Mysql 实战笔记 (三) 实践(2)
来源:SegmentFault
时间:2023-02-24 20:12:15 373浏览 收藏
知识点掌握了,还需要不断练习才能熟练运用。下面golang学习网给大家带来一个数据库开发实战,手把手教大家学习《Mysql 实战笔记 (三) 实践(2)》,在实现功能的过程中也带大家重新温习相关知识点,温故而知新,回头看看说不定又有不一样的感悟!
五、为什么表数据删除后,表文件大小不变?
一个 InnoDB 表包含两部分,即:表结构定义和数据。在 MySQL 8.0 版本以前,表结构是存在以.frm 为后缀的文件里。而 MySQL 8.0 版本,则已经允许把表结构定义放在系统数据表中了。
表数据
表数据既可以存在共享表空间里,也可以是单独的文件。这个行为是由参数
innodb_file_per_table控制的:
- 这个参数设置为 OFF 表示的是,表的数据放在系统共享表空间,也就是跟数据字典放在一起;
- 这个参数设置为 ON 表示的是,每个 InnoDB 表数据存储在一个以 .ibd 为后缀的文件中。
不论使用 MySQL 的哪个版本,都将这个值设置为 ON。因为,一个表单独存储为一个文件更容易管理,而且在你不需要这个表的时候,通过 drop table 命令,系统就会直接删除这个文件。而如果是放在共享表空间中,即使表删掉了,空间也是不会回收的。
数据删除流程
InnoDB 引擎只会把要删除的记录标记为删除。如果之后要在这个位置插入一个记录时,可能会复用这个位置。但是,磁盘文件的大小并不会缩小。
如果我们删掉了一个数据页上的所有记录,会怎么样?答案是,整个数据页就可以被复用了。但是,数据页的复用跟记录的复用是不同的。
记录的复用,只限于符合范围条件的数据。比如上面的这个例子,ID=400 这条记录被删除后,如果插入一个 ID 是 400 的行,可以直接复用这个空间。
而当整个页从 B+ 树里面摘掉以后,可以复用到任何位置。
如果相邻的两个数据页利用率都很小,系统就会把这两个页上的数据合到其中一个页上,另外一个数据页就被标记为可复用。
delete 命令其实只是把记录的位置,或者数据页标记为了“可复用”,但磁盘文件的大小是不会变的。也就是说,通过 delete 命令是不能回收表空间的。
如果数据是按照索引递增顺序插入的,那么索引是紧凑的。但如果数据是随机插入的,就可能造成索引的数据页分裂。
重建表
经过大量增删改的表,都是可能是存在空洞的。所以,如果能够把这些空洞去掉,就能达到收缩表空间的目的。而重建表,就可以达到这样的目的。
alter table A engine=InnoDB,用来重建表,原理是 Online DDL
重建表的流程:
- 建立一个临时文件,扫描表 A 主键的所有数据页;
- 用数据页中表 A 的记录生成 B+ 树,存储到临时文件中;
- 生成临时文件的过程中,将所有对 A 的操作记录在一个日志文件(row log)中,对应的是图中 state2 的状态;
- 临时文件生成后,将日志文件中的操作应用到临时文件,得到一个逻辑数据上与表 A 相同的数据文件,对应的就是图中 state3 的状态;
- 用临时文件替换表 A 的数据文件。
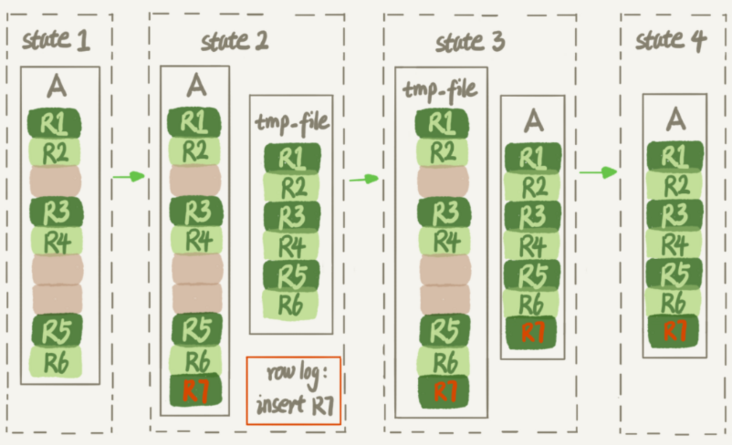
alter 语句在启动的时候需要获取 MDL(元数据) 写锁,但是这个写锁在真正拷贝数据之前就退化成读锁了。为什么要退化呢?为了实现 Online,MDL 读锁不会阻塞增删改操作。那为什么不干脆直接解锁呢?为了保护自己,禁止其他线程对这个表同时做 DDL。
Online 和 inplace
在上图中,根据表 A 重建出来的数据是放在“tmp_file”里的,这个临时文件是 InnoDB在内部创建出来的。整个 DDL 过程都在 InnoDB 内部完成。对于 server 层来说,没有把数据挪动到临时表,是一个“原地”操作,这就是“inplace”名称的来源。
以,我现在问你,如果你有一个 1TB 的表,现在磁盘间是 1.2TB,能不能做一个 inplace的 DDL 呢?答案是不能。因为,tmp_file 也是要占用临时空间的。
optimize table、analyze table 和 alter table区别
从 MySQL 5.6 版本开始,
alter table t engine = InnoDB(也就是 recreate)默认的就是上面图 4 的流程了;
analyze table t其实不是重建表,只是对表的索引信息做重新统计,没有修改数据,这个过程中加了 MDL 读锁;
optimize table t等于
recreate+analyze。
delete truncate drop 的区别
truncate 删除内容、释放空间但不删除表的结构,可以理解为 delete + create。
drop 删除内容和表的结构,释放空间。
六、count 为什么这么慢?
count(*) 的实现方式
MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行
count(*)的时候会直接返回这个数,效率很高(如果加了where 条件的话,MyISAM 表也是不能返回得这么快的);
而 InnoDB 引擎就麻烦了,它执行
count(*)的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
为什么 InnoDB 不跟 MyISAM 一样,也把数字存起来呢?这是因为即使是在同一个时刻的多个查询,由于多版本并发控制(MVCC)的原因,InnoDB 表“应该返回多少行”也是不确定的。 这和 InnoDB 的事务设计有关系,可重复读是它默认的隔离级别,在代码上就是通过多版本并发控制,也就是 MVCC 来实现的。每一行记录都要判断自己是否对这个会话可见,因此对于 count(*) 请求来说,InnoDB 只好把数据一行一行地读出依次判断,可见的行才能够用于计算“基于这个查询”的表的总行数。
InnoDB 是索引组织表,主键索引树的叶子节点是数据,而普通索引树的叶子节点是主键值。所以,普通索引树比主键索引树小很多。对于 count(*) 这样的操作,遍历哪个索引树得到的结果逻辑上都是一样的。因此,MySQL 优化器会找到最小的那棵树来遍历。
show table status 命令显示的行数row不能直接使用。
自己实现一个count(*)计数
用缓存保存计数: redis
在数据库保存计数
count(*)、count(主键 id)、count(字段) 和 count(1) 区别
- count(主键 id):InnoDB 引擎会遍历整张表,把每一行的 id 值都取出来,返回给 server 层。server 层拿到 id 后,判断是不可能为空的,就按行累加。
- count(1):InnoDB 引擎遍历整张表,但不取值。server 层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。
count(字段) :
- 如果这个“字段”是定义为 not null 的话,一行行地从记录里面读出这个字段,判断不能为 null,按行累加;
- 如果这个“字段”定义允许为 null,那么执行的时候,判断到有可能是 null,还要把值取出来再判断一下,不是 null 才累加。
count(*)
,并不会把全部字段取出来,而是专门做了优化,不取值。count(*)肯定不是 null,按行累加。
七、orderby 是怎么工作的?
全字段排序
MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer。
select city,name,age from t where city='杭州' order by name limit 1000
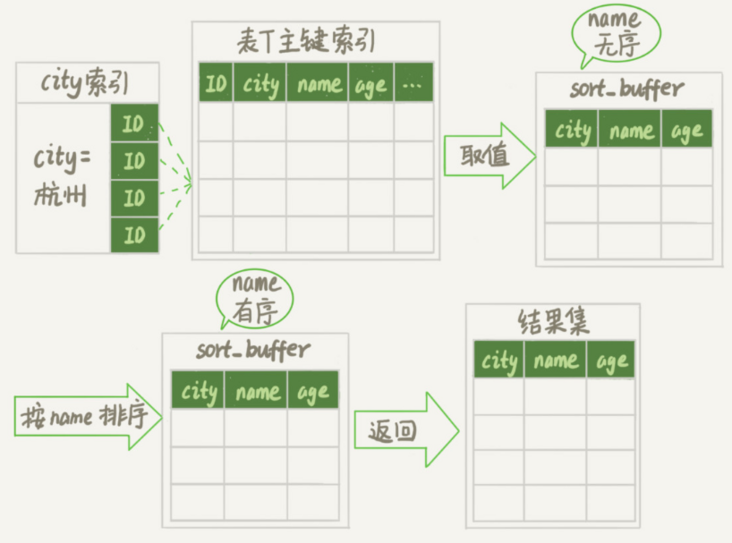
按 name 排序,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数
sort_buffer_size,就是 MySQL 为排序开辟的内存(sort_buffer)的大小。如果要排序的数据量小于 sort_buffer_size,排序就在内存中完成。
但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。外部排序一般使用归并排序算法。将需要排序的数据分成 若干 份,每一份单独排序后存在这些临时文件中。然后把这些个有序文件再合并成一个有序的大文件。
sort_buffer_size 越小,需要分成的份数越多,number_of_tmp_files 的值就越大。
rowid 排序
如果 MySQL 认为排序的单行长度太大会怎么做呢?
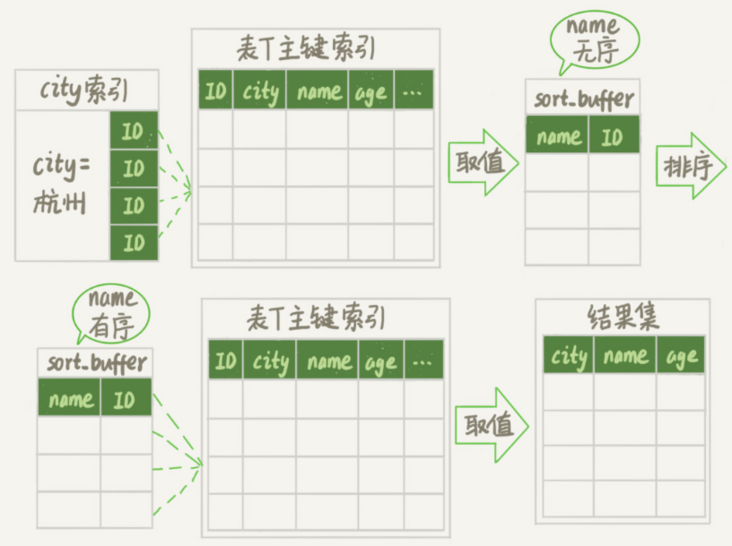
全字段排序 VS rowid 排序
如果 MySQL 实在是担心排序内存太小,会影响排序效率,才会采用 rowid 排序算法, 这样排序过程中一次可以排序更多行,但是需要再回到原表去取数据。如果 MySQL 认为内存足够大,会优先选择全字段排序, 把需要的字段都放到 sort_buffer中,这样排序后就会直接从内存里面返回查询结果了,不用再回到原表去取数据。这也就体现了 MySQL 的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。
可以利用覆盖索引,防止使用排序和临时表
alter table t add index city_user_age(city, name, age);

可以看到,Extra 字段里面多了“Using index”,表示的就是使用了覆盖索引,性能上会快很多。
八、如何正确地显示随机消息?
内存临时表
select word from words order by rand() limit 3;

Extra 字段显示 Using temporary,表示的是需要使用临时表;Using filesort,表示的是需要执行排序操作。因此这个 Extra 的意思就是,需要临时表,并且需要在临时表上排序。
上面sql的执行流程:
- 创建一个临时表。这个临时表使用的是 memory 引擎, 表里有两个字段,第一个字段是double 类型,为了后面描述方便,记为字段 R,第二个字段是 varchar(64) 类型,记为字段 W。并且,这个表没有建索引。
- 从 words 表中,按主键顺序取出所有的 word 值。对于每一个 word 值,调用 rand()函数生成一个大于 0 小于 1 的随机小数,并把这个随机小数和 word 分别存入临时表的R 和 W 字段中,到此,扫描行数是 10000。
- 现在临时表有 10000 行数据了,接下来你要在这个没有索引的内存临时表上,按照字段R 排序。
- 初始化 sort_buffer。sort_buffer 中有两个字段,一个是 double 类型,另一个是整型。
- 从内存临时表中一行一行地取出 R 值和位置信息(rowid),分别存入 sort_buffer 中的两个字段里。这个过程要对内存临时表做全表扫描,此时扫描行数增加 10000,变成了 20000。
- 在 sort_buffer 中根据 R 的值进行排序。注意,这个过程没有涉及到表操作,所以不会增加扫描行数。
- 排序完成后,取出前三个结果的位置信息,依次到内存临时表中取出 word 值,返回给客户端。这个过程中,访问了表的三行数据,总扫描行数变成了 20003。
慢查询日志为:
# Query_time: 0.900376 Lock_time: 0.000347 Rows_sent: 3 Rows_examined: 20003 SET timestamp=1541402277; select word from words order by rand() limit 3;
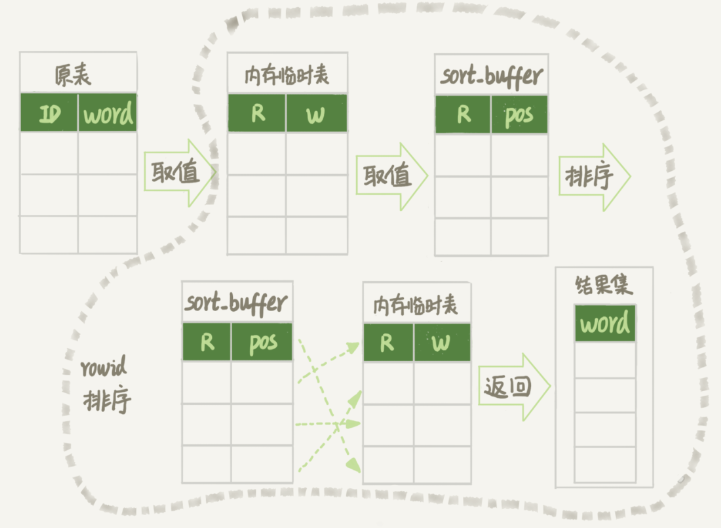
图中的 pos 就是位置信息(rowid),它表示的是:每个引擎用来唯一标识数据行的信息。对于有主键的 InnoDB 表来说,这个 rowid 就是主键 ID。
到这里,稍微小结一下:order by rand() 使用了内存临时表,内存临时表排序的时候使用了 rowid 排序方法。
磁盘临时表
tmp_table_size这个配置限制了内存临时表的大小,默认值是 16M。 如果临时表大小超过了
tmp_table_size,那么内存临时表就会转成磁盘临时表。磁盘临时表使用的引擎默认是 InnoDB, 是由参数
internal_tmp_disk_storage_engine控制的。
当使用磁盘临时表的时候,对应的就是一个没有显式索引的 InnoDB 表的排序过程。
九、为什么有些SQL语句逻辑相同,性能却差异巨大?
条件字段函数操作
统计发生在所有年份中 7 月份的交易记录总数。
select count(*) from tradelog where month(t_modified)=7;
t_modified 字段上有索引,但是对字段做了函数计算,就用不上索引了。为什么条件是
where t_modified='2018-7-1'的时候可以用上索引,而改成
where month(t_modified)=7的时候就不行了?对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。改为:
select count(*) from tradelog where (t_modified >= '2016-7-1' and t_modified= '2017-7-1' and t_modified= '2018-7-1' and t_modified
隐式类型转换
select * from tradelog where tradeid=110717;
tradeid 的字段类型是 varchar(32),而输入的参数却是整型,所以需要做类型转换。对于优化器来说,这个语句相当于:
select * from tradelog where CAST(tradid AS signed int) = 110717;
隐式字符编码转换
字符集不同造成的问题:tradeid不同
select d.* from tradelog l, trade_detail d where d.tradeid=l.tradeid and l.id=2;
今天带大家了解了MySQL的相关知识,希望对你有所帮助;关于数据库的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
-
100 收藏
-
100 收藏
-
100 收藏
-
100 收藏
-
100 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 听话的黄蜂
- 这篇技术文章太及时了,太详细了,赞 ??,码起来,关注博主了!希望博主能多写数据库相关的文章。
- 2023-04-10 23:13:14
-
- 眯眯眼的热狗
- 真优秀,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢大佬分享文章内容!
- 2023-03-29 10:51:59