【转载】为什么Mongodb索引用B树,而Mysql用B+树?
来源:SegmentFault
时间:2023-01-16 19:40:17 323浏览 收藏
大家好,今天本人给大家带来文章《【转载】为什么Mongodb索引用B树,而Mysql用B+树?》,文中内容主要涉及到MySQL、mongodb,如果你对数据库方面的知识点感兴趣,那就请各位朋友继续看下去吧~希望能真正帮到你们,谢谢!
文章转载自孤独烟的微信公众号,可关注他的公众号阅读原文

正文
这里的Mysql指的是Innodb的存储引擎下的索引结构,其他存储引擎我们暂时不讨论。
B树和B+树
开头,我们先回忆一下,B树和B+树的结构以及特点,如下所示:
B树
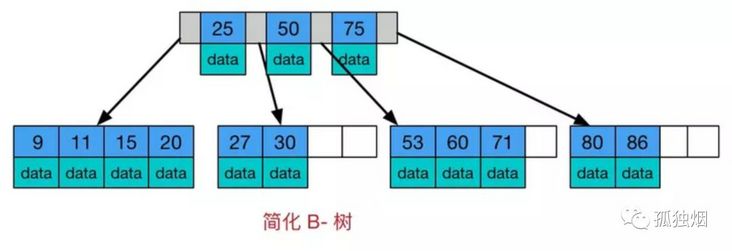
注意一下B树的两个明显特点
- 树内的每个节点都存储数据
- 叶子节点之间无指针相邻
B+树
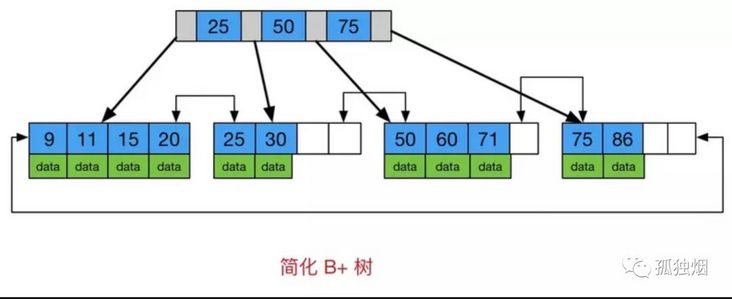
注意一下B+树的两个明显特点
- 数据只出现在叶子节点
- 所有叶子节点增加了一个链指针
针对上面的B+树和B树的特点,我们做一个总结
(1)B树的树内存储数据,因此查询单条数据的时候,B树的查询效率不固定,最好的情况是O(1)。我们可以认为在做单一数据查询的时候,使用B树平均性能更好。但是,由于B树中各节点之间没有指针相邻,因此B树不适合做一些数据遍历操作。
(2)B+树的数据只出现在叶子节点上,因此在查询单条数据的时候,查询速度非常稳定。因此,在做单一数据的查询上,其平均性能并不如B树。但是,B+树的叶子节点上有指针进行相连,因此在做数据遍历的时候,只需要对叶子节点进行遍历即可,这个特性使得B+树非常适合做范围查询。
因此,我们可以做一个推论:没准是Mysql中数据遍历操作比较多,所以用B+树作为索引结构。而Mongodb是做单一查询比较多,数据遍历操作比较少,所以用B树作为索引结构。
那么为什么Mysql做数据遍历操作多?而Mongodb做数据遍历操作少呢?
因为Mysql是关系型数据库,而Mongodb是非关系型数据。
那为什么关系型数据库,做数据遍历操作多?
而非关系型数据库,做数据遍历操作少呢?
我们继续往下看
关系型VS非关系型
假设,我们此时有两个逻辑实体:学生(Student)和班级(Class),这两个逻辑实体之间是一对多的关系。毕竟一个班级有多个学生,一个学生只能属于一个班级。
关系型数据库
我们在关系型数据库中,考虑的是用几张表来表示这二者之间的实体关系。常见的无外乎是,一对一关系,用一张表就行。一对多关系,用两张表。多对多关系,用三张表。
那这里,我们需要用两张表表示二者之间逻辑关系,如下所示
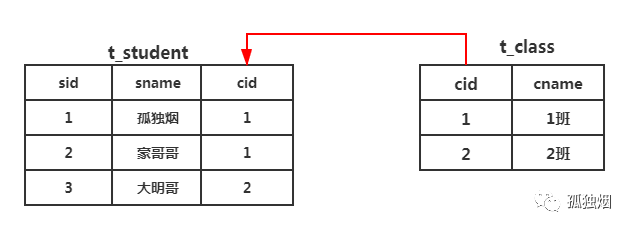
那我们,此时要查
cname为
1班的班级,有多少学生怎么办?
假设
cname这列,我们建了索引!
执行SQL,如下所示!
SELECT *FROM t_student t1, ( SELECT cid FROM t_class WHERE cname = '1班' ) t2WHERE t1.cid = t2.cid
而这,就涉及到了数据遍历操作!
因为但凡做这种关联查询,你躲不开join操作的!既然涉及到了join操作,无外乎从一个表中取一个数据,去另一个表中逐行匹配,如果索引结构是B+树,叶子节点上是有指针的,能够极大的提高这种一行一行的匹配速度!
有的人或许会抬杠说,如果我先执行
SELECT cidFROM t_classWHERE cname = '1班'
获得cid后,再去循环执行
SELECT *FROM t_studentWHERE cid = ...
就可以避开join操作呀?
对此,我想说。你确实避开了join操作,但是你数据遍历操作还是没避开。你还是需要在student的这张表的叶子节点上,一遍又一遍的遍历!
那在非关系型数据库中,我们如何查询
cname为
1班的班级,有多少学生?
非关系型数据库
有人说,你可以这么设计?也就是弄两个集合如下所示
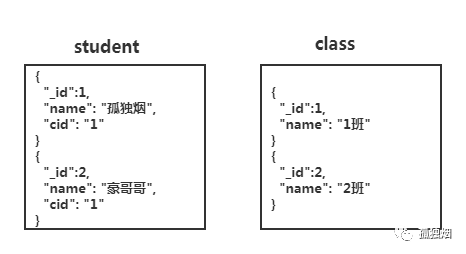
然后,执行两次查询去获得结果!一次去class集合查,获得id后再去student集合查。
确实,这么设计是可以的,我没说不行。只是不符合非关系型数据库的设计初衷。在MongoDB中,根本不推荐这么设计。虽然,Mongodb中有一个$lookup操作,可以做join查询。但是理想情况下,这个$lookup操作应该不会经常使用,如果你需要经常使用它,那么你就使用了错误的数据存储了(数据库):如果你有相关联的数据,应该使用关系型数据库(SQL)。
因此,正规的设计应该如下
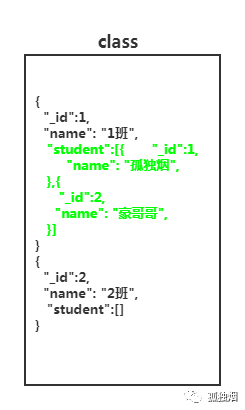
假设
name这列,我们建了索引!
我只需执行一次语句
db.class.find( { name: '1班' } )
这样就能查询出自己想要的结果。
而这,就是一种单一数据查询!毕竟你不需要去逐行匹配,不涉及遍历操作,幸运的情况下,有可能一次IO就能够得到你想要的结果。
因此,由于关系型数据库和非关系型数据的设计方式上的不同。导致在关系型数据中,遍历操作比较常见,因此采用B+树作为索引,比较合适。而在非关系型数据库中,单一查询比较常见,因此采用B树作为索引,比较合适。
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于数据库的相关知识,也可关注golang学习网公众号。
-
374 收藏
-
499 收藏
-
384 收藏
-
323 收藏
-
184 收藏
-
数据库 · MySQL | 1天前 | MySQL · 权限管理 · 备份 · mysqldump · 数据库安全 · 最小权限 mysqldump备份账号 MySQL角色 partial_revokes 备份权限413 收藏
-
278 收藏
-
数据库 · MySQL | 2天前 | MySQL · JSON · 索引 · 数据库 · 查询优化 · 生成列 · json_extract 索引优化 列表筛选 生成列 MySQL JSON JSON索引351 收藏
-
数据库 · MySQL | 4天前 | MySQL · 认证 · MySQL 8.4 · 数据库升级 · caching_sha2_password mysql_native_password 账号认证 MySQL 8.4 升级迁移236 收藏
-
471 收藏
-
数据库 · MySQL | 5天前 | MySQL · 数据库 · SQL · ON DUPLICATE KEY UPDATE · VALUES · 行别名 · MySQL VALUES() 弃用 ON DUPLICATE KEY UPDATE MySQL 行别名 INSERT AS new MySQL upsert INSERT SELECT117 收藏
-
数据库 · MySQL | 6天前 | MySQL · 索引 · limit · explain · sql优化 · ORDER BY · mysql order by explain limit 复合索引 filesort279 收藏
-
数据库 · MySQL | 1星期前 | 并发 · MySQL · InnoDB · update · 库存扣减 · innodb MySQL 库存扣减 条件 UPDATE 防超卖 affected rows470 收藏
-
421 收藏
-
189 收藏
-
412 收藏
-
378 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习