经典案例:磁盘I/O巨高排查全过程
来源:SegmentFault
时间:2023-01-10 21:41:22 409浏览 收藏
有志者,事竟成!如果你在学习数据库,那么本文《经典案例:磁盘I/O巨高排查全过程》,就很适合你!文章讲解的知识点主要包括MySQL,若是你对本文感兴趣,或者是想搞懂其中某个知识点,就请你继续往下看吧~
作者:叶金荣,知数堂联合创始人,3306pai社区联合创始人
不管3721,先采集现场的必要信息再说。
a. 系统负载,主要是磁盘I/O的负载数据
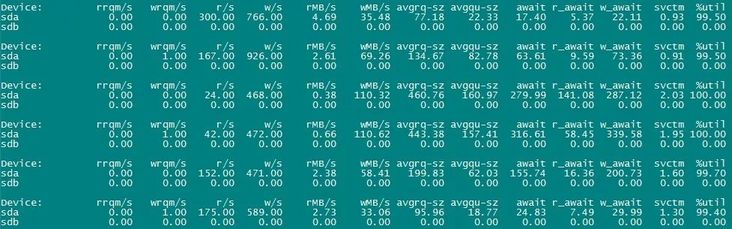
该服务器的磁盘是由6块2T SSD硬盘组成的RAID-5阵列。从上面的截图来看,I/O %util已经基本跑满了,iowait也非常高,很明显磁盘I/O压力太大了。那就再查查什么原因导致的这么高压力。
b. 活跃事务列表
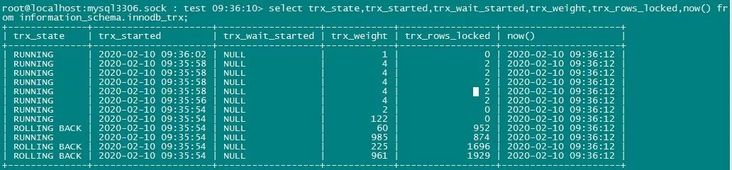
可以看到,有几个活跃的事务代价很高,锁定了很多行。其中有两个因为太久超时被回滚了。

再看一次活跃事务列表,发现有个事务锁定的行更多了,说明活跃业务SQL的效率不太好,需要进行优化。这个算是原因之一,先记下。
c. 查看InnoDB状态
执行
SHOW ENGINE INNODB STATUS\G查看InnoDB状态,这里只展示了几个比较关键的地方:
... 0x7f8f700e9700 INNODB MONITOR OUTPUT ... LATEST DETECTED DEADLOCK ------------------------ ... *** (2) TRANSACTION: TRANSACTION 52970892097, ACTIVE 1 sec starting index read mysql tables in use 2, locked 2 80249 lock struct(s), heap size 9691344, 351414 row lock(s), undo log entries 30005 ### 这里很明显,发生死锁的事务之一持有很多行锁,需要优化SQL ... update a inner join b on a.uid=b.uid set a.kid=if(b.okid=0,b.kid,b.okid),a.aid=b.aid where a.date='2020-02-10' ... TRANSACTIONS ------------ Trx id counter 52971738624 Purge done for trx's n:o
d. 查看MySQL的线程状态*
+---------+------+--------------+--------------------- | Command | Time | State | Info | +---------+------+--------------+--------------------- | Query | 1 | update | insert xxx | Query | 0 | updating | update xxx | Query | 0 | updating | update xxx | Query | 0 | updating | update xxx | Query | 0 | updating | update xxx +---------+------+--------------+---------------------
可以看到几个事务都处于updating状态。意思是正在扫描数据并准备更新,肉眼可见这些事务状态时,一般是因为系统负载比较高,所以事务执行起来慢;或者该事务正等待行锁释放。
2. 问题分析及优化工作
分析上面的各种现场信息,我们可以得到以下几点结论:
a. 磁盘I/O压力很大。先把阵列卡的cache策略改成WB,不过由于已经是SSD盘,这个作用并不大,只能申请更换成RAID-10阵列的新机器了,还需等待资源调配。
b. 需要优化活跃SQL,降低加锁代价
[root@yejr.me]> desc select * from a inner join b on a.uid=b.uid where a.date='2020-02-10'; +-------+--------+------+---------+----------+-------+----------+-----------------------+ | table | type | key | key_len | ref | rows | filtered | Extra | +-------+--------+------+---------+----------+-------+----------+-----------------------+ | a | ref | date | 3 | const | 95890 | 100.00 | NULL | | b | eq_ref | uid | 4 | db.a.uid | 1 | 100.00 | Using index condition | +-------+--------+------+---------+----------+-------+----------+-----------------------+ [root@yejr.me]> select count(*) from a inner join b on a.uid=b.uid where a.date='2020-02-10'; +----------+ | count(*) | +----------+ | 40435 | +----------+ 1 row in set (0.22 sec)
执行计划看起来虽然能用到索引,但效率还是不高。检查了下,发现a表的uid列竟然没加索引,我汗。。。
c. InnoDB的redo log checkpoint延迟比较大,有2249MB之巨。先检查redo log的设置:
innodb_log_file_size = 2G innodb_log_files_in_group = 2
这个问题就大了,redo log明显太小,等待被checkpoint的redo都超过2G了,那肯定要疯狂刷脏页,所以磁盘I/O的写入才那么高,I/O %util和iowait也很高。
建议把redo log size调整成4G、3组。
innodb_log_file_size = 4Ginnodb_log_files_in_group = 2
此外,也顺便检查了InnoDB其他几个重要选项
innodb_thread_concurrency = 0 # 建议维持设置0不变 innodb_max_dirty_pages_pct = 50 # 由于这个实例每秒写入量较大,建议先调整到75,降低刷脏页的频率, # 顺便缓解redo log checkpoint的压力。 # 在本案例,最后我们把这个值调整到了90。
特别提醒
从MySQL 5.6版本起,修改redo log设置后,实例重启时会自动完成redo log的再次初始化,不过前提是要先干净关闭实例。因此建议在第一次关闭时,修改以下两个选项:
innodb_max_dirty_pages_pct = 0 innodb_fast_shutdown = 0
并且,再加上一个新选项,防止实例启动后,会有外部应用连接进来继续写数据:
skip-networking
在确保所有脏页(上面看到的Modified db pages为0)都刷盘完毕后,并且redo log也都checkpoint完毕(上面看到的Log sequence number和Last checkpoint at**值相等),此时才能放心的修改 innodb_log_file_size 选项配置并重启。确认生效后再关闭 skip-networking 选项对业务提供服务。
经过一番优化调整后,再来看下服务器和数据库的负载。
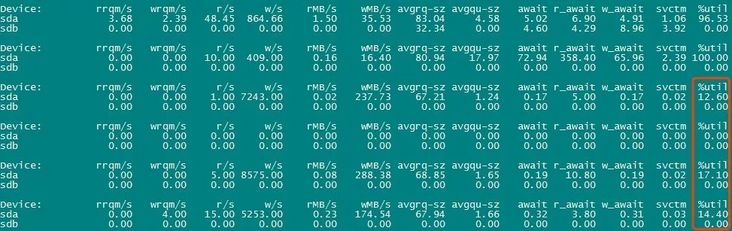
可以看到,服务器的磁盘I/O压力再也不会那么大了,数据库中也不会频繁出现大量行锁等待或回滚的事务了。
[root@yejr.me]> SHOW ENGINE INNODB STATUS\g Log sequence number 565749866400449 Log flushed up to 565749866400449 Pages flushed up to 565749866318224 Last checkpoint at 565749866315740 [root@yejr.me]> SHOW ENGINE INNODB STATUS\g Log sequence number 565749866414660 Log flushed up to 565749866400449 Pages flushed up to 565749866320827 Last checkpoint at 565749866315740 [root@yejr.me]> SHOW ENGINE INNODB STATUS\g Log sequence number 565749866414660 Log flushed up to 565749866414660 Pages flushed up to 565749866322135 Last checkpoint at 565749866315740 [root@yejr.me]> select (565749866400449-565749866315740)/1024; +----------------------------------------+ | (565749866400449-565749866315740)/1024 | +----------------------------------------+ | 82.7236 | +----------------------------------------+ 1 row in set (0.00 sec) [root@yejr.me]> select (565749866414660-565749866315740)/1024; +----------------------------------------+ | (565749866414660-565749866315740)/1024 | +----------------------------------------+ | 96.6016 | +----------------------------------------+
很明显,redo log checkpoint lag几乎没有了。
完美搞定!
写在最后
遇到数据库性能瓶颈,负载飚高这类问题,我们只需要根据一套完整的方法论 优化系列:实例解析MySQL性能瓶颈排查定位,根据现场的各种蛛丝马迹,逐一进行分析,基本上都是能找出来问题的原因的。本案其实并不难,就是按照这套方法来做的,最后连perf top都没用上就很快能大致确定问题原因了。
延伸阅读
理论要掌握,实操不能落!以上关于《经典案例:磁盘I/O巨高排查全过程》的详细介绍,大家都掌握了吧!如果想要继续提升自己的能力,那么就来关注golang学习网公众号吧!
-
374 收藏
-
499 收藏
-
384 收藏
-
184 收藏
-
265 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 激动的钢笔
- 太详细了,mark,感谢大佬的这篇技术贴,我会继续支持!
- 2023-03-01 11:17:34
-
- 等待的硬币
- 这篇文章真是及时雨啊,博主加油!
- 2023-02-11 18:15:49
-
- 热情的跳跳糖
- 这篇博文真是及时雨啊,太细致了,感谢大佬分享,已加入收藏夹了,关注老哥了!希望老哥能多写数据库相关的文章。
- 2023-02-06 17:34:57
-
- 热情的春天
- 赞 ??,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢博主分享文章!
- 2023-02-02 22:33:59
-
- 玩命的金针菇
- 写的不错,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢大佬分享文章内容!
- 2023-01-22 04:20:28
-
- 乐观的美女
- 这篇博文真是及时雨啊,好细啊,太给力了,已收藏,关注老哥了!希望老哥能多写数据库相关的文章。
- 2023-01-12 22:26:17