在运行,另一个 Haproxy 作为备用处于等待状态。当正在运行中的 Haproxy 因意外宕机时,Keepalived 能够马上将备用的 Haproxy 切换到运行状态。
Keepalived 是让主机之间争抢同一个虚拟 IP(VIP)来实现高可用的,这些主机分为 Master 和 Backup 两种角色,并且 Master 只有一个,而 Backup 可以有多个。最开始 Master 先获取到 VIP 处于运行状态,当 Master 宕机后,Backup 检测不到 Master 的情况下就会自动获取到这个 VIP,此时发送到该 VIP 的请求就会被 Backup 接收到。这样 Backup 就能无缝接替 Master 的工作,以实现高可用。
引入这些组件后,最终我们的集群架构将演变成这样子:
Haproxy包括以下一些特征:
- 根据静态分配的cookie分配HTTP请求。
- 分配负载到各个服务器,同时保证服务器通过使用HTTP Cookie实现连接保持。
- 当主服务器宕机时切换到备服务器,允许特殊端口的服务监控。
- 做维护时通过配置可以保证业务的连续性,更加人性化。
- 添加修改删除HTTP Request和Respone头。
- 通过特定表达式Block HTTP请求。
- 根据应用的cookie做连接保持。
- 常有用户验证的详细的HTML监控报告。
Haproxy的负载均衡算法现在具体有如下8种:
- roundrobin:简单的轮询。
- static-rr:权重轮询。
- leastconn:最少连接者优先。
- source:根据请求源IP,这个跟Nginx的ip_hash机制类似。
- ri:根据请求的URI。
- rl_param:表示根据请求的URI参数。
- hdr(name):根据HTTP请求头来锁定每一次HTTP请求。
- rdp-cookie(name):根据cookie来锁定并哈希每一次TCP请求。
这里就不再演示如何搭建第二台 Mycat 环境了。
这里再说一下目前我的集群:
第一个 PXC 分片:
- 主:192.168.3.137
- 从:192.168.3.138
- 从:192.168.3.139
第二个 PXC 分片:
- 主:192.168.3.141
- 从:192.168.3.143
- 从:192.168.3.144
第一台 MyCat : 192.168.3.146
第二台 MyCat: 192.168.3.147
安装 Haproxy
由于我电脑只有 8G 内存,有点吃不消所以我的 Haproxy 都在 Mycat 服务器上。
开放防火墙 3306 和 4001 端口:
端口 作用 3306 TCP/IP 转发端口 4001 监控界面端口 firewall-cmd --zone=public --add-port=3306/tcp --permanent firewall-cmd --zone=public --add-port=4001/tcp --permanent firewall-cmd --reload
关闭 SELINUX
vim /etc/selinux/config
把 SELINUX 属性值设置成 disabled,之后保存。重启。
reboot
接着我们安装 haproxy
yum install -y haproxy
安装完成后我们修改对应的配置文件
vim /etc/haproxy/haproxy.cfg
记得修改为自己的 MyCat 的 IP。
global log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon # turn on stats unix socket stats socket /var/lib/haproxy/stats defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000 listen admin_stats # 绑定的ip及监听的端口 bind 0.0.0.0:4001 # 访问协议 mode http # URI 相对地址 stats uri /dbs # 统计报告格式 stats realm Global\ statistics # 用于登录监控界面的账户密码 stats auth admin:abc123456 listen proxy-mysql # 绑定的ip及监听的端口 bind 0.0.0.0:3306 # 访问协议 mode tcp # 负载均衡算法 balance roundrobin #日志格式 option tcplog # 需要被负载均衡的主机 server mycat_1 192.168.3.146:8066 check port 8066 weight 1 maxconn 2000 server mycat_2 192.168.3.147:8066 check port 8066 weight 1 maxconn 2000 #使用keepalive检测死链 option tcpka配置完成之后我们进行启动
service haproxy start
我们在浏览器输入 IP 测试:
http://192.168.3.146:4001/dbs
输入我们配置的账号密码后就可以看到如下图:
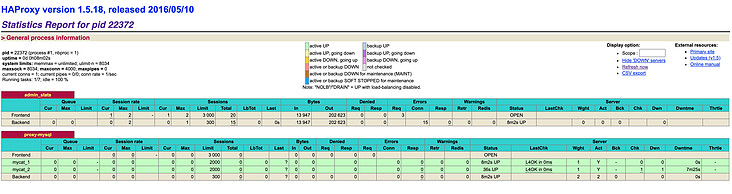
Haproxy 的监控界面提供的监控信息也比较全面,在该界面下,我们可以看到每个主机的连接信息及其自身状态。当主机无法连接时,
#开启VRRP firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0 --protocol vrrp -j ACCEPT #应用设置 firewall-cmd --reload
安装 Keepalived
yum install -y keepalived
编辑配置文件
vim /etc/keepalived/keepalived.conf
vrrp_instance VI_1 { state MASTER interface enp0s3 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 123456 } virtual_ipaddress { 192.168.3.177 } }配置说明:
service keepalived start
我们 ping 一下我们的虚拟地址试试,也是 OK 的!

另外一台步骤一模一样,这里就不演示了!
测试 Keepalived
以上我们完成了 Keepalived 的安装与配置,最后我们来测试 Haproxy 是否已具有高可用性。

连接成功后,执行一些语句测试能否正常插入、查询数据:

最后测试一下 Haproxy 的高可用性,将其中一个 Haproxy 节点上的 keepalived 服务给关掉。
service keepalived stop
然后再次执行执行一些语句测试能否正常插入、查询数据,如下能正常执行代表 Haproxy 节点已具有高可用性:

大功告成!
本篇关于《MySQL 数据库集群-PXC 方案(二)》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于数据库的相关知识,请关注golang学习网公众号!
-
374 收藏
-
499 收藏
-
384 收藏
-
184 收藏
-
265 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 聪慧的小丸子
- 这篇文章出现的刚刚好,太细致了,真优秀,已加入收藏夹了,关注师傅了!希望师傅能多写数据库相关的文章。
- 2023-02-28 03:30:54
-
- 欣慰的雪糕
- 写的不错,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢作者分享技术贴!
- 2023-02-20 00:46:24
-
- 腼腆的可乐
- 这篇文章太及时了,太细致了,很有用,收藏了,关注up主了!希望up主能多写数据库相关的文章。
- 2023-02-18 07:53:22
-
- 朴素的小懒猪
- 很有用,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢老哥分享文章!
- 2023-02-11 14:31:34
-
- 冷傲的心情
- 太细致了,码起来,感谢作者的这篇博文,我会继续支持!
- 2023-02-08 21:37:15